转载请注明出处:勿在浮沙筑高台http://blog.csdn.net/luoshixian099/article/details/51714346
1.概念
AdaBoost是一种级联算法模型,即把几个弱分类器级联到一起去处理同一个分类问题。也就是“三个臭皮匠顶一个诸葛亮”的道理。例如一个专家作出的判定往往没有几个专家一起作出的判定更准确。一种情况:如果每个专家都仅有一票的权利,采用投票机制的方法属于uniform形式;另一种情况是分配给每个专家的票数不一致则属于linear形式。AdaBoost即属于第二种的行式,同时尽量使得每个专家考虑的则重点不同,最终给出投票结果更可信。
2.原理描述
给定一个数据集D(x,y),x表述特征,y对应标签值。在某种分类器上训练出模型
下图中
w(1)n 表示第一轮训练样本的权重向量,y1(x) 表示第一轮训练出的模型,然后根据y1(x) 对样本数据分类情况,调整w(2)n ,继续训练出y2(x) ….
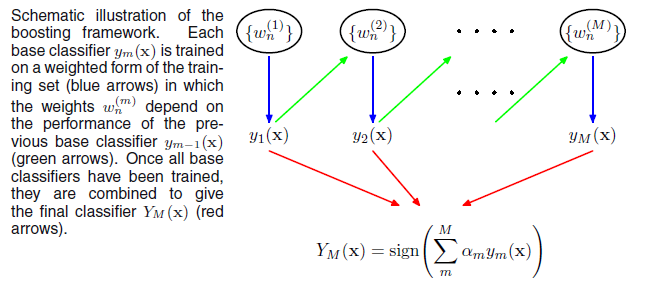
数学语言描述
- 训练数据集
D(x,y),xi∈Rn 表示数据特征,yi∈{−1,1} 表示对应的标签值,共N个样本点。分类器Gm 分类误差率定义为ϵm=∑Ni=1wmiI(Gm(xi)≠yi)∑Ni=1wmi ; - 第一轮训练数据的权值:
w1i=1N ,i=1,…N,即同等对待每个样本点。学习出弱分类器G1(x) 。计算出G1(x) 的分类误差率ϵ1=∑Ni=1w1iI(G1(xi)≠yi)∑Ni=1w1i ;提高被G1(x) 误分类样本点的权值,降低被正确分类样本点的权值。
现在讨论一下具体提高多少权值或者降低多少权值。AdaBoost的想法是让分类器
G1(x) 在调整权重后的w2i 上表现出乱猜的效果。即∑Ni=1w2iI(G1(xi)≠yi)∑Ni=1w2i=12 。由于每一轮训练的目标函数都是最小化误差函数,所以第二轮训练出的分类器与上一轮会不同。
具体的调整权值方法:
被错误分类的样本点:w2i=w1i∗1−ϵ1ϵ1−−−−√ ;被正确分类的点:w2i=w1i÷1−ϵ1ϵ1−−−−√ ;
两种情况写在一起为w2i=w1i∗exp(−yiG1(xi)log1−ϵ1ϵ1−−−−√)
由于ϵ1≤12 ,则1−ϵ1ϵ1−−−−√≥1 ,所以被错分的样本点权值会升高,相反,被正确分类的样本点权值会降低。
3.得到第二轮的训练样本权值
4.组合上述M个分类器:
3.算法步骤
- 初始化权重
w1i=1N ,i=1,2,…,N - For m=1,…,M:
(a)训练分类器Gm(x) 以最小化加权误差函数作为目标函数ϵm=∑Ni=1wmiI(Gm(xi)≠yi)∑Ni=1wmi
(b)根据分类器误差ϵm ,计算此分类器的权重αm=log1−ϵmϵm−−−−√
(c)更新下一轮样本权重wm+1,i=wmi∗exp(−yiGm(xi)log1−ϵ1ϵ1−−−−√) ;由于αm=log1−ϵmϵm−−−−√ ,所以可以记为:wm+1,i=wmi∗exp(−αmyiGm(xi)) - 联合上述M个分类器得:
G(x)=sign(∑m=1MαmGm(x))
4.Adaboost与前向分布算法
加法模型
上述位置参数有2M个,可以采用前向分布算法,从前向后每一步只学习一个基函数及其系数逐步逼近上述目标函数。每一个只需优化下述损失函数:
前向分步算法
- 初始化
f0(x)=0 对m=1,2…M
(a)极小化损失:(βm,γm)=minβ,γ∑i=1Nexp(−yi(fm−1(xi)+βb(xi,γ)))
(b)更新:fm(x)=fm−1(x)+βmb(x;γm) 得到加法模型
f(x)=∑Mm=1βmb(x,γm)
下面证明Adaboost是前向分布算法的一个特例,基函数为分类器,误差函数为指数误差函数。
指数误差函数定义:
假设经过m-1轮迭代前向分布算法已经得到
定义
固定
现在考虑参数
即
对应到AdaBoost的每个分类器的权重
考虑Adaboost最后的指数误差损失函数:
Reference:
统计学习方法-李航
PRML-M.BISHOP
http://www.loyhome.com/≪统计学习精要the-elements-of-statistical-learning≫课堂笔记(十四)/