楔子
前面提到boosting算法为一类算法,这一类算法框架分为3步:1、训练一个弱分类;2、根据分类结果调整样本权重;3、最后决策时,根据弱模型的表现来决定其话语权。
那么这里面就有2个关键点:
1、如何调整样本权重;
2、如何根据弱模型的表现来决定其话语权。
算法描述:
adaboost里的样本权重和话语权
事实上,能够将这两个问题的解决方案有机地糅合在一起、正是 AdaBoost 的巧妙之处之一。
如何调整样本权重,一个弱分类器得到一个错误分类率e > 0.5, 我们调整样本权重是分类错误率等于0.5,用这个样本权重用于下一个分类器,这个这两个分类器就不会强相关,这个就是调整样本权重的主要思想。
分类错误样本权重乘以d倍,分类正确样本权重处理d,得到e*d = (1-e)/d =====> d^2 = (1-e)/e
我们定义该分类器的话语权为:alpha = ln(d) = 0.5*ln (1-e)/e,话语权是随着错误率的增大而减小的。
事实上,能够将这两个问题的解决方案有机地糅合在一起、正是 AdaBoost 的巧妙之处之一。
实际的样本权重是归一化处理过的:
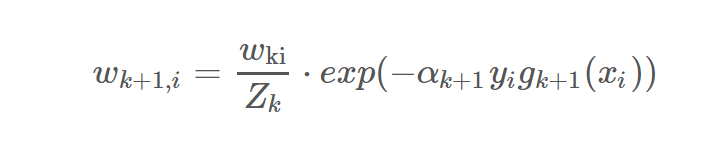
算法描述

AdaBoost的实现:
实现比较简单,首先你的分类器需要支持样本权重,然后按照序列调用你的分类器就行了,每次把计算好的样本权重传进去。
class AdaBoost:
# 弱分类器字典,如果想要测试新的弱分类器的话、只需将其加入该字典即可
_weak_clf = {
"SKMNB": SKMultinomialNB,
"SKGNB": SKGaussianNB,
"SKTree": SKTree,
"MNB": MultinomialNB,
"GNB": GaussianNB,
"ID3": ID3Tree,
"C45": C45Tree,
"Cart": CartTree
}
"""
AdaBoost框架的朴素实现
使用的弱分类器需要有如下两个方法:
1) 'fit' 方法,它需要支持输入样本权重
2) 'predict' 方法, 它用于返回预测的类别向量
"""
def __init__(self):
# 初始化结构
# self._clf:记录弱分类器名称的变量
# self._clfs:记录弱分类器的列表
# self._clfs_weights:记录弱分类器“话语权”的列表
self._clf, self._clfs, self._clfs_weights = "", [], []
def fit(self, x, y, sample_weight=None, clf=None, epoch=10, eps=1e-12, **kwargs):
# 默认使用10个CART决策树桩作为弱分类器
if clf is None or AdaBoost._weak_clf[clf] is None:
clf = "Cart"
kwargs = {"max_depth": 1}
# 当前使用的分类器
self._clf = clf
# 样本权重,注意是归一化后的样本权重,默认样本权重为[1/N,1/N,...]
if sample_weight is None:
sample_weight = np.ones(len(y)) / len(y)
else:
sample_weight = np.array(sample_weight)
# AdaBoost算法的主循环,epoch为迭代次数
for _ in range(epoch):
# 根据样本权重训练弱分类器
tmp_clf = AdaBoost._weak_clf[clf](**kwargs)
tmp_clf.fit(x, y, sample_weight)
# 调用弱分类器的predict方法进行预测
y_pred = tmp_clf.predict(x)
# 计算加权错误率;考虑到数值稳定性,在边值情况加了一个小的常数
# 点乘是行*列
em = min(max((y_pred != y).dot(self._sample_weight[:, None])[0], eps), 1 - eps)
# 计算该弱分类器的“话语权”,化简了一下
am = 0.5 * log(1 / em - 1)
# 更新样本权重并利用deepcopy将该弱分类器记录在列表中
sample_weight *= np.exp(-am * y * y_pred)
sample_weight /= np.sum(sample_weight)
# 记录分类器和话语权
self._clfs.append(deepcopy(tmp_clf))
self._clfs_weights.append(am)
def predict(self, x):
x = np.atleast_2d(x)
# 保存结果
rs = np.zeros(len(x))
# 根据各个弱分类器的“话语权”进行决策
for clf, am in zip(self._clfs, self._clfs_weights):
rs += am * clf.predict(x)
# 将预测值大于0的判为类别1,小于0的判为类别-1
return np.sign(rs)
数学基础(了解)
AdaBoost 算法是前向分步算法的特例,AdaBoost 模型等价于损失函数为指数函数的加法模型。
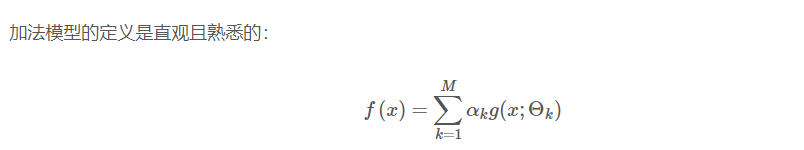
所谓的前向分步算法,就是从前向后、一步一步地学习加法模型中的每一个基函数及其权重而非将f(x)作为一个整体来训练,这也正是 AdaBoost 的思想。