简介
上一篇具体按照第一个链接,介绍了训练强分类器的过程;
本篇文章,mask另一段代码,并用强分类器进行分类,验证分类结果。
1.创建数据集和标签
def create_dataMat():
dataMat = mat([[0],[1],[2],[3],[4],[5]]) #x
labels = [1, 1, -1, -1, 1, -1] #y
return dataMat, labels
2.使用单层决策树对数据进行分类
dataMatirx:要分类的数据
dimen:维度
threshVal:阈值
threshIneq:方法有两种,‘lt’=lower than,‘gt’=greater than
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt': #按照大于或小于关系分类
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #方法‘lt’,如果希望大于阈值的是1,则小于阈值的部分置为-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 #方法‘gt’,如果希望大于阈值的是-1,则小于阈值的部分置为1
return retArray
3.建立最佳单层决策树,即弱分类器
与上一篇文章不同,本次采用的切分点不再是相邻两个点均值,而是以最小值为基础,阈值=最小值+迭代数*步长
函数返回弱分类器的:最好的树、错误率、分类结果
def buildStump(dataMat,labels,D):
labelMat = mat(labels).T #转置为列向量
m,n = shape(dataMat) # m为数据个数,n为每条数据含有的样本数(也就是特征)
numSteps = 10.0
bestStump = {} #存贮决策树
bestClasEst = mat(zeros((m,1))) # 初始化为全部分类错误,即分类器为[[0],[0],[0],...]
minError = inf #最小错误,初始化为无穷大
for i in range(n): #遍历所有的特征
rangeMin = dataMat[:,i].min() # 找这一列特征的最小值
rangeMax = dataMat[:,i].max() # 找这一列特征的最大值
stepSize = (rangeMax-rangeMin)/numSteps #步长
for j in range(-1,int(numSteps)+1): #将阈值起始与终止设置在该特征取值的范围之外
for inequal in ['lt', 'gt']: #取less than和greater than,即:大于阈值是1还是小于阈值是1
threshVal = (rangeMin + float(j) * stepSize) # 阈值设为最小值+第j个步长
predictedVals = stumpClassify(dataMat,i,threshVal,inequal) #使用单层决策树分类
errArr = mat(ones((m,1))) #1表示分类错误,0表示分类正确,初始化为全部错误
errArr[predictedVals == labelMat] = 0 #矢量比较,分类正确的置为0
weightedError = D.T*errArr #乘以系数D
if weightedError < minError: #如果错误率变小,更新最佳决策树
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
4.使用Adaboost建立强分类器,numIt表示最大迭代次数
返回弱分类器的集合,弱分类器参数包括:dimen-维度、threshVal-阈值、threshIneq-分类方法(lt、gt)、alpha-权重
把弱分类器按权重组合起来,即可得到强分类器
def adaBoostTrainDS(dataMat,classLabels,numIt=40):
weakClassArr = []
m = shape(dataMat)[0]
D = mat(ones((m,1)) / m) # 初始化权重系数D,给每个样本相同的权重,[[1/m],[1/m],[1/m],...]
aggClassEst = mat(zeros((m,1))) # 初始化每个样本的预估值为0
for i in range(numIt):
bestStump,error,classEst = buildStump(dataMat,classLabels,D) # 构建一棵单层决策树,返回最好的树,错误率和分类结果
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16))) #计算分类器权重alpha, max(error,1e-16)防止下溢出
bestStump['alpha'] = alpha #将alpha值也加入最佳树字典
weakClassArr.append(bestStump) #保存弱分类器
#print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #自然底数的指数,为了更新权重D
D = multiply(D,exp(expon)) #为下次迭代更新D
D = D/D.sum()
# 累加错误率,直到错误率为0或者到达迭代次数
aggClassEst += alpha*classEst #矢量相加
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1))) #分类正确与错误的结果
errorRate = aggErrors.sum()/m #分类错误率
#print "total error: ",errorRate
if errorRate == 0.0: break #如果分类错误率为0,结束分类
return weakClassArr #弱分类器集合
5.#使用Adaboost分类器对数据进行分类
几个弱分类器进行加权求和,根据正负情况分类,返回正数则是1,负数为-1
def adaClassify(datToClass, classifierArr):
dataMatrix = mat(datToClass) #待分类数据转化为矩阵
m = shape(dataMatrix)[0] #待分类数据的个数
aggClassEst = mat(zeros((m,1))) #所有待分类数据的分类,全部初始化为正类
#结果等于几个弱分类器的加权求和
for i in range(len(classifierArr)): #使用弱分类器,均为矢量运算
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'],classifierArr[i]['thresh'],classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha']*classEst # 将弱分类器结果加权求和
print(aggClassEst)
return sign(aggClassEst) #根据结果的正负情况得到分类输出,1表示正号,-1表示负号
6.调用函数,训练分类器,以及使用分类器进行分类
if __name__ == '__main__':
#1.训练分类器
dataMat, labels = create_dataMat()
weakClassArr = adaBoostTrainDS(dataMat, labels)
#2.测试数据
for i in range(6):
res = adaClassify([i], weakClassArr)
print('data: %d, class: %2d' % (i, res))
假设数据集和标签为:
dataMat = mat([[0],[1],[2],[3],[4],[5],[6],[7]])
labels = [1, 1, -1, -1, 1, -1,1,1]
例1:把数据集设置为6个,即0-5,验证分类正确性
数据集:
dataMat = mat([[0],[1],[2],[3],[4],[5]])
labels = [1, 1, -1, -1, 1, -1]
预测结果与原标签一致,分类正确:
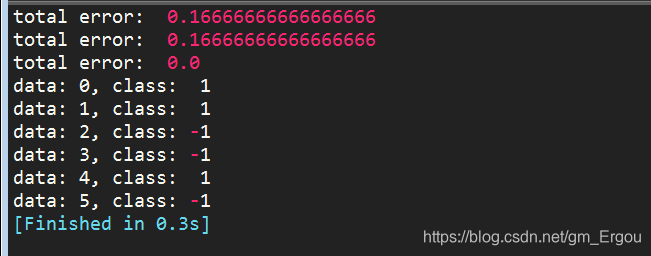
例2:把数据集增加到8个,即0-7,再次验证分类正确性
数据集:
dataMat = mat([[0],[1],[2],[3],[4],[5],[6],[7]])
labels = [1, 1, -1, -1, 1, -1,1,1]
结果:
样本’5’所对应的标签为-1,下面的分类结果为-1,正确!
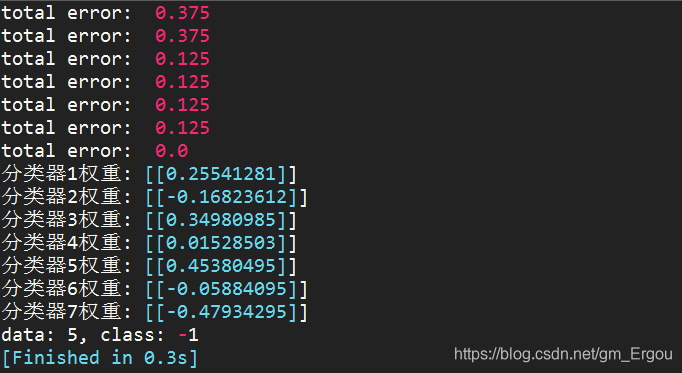
由上可见,训练经过了7轮迭代才把错误率降到最低,即得到了7个弱分类器;
把它们按照上面的比例加权求和,得到的结果就是预测的结果。