AdaBoost实现
前两篇文章针对AdaBoost的伪代码实现步骤进行了讨论,也对关键步骤的更新方法进行了推导,脑海里已经基本有了整体框架,有了基本框架,代码的含义就清晰易懂了,下面看看AdaBoost是如何串行生成一系列基学习器的.
导入数据
from numpy import *
import matplotlib.pyplot as plt
def loadSimpData():#二维数据点,二分类
datMat = [[ 1. , 2.1],
[ 2. , 1.1],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]]
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
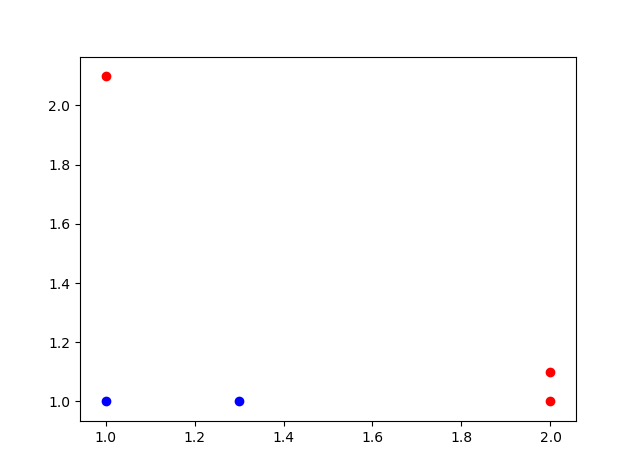
几个简单的二维数据点,对应的标签值属于二分类{-1,1}
数据可视化
def show_dataSet(dataMat,classLabels):
for i in range(len(dataMat)):
if classLabels[i] == 1.0:
plt.scatter(dataMat[i][0],dataMat[i][1],c='r',marker = 'o')
else:
plt.scatter(dataMat[i][0],dataMat[i][1],c='b',marker = 'o')
plt.show()
简单画图看一下几个数据点的分布情况:
根据维度与阈值调整标签
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data
retArray = ones((shape(dataMatrix)[0],1))#自定义一个5x1的全部为1的列表作为初始标签
if threshIneq == 'lt':#根据维度和阈值,调整标签值
retArray[dataMatrix[:,dimen] < threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 改为了 retArray[dataMatrix[:,dimen] < threshVal] = -1.0与书中不同,这样修改是为了使界限更加清晰,应为有等号时分割界限会和样本点重合,可视化效果不是太好.
选择最优划分方式
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T#转换数据为矩阵形式
m,n = shape(dataMatrix)#提取维度
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))#初始化最优划分选择
minError = inf #初始化最小误差为无穷大
for i in range(n):#遍历样本集
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps#阈值改变的步长,类似梯度法的学习率
for j in range(-1,int(numSteps)+1):#比较不同阈值划分的分类错误率
for inequal in ['lt', 'gt']: #lt,gt为不同的标签适应
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#根据阈值修改标签
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr #计算错误率
print ("划分维度: %d, 阈值: %.2f, 标签方法: %s, 错误率 %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError:#添加最低错误率时对应的维度,阈值,划分方式
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['划分维度:'] = i
bestStump['阈值:'] = threshVal
bestStump['标签方法:'] = inequal
# print('bestStump is ',bestStump)
return bestStump,minError,bestClasEst
这一步是针对单个学习器而言,通过最大值与最小值构造阈值变化步长,针对不同的维度选择,阈值选择,标签划分方式,分别计算对应划分方式的预测错误率,选择当前错误率最低的划分方式,依次放到beststum中,用于之后构建最佳分类边界.
AdaBoost串行实现
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #初始化权值,1/样本数
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#寻找本次最优划分方式
print ("D:",D.T)
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#学习器重要性度量α计算
bestStump['学习器权数α:'] = alpha
weakClassArr.append(bestStump) #添加最优划分
print ("classEst: ",classEst.T)
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #规范化分布计算,分母zm
D = multiply(D,exp(expon))
D = D/D.sum()#更新权数D
#根据预测分类与权数,累加样本预测值
aggClassEst += alpha*classEst
print ("aggClassEst: ",aggClassEst.T)
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m#计算总分类器预测错误率
print ("total error: ",errorRate)
if errorRate == 0.0: break
return weakClassArr,aggClassEst
这一步主要参考伪代码很容易理解,参考之前的推导,这里思路很清晰,1)初始化权值分布 -> 2)迭代生成基学习器,更新α,权值D,计算总体错误率 -> 3)直到总体错误率为0时,停止迭代过程,每一步更新的代码对照之前的公式也很容易读懂,至此,Adaboost的生成过程就结束了.
分类边界可视化
def show_classifier_region(classfierarray):
for i in range(len(dataMat)):
if classLabels[i] == 1.0:
plt.scatter(dataMat[i][0],dataMat[i][1],c='r',marker = 'o')
else:
plt.scatter(dataMat[i][0],dataMat[i][1],c='b',marker = 'o')
x = arange(0.5,2.3,0.01)
y = arange(0.5,2.3,0.01)
for i in range(3):
if int(classfierarray[i]['划分维度:']) == 0:
for j in y:
plt.scatter(classfierarray[i]['阈值:'],j,c='k',alpha = 0.5,s=1)
elif int(classfierarray[i]['划分维度:']) == 1:
for j in x:
plt.scatter(j,classfierarray[i]['阈值:'],c='k',alpha = 0.5,s=1)
plt.show()
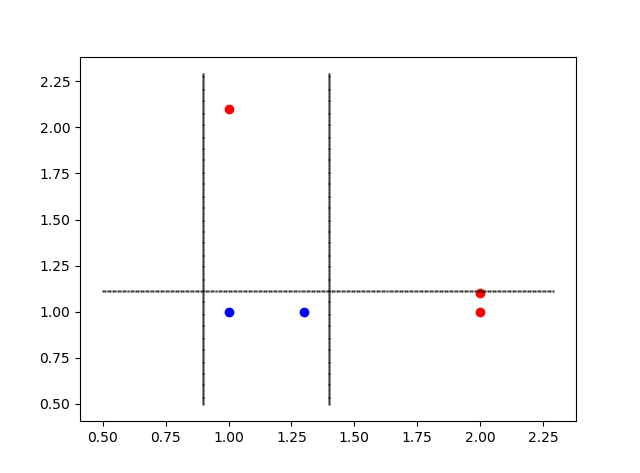
针对每次最优划分方式,在图中画出对应的分类边界.
[{'划分维度:': 0, '阈值:': 1.3999999999999999, '标签方法:': 'lt', '学习器权数α:': 0.6931471805599453},
{'划分维度:': 0, '阈值:': 0.90000000000000002, '标签方法:': 'lt', '学习器权数α:': 0.5493061443340548},
{'划分维度:': 1, '阈值:': 1.1100000000000001, '标签方法:': 'lt', '学习器权数α:': 0.8047189562170503}]
由于数据点比较少,所以只需要三个基学习器,就可以达到100%精度,上面三条记录就是每个学习器的划分参数
主函数
if __name__ == "__main__":
dataMat,classLabels = loadSimpData()
D = mat(ones((5,1))/5)
print(buildStump(dataMat,classLabels,D))
weakClassArr,aggClassEst = adaBoostTrainDS(dataMat,classLabels,9)
print([i for i in weakClassArr])
show_dataSet(dataMat,classLabels)
show_classifier_region(weakClassArr)
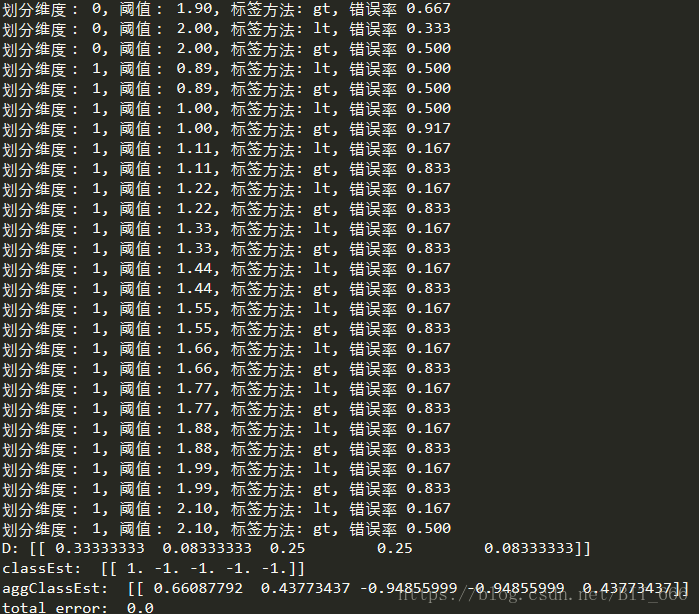
将上述函数依次添加到AdaBoost.py中,运行主函数即可得到上述结果,这里只显示了一部分,可以看到最终分类器的total error为0.0,从而达到停止条件,如果只想出结果,不需要这些步骤,可以相应的去掉print语句即可.
根据最优选择图解AdaBoost
1)第一条划分界限
{'划分维度:': 0, '阈值:': 1.3999999999999999, '标签方法:': 'lt', '学习器权数α:': 0.6931471805599453}
维度为0,对应x轴,阈值为1.3999,所以分类边界为x = 1.3999,标签方法为lt,即小于阈值的数据判定为-1,大与阈值的判定为+1,如图所示.
2)第二条划分界限
{'划分维度:': 0, '阈值:': 0.90000000000000002, '标签方法:': 'lt', '学习器权数α:': 0.5493061443340548}
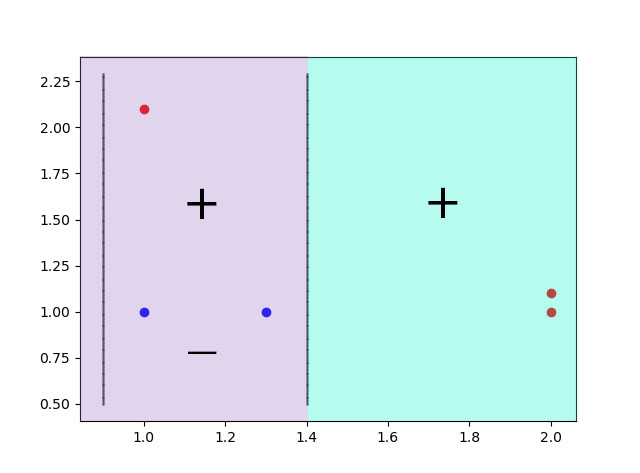
维度为0,对应x轴,阈值为0.9,所以分类边界为x = 0.9,标签方法仍为lt,即小于阈值的数据判定为-1,大与阈值的判定为+1,如图所示.这个时候0.9-1.39之间的数据点分类还不正确,因此还需继续迭代.
3)第三条划分界限
{'划分维度:': 1, '阈值:': 1.1100000000000001, '标签方法:': 'lt', '学习器权数α:': 0.8047189562170503}
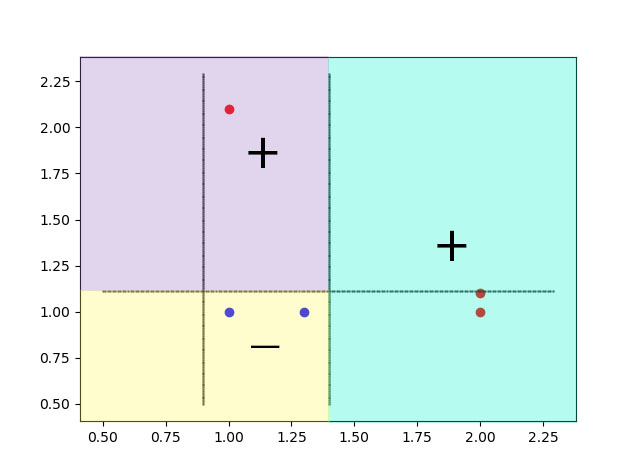
维度更改为1,对应y轴,阈值为1.11,所以分类边界为y=1.11,标签方法仍为lt,即小于阈值的数据判定为-1,大与阈值的判定为+1,所以对应边界上面部分判断为正,下面判断为负,对于最右边的两个红点,根据投票法,两正一负为正,左上角的红点,两正一负为正,左下的两个蓝点,两负一正为负,从而全部样本预测正确,结束学习器生成过程,完成迭代.
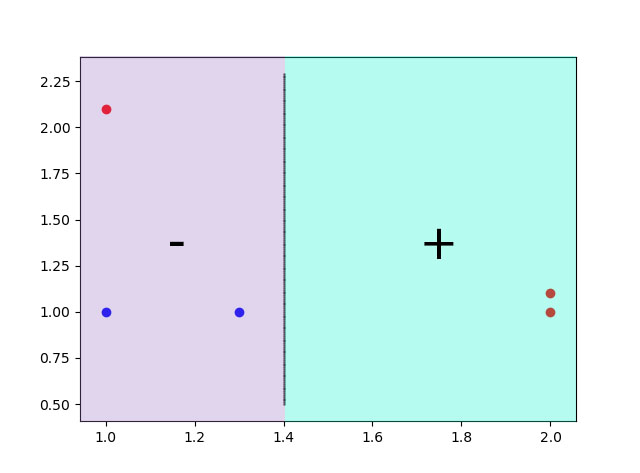
4)总分类边界
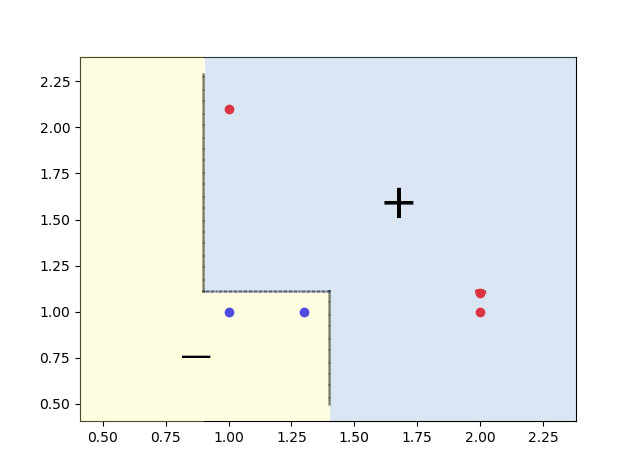
根据三条划分线以及对应的标签规则,我们得到了最终的分类边界,如果存在更多的数据点,则可能需要生成更多的基学习器,而分类边界也对应更多的直线.
总结:
针对更复杂的数据点,AdaBoost将生成更多的学习器,分类边界也更加复杂,但是总体的泛化错误率会随之降低,AdaBoost的大致过程就是这样了,总的来说,集成学习就是人多力量大,虽然一个学习器的效果不佳,但是大家的结果组合起来考虑,结果往往有所不同,不过在建模同时,也应该考虑模型是否存在过拟合的情形,像本文的例子,只有五个样例点,建模预测时很容易出现泛化错误率太高的情况。接下来将介绍集成学习中另一个主要成员,Bagging,它和Boosting不同,Bagging可以同时并行生成多个学习器,最终汇总结果.