机器学习——Adaboost 算法
资料来源:《MATLAB 神经网络 43 个案例分析》
Adaboost算法思想
Adaboost算法的基本思想是合并多个弱分类器来实现更为有效的分类。其主要步骤为,从样本空间中找出m组训练数据,每组训练数据的权重都是 1 m \frac1m m1 。然后用弱学习算法迭代训练,每次运算后都按照分类结果更新训练数据权重分布,对于分类失败的训练个体赋予较大权重,下一次迭代运算时更加关注这些训练个体。
弱分类器通过反复迭代得到一个分类函数序列 f 1 , f 2 . . . , f n f_1,f_2...,f_n f1,f2...,fn,给每个分类函数赋予一个权重,分类结果越好的函数赋予的权重越大,而最终的强分类函数由 F F F由若分类函数加权得到。我们使用BP神经网络作为弱分类器,反复训练神经网络预测样本输出,最终通过Adaboost算法得到由多个BP神经网络弱分类器加权得到的强分类器。
公司财务预警系统
公司财务预警系统是为了防止公司财务系统运行偏离预期目标而建立的报警系统,它通过公司的各项指标综合评价并预测公司财务状况、发展趋势和变化,为决策者科学决策提供智力支持。
本案例中共有1350 组公司财务状况数据,每组数据的输入为 10 维,代表10个指标,输出为1维,代表公司财务状况,输出为1时表示财务状况良好,为-1时表示财务状况出现问题。从中随机选取1000组数据作为训练数据,350 级数据作为测试数据。 根据数据维数,采用的 BP 经网络结构为10-6-1 ,共训练生成 10个BP神经网络弱分类器,最后用10个弱分类器组成强分类器对公司财务状况进行分类。
算法步骤
- 数据选择与初始化神经网络:首先从样本中随机选择m组训练数据,对于第一个BP神经网络,第i个样本数据的权重设置为 D 1 ( i ) = 1 m D_1(i)=\frac1m D1(i)=m1。
- 训练BP神经网络并进行预测:训练第t个BP神经网络时,用训练数据训练BP神经网络,并根使其据训练数据的输入预测输出,并得到得到预测序列 g t g_t gt的误差和 e t e_t et, e t e_t et的计算公式为:
e t = ∑ i = 1 m D t ( i ) , g t ( x i ) ≠ y ( i ) e_t=\sum_{i=1}^mD_t(i),g_t(x_i)\ne y(i) et=∑i=1mDt(i),gt(xi)=y(i)
g t ( i ) 为第 t 个神经网络对第 i 个样本的与测值, y ( i ) 为第 i 个样本的正确输出值 g_t(i)为第t个神经网络对第i个样本的与测值,y(i)为第i个样本的正确输出值 gt(i)为第t个神经网络对第i个样本的与测值,y(i)为第i个样本的正确输出值 - 计算预测序列权重:根据预测序列 g t g_t gt 的预测误差 e t e_t et计算序列的权重 a t a_t at ,计算公式为: a t = 1 2 ln ( 1 − e t e t ) a_t=\frac12 \ln(\frac{1-e_t}{e_t}) at=21ln(et1−et)
- 调整测试数据权重:根据预测序列权重 a t a_t at,调整下一轮训练样本的权重,调整公式为: D t + 1 ( i ) = D t ( i ) ∑ i D t ( i ) ∗ e − a t y ( i ) g t ( x i ) i = 1 , 2 , … , m D_{t+1}(i)=\frac{D_t(i)}{\sum_iD_t(i)}*e^{-a_ty(i)g_t(x_i)} \quad i=1,2,\dots ,m Dt+1(i)=∑iDt(i)Dt(i)∗e−aty(i)gt(xi)i=1,2,…,m 除以 ∑ i D t ( i ) 的目的是归一化 \\除以\sum_iD_t(i)的目的是归一化 除以∑iDt(i)的目的是归一化
- 加权得到强分类函数:训练T轮后得到T组弱分类函 g 1 , g 2 , . . . , g T g_1,g_2,...,g_T g1,g2,...,gT,由T组弱分类函数加权相加得到强分类函数 h ( x ) h(x) h(x):
h ( x ) = s i g n ( ∑ t = 1 T a t ∗ g t ) h(x)=sign(\sum_{t=1}^Ta_t*g_t) h(x)=sign(∑t=1Tat∗gt)
说明:
Y = sign(x) 返回与 x 大小相同的数组 Y,其中 Y 的每个元素是:
1,前提是 x 的对应元素大于 0。
0,前提是 x 的对应元素等于 0。
-1,前提是 x 的对应元素小于 0。
Matlab实现
数据及代码见文末
%% 该代码为基于BP-Adaboost的强分类器分类
%% 清空环境变量
clc
clear
%% 下载数据
load data input_train output_train input_test output_test
%% 权重初始化
[mm,nn]=size(input_train);
D(1,:)=ones(1,nn)/nn;
%% 弱分类器分类
K=10;
for i=1:K
%训练样本归一化
[inputn,inputps]=mapminmax(input_train);
[outputn,outputps]=mapminmax(output_train);
error(i)=0;
%BP神经网络构建
net=newff(inputn,outputn,6);
net.trainParam.epochs=5;
net.trainParam.lr=0.1;
net.trainParam.goal=0.00004;
%BP神经网络训练
net=train(net,inputn,outputn);
%训练数据预测
an1=sim(net,inputn);
test_simu1(i,:)=mapminmax('reverse',an1,outputps);
%测试数据预测
inputn_test =mapminmax('apply',input_test,inputps);
an=sim(net,inputn_test);
test_simu(i,:)=mapminmax('reverse',an,outputps);
%统计输出效果
kk1=find(test_simu1(i,:)>0);
kk2=find(test_simu1(i,:)<0);
aa(kk1)=1;
aa(kk2)=-1;
%统计错误样本数
for j=1:nn
if aa(j)~=output_train(j)
error(i)=error(i)+D(i,j);
end
end
%弱分类器i权重
at(i)=0.5*log((1-error(i))/error(i));
%更新D值
for j=1:nn
D(i+1,j)=D(i,j)*exp(-at(i)*aa(j)*test_simu1(i,j));
end
%D值归一化
Dsum=sum(D(i+1,:));
D(i+1,:)=D(i+1,:)/Dsum;
end
%% 强分类器分类结果
output=sign(at*test_simu);
%% 分类结果统计
%统计强分类器每类分类错误个数
kkk1=0;
kkk2=0;
for j=1:350
if output(j)==1
if output(j)~=output_test(j)
kkk1=kkk1+1;
end
end
if output(j)==-1
if output(j)~=output_test(j)
kkk2=kkk2+1;
end
end
end
disp('第一类分类错误 第二类分类错误 总错误');
% 窗口显示
disp([kkk1 kkk2 kkk1+kkk2]);
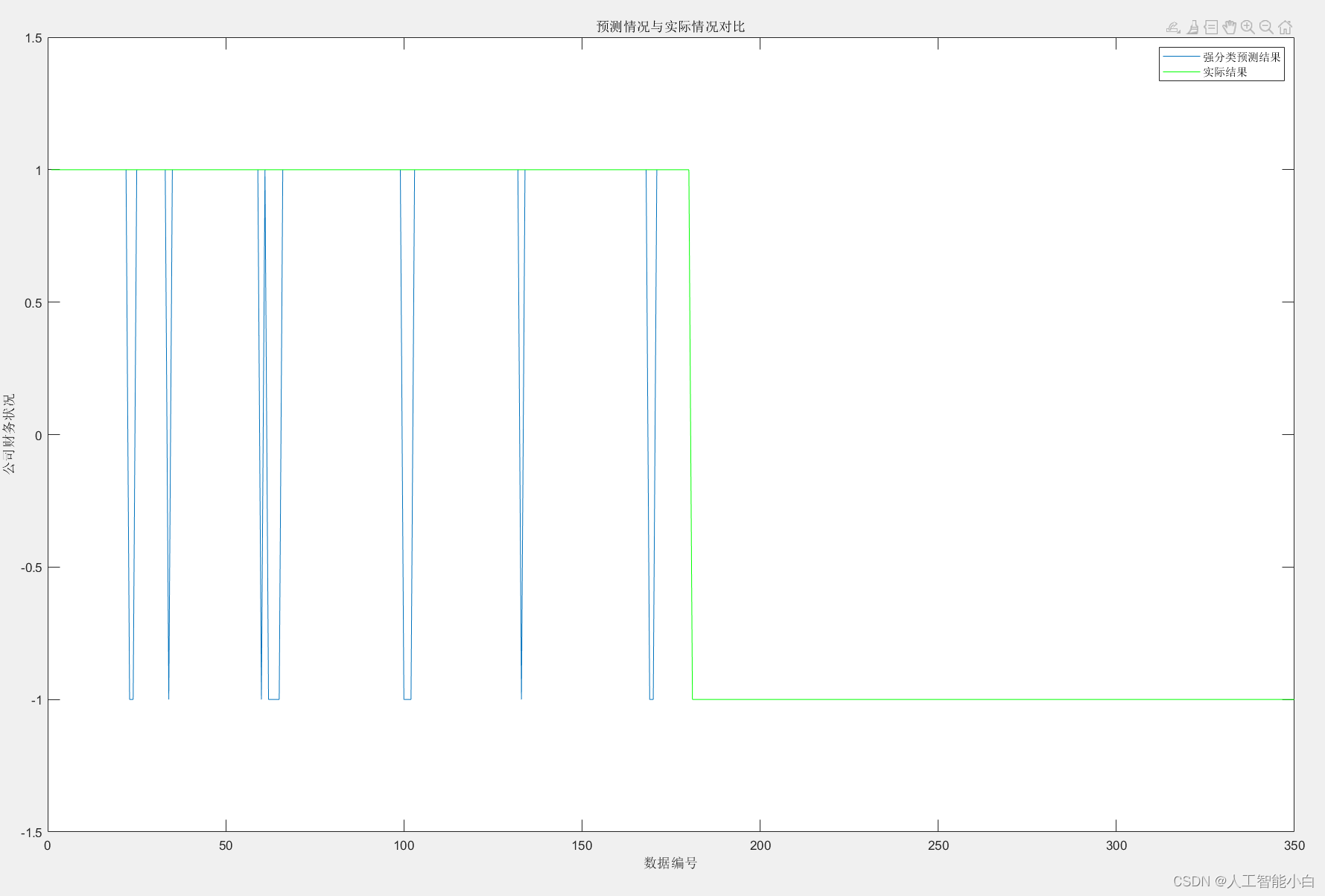
plot(output)
hold on
plot(output_test,'g')
ylim([-1.5,1.5]);
title("预测情况与实际情况对比");
ylabel('公司财务状况');
xlabel('数据编号');
legend('强分类预测结果','实际结果');
%统计弱分离器效果
for i=1:K
error1(i)=0;
kk1=find(test_simu(i,:)>0);
kk2=find(test_simu(i,:)<0);
aa(kk1)=1;
aa(kk2)=-1;
for j=1:350
if aa(j)~=output_test(j)
error1(i)=error1(i)+1;
end
end
end
disp('统计弱分类器分类效果');
error1
disp('强分类器分类误差率')
(kkk1+kkk2)/350
disp('弱分类器分类误差率')
(sum(error1)/(K*350))
运行结果如下:
第一类分类错误 第二类分类错误 总错误
0 14 14
统计弱分类器分类效果
error1 =
16 15 14 16 29 14 17 54 16 14
强分类器分类误差率
ans =
0.0400
弱分类器分类误差率
ans =
0.0586
数据及代码:data