PP-YOLO系列,均是基于百度自研PaddlePaddle深度学习框架发布的算法,2020年基于YOLOv3改进发布PP-YOLO,2021年发布PP-YOLOv2和移动端检测算法PP-PicoDet,2022年发布PP-YOLOE和PP-YOLOE-R。由于均是一个系列,所以放一起解读,方便对比前后改进地方。
PP-YOLO系列算法解读:
YOLO系列算法解读:
PP-YOLO(2020.7.23)
论文:PP-YOLO: An Effective and Efficient Implementation of Object Detector
作者:Xiang Long, Kaipeng Deng, Guanzhong Wang, Yang Zhang, Qingqing Dang, Yuan Gao, Hui Shen, Jianguo Ren, Shumin Han, Errui Ding, Shilei Wen
链接:https://arxiv.org/abs/2007.12099
代码:https://github.com/PaddlePaddle/PaddleDetection
1、算法概述
直接从论文摘要可以看出,PP-YOLO的目标是想实现一种可以直接应用于实际应用场景的检测精度和检测速度相对平衡的目标检测器,而不是提出一种新的检测模型。鉴于YOLOv3在实际中得到了广泛的应用,所以PP-YOLO的作者基于YOLOv3开发新型目标检测器。作者主要尝试结合现有的各种几乎不增加模型参数和FLOPs数量的技巧(看到这里有点像YOLOv4利用BoF改进啊!!!),以达到在保证速度几乎不变的情况下尽可能提高检测器精度的目的。由于本文中所有的实验都是基于百度的PaddlePaddle框架进行的,所以算法被命名为PP-YOLO。通过结合多种技巧,PP-YOLO在COCO上达到45.2%mAP和72.9FPS。上图:
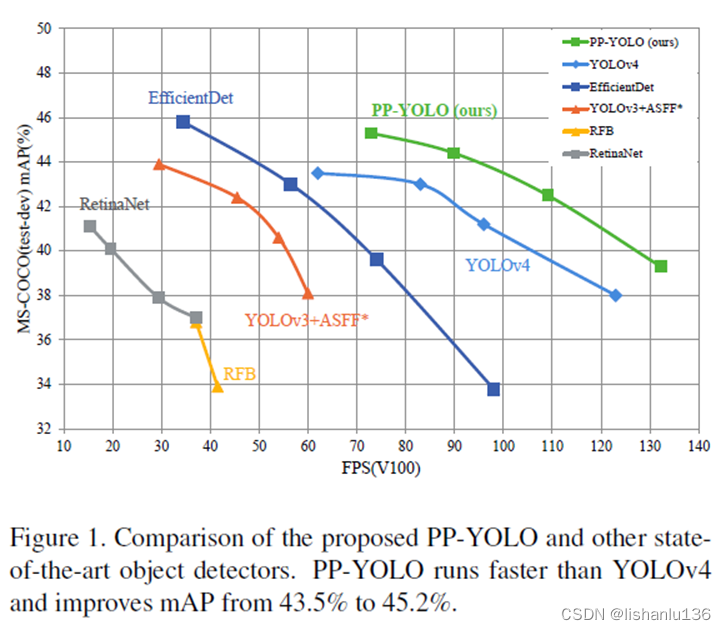
与YOLOv4不同,PP-YOLO没有探索不同的骨干网络和数据增强方法,也没有使用NAS查询超参数。对于骨干网,作者直接使用最常见的ResNet作为PP-YOLO的骨干网。对于数据增强,直接使用最基本的MixUp。一个原因是ResNet的使用更加广泛,各种深度学习框架都针对ResNet系列进行了深度优化,在实际部署中会更加方便,在实践中会有更好的推断速度。另一个原因是主干的替换和数据增强是相对独立的因素,几乎与所讨论的技巧无关。
2、PP-YOLO细节
检测算法分为backbone、neck和head三个部分,PP-YOLO基于YOLOv3进行改进,改进地方可以直接从文中网络框图看出,下面分别进行阐述:
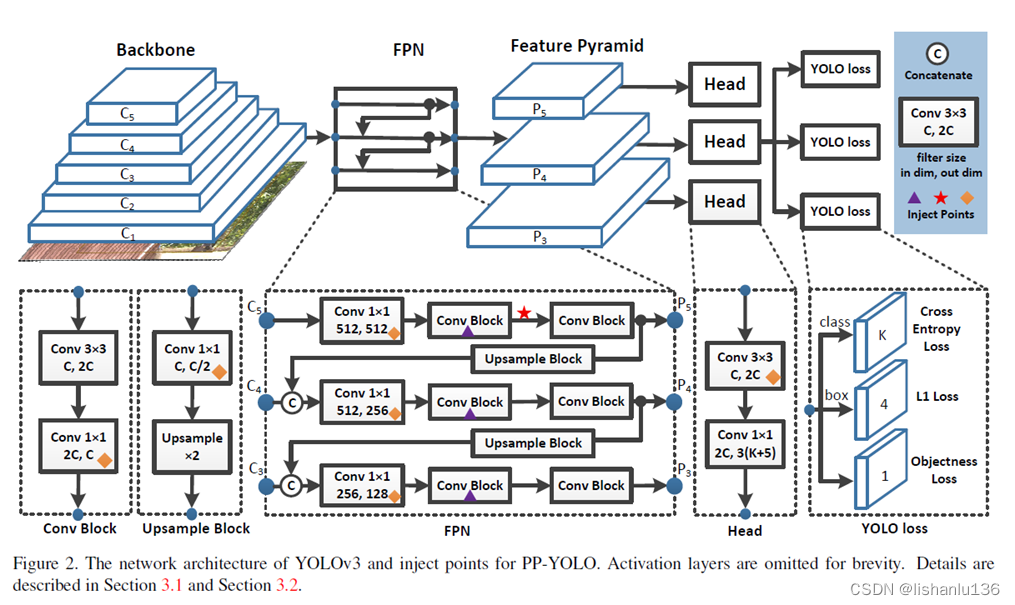
从图中可以看出,主要改进点在neck和head部分。有紫色三角块,黄色方块和红色星星作为改进插入点。
紫色三角块代表DropBlock
黄色方块代表CoordConv
红色星星代表SPP
Backbone部分:
PP-YOLO将YOLOv3的DarkNet-53替换成ResNet50-vd-dcn。由于直接替换成ResNet50-vd会掉点,所以将最后一个stage的3x3卷积替换成了DCN(Deformable Convolutional Networks,可变形卷积)。用来做预测的特征图为C3,C4,C5。
Neck部分:
拿Backbone输出的C3,C4,C5特征图应用FPN,其中FPN经过DropBlock、CoordConv和SPP改进。
Head部分:
和YOLOv3一样,分三个特征图输出,每个特征图每个网格设置3个anchor,每个网格位置输出3x(k+6),增加一个通道预测IoU大小,对于NxN大小的特征图输出为NxNx3x(k+6)的tensor。其他改进的地方为在最后预测层3x3卷积中加入CoordConv。
2.1 Selection of Tricks
- Larger Batch Size: 大的batchsize可以增加训练稳定性得到更好的结果。将batchsize由64变成192。
- EMA: 在训练模型时,保持训练参数的移动平均线通常是有益的。
- DropBlock: 只在FPN中应用DropBlock。
- IoU Loss: 与YOLOv4不同的是,作者并没有直接用IoU损失代替l1损失,而是增加了一个分支来计算IoU损失。由于作者发现各种IoU损失的改善效果相似,所以选择了最基本的IoU损失。
- IoU Aware: 在YOLOv3中,分类概率和objectness得分相乘作为最终检测目标的置信度得分,但是这没有考虑定位精度。为了解决这一问题,增加了IoU预测通道来衡量定位的准确性。即输出通道数由B*(5+C)增加为B*(6+C)。在训练过程中,采用IoU感知损失训练IoU预测值。在推理过程中,将预测的IoU乘以分类概率和objectness得分,计算出最终的检测置信度,该置信度与定位精度更相关。然后将最终检测置信度用作后续NMS的输入。虽然IoU感知分支会增加额外的计算成本。但是,只增加了0.01%的参数个数和0.0001%的flop,几乎可以忽略不计。
- Grid Sensitive: 借鉴YOLOv4的改进
- Matrix NMS: 受到了soft-NMS的启发,并行的方式实现NMS,更快。
- CoordConv: 它的工作原理是通过使用额外的坐标通道让卷积访问自己的输入坐标。CoordConv允许网络学习完全的变换不变性或不同程度的变换依赖性。考虑到CoordConv将在卷积层中增加两个输入通道,因此将增加一些参数和FLOPs。为了尽可能减少效率的损失,作者没有改变骨干中的卷积层,只将FPN中的1x1卷积层和检测头中的第1个卷积层替换为CoordConv。
- SPP: 和YOLOv4一样,也引入了SPP层增大感受野。
- Better Pretrain Model: 使用蒸馏的ResNet50-vd模型作为预训练模型。
3、实验
3.1 消融实验
作者对以上改进做了消融实验,如下表所示:
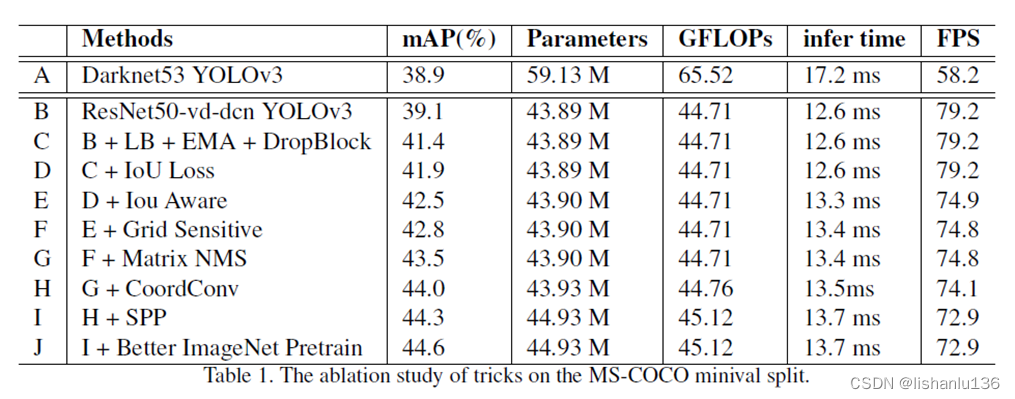
值得注意的是:作者在YOLOv3的基础上直接替换主干为ResNet50-vd-dcn后,mAP提升,推理速度也加快了。每个trick都有涨点,其中B->C涨点最多。
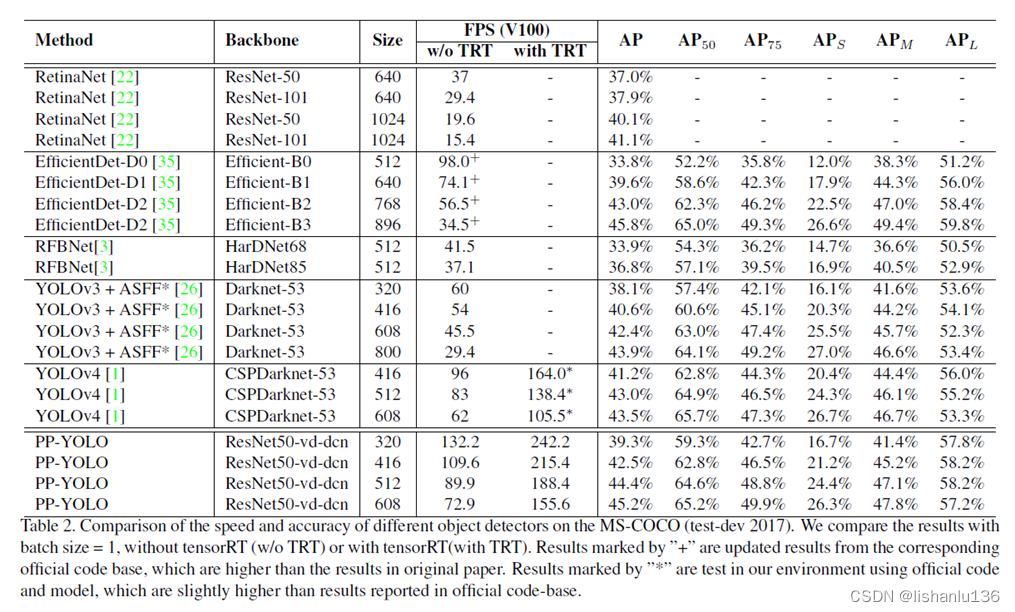
3.2 与其他检测算法比较
PP-YOLO与现如今最新检测算法在COCO数据集上的mAP比较如下表所示。可以看出PP-YOLO无论是mAP指标或者是FPS指标都是非常优秀的。