【超越YOLOv4】百度自研超高效目标检测器——PP-YOLO
前言:

之前,YOLO系列(v1-v3)作者 Joe Redmon 宣布不再继续CV方向的研究,引起学术圈一篇哗然。YOLO之父宣布退出CV界,坦言无法忽视自己工作带来的负面影响。当大家以为再也见不到YOLOv4的时候,然鹅不久前YOLOv4 来了!
YOLOv4的特点是集大成者,俗称堆料。但最终达到这么高的性能,一定是不断尝试、不断堆料、不断调参的结果,最终取得了非常好的成绩。更令人震惊的是,YOLOv4热度未退,PaddlePaddle又爆出猛料——发表了《PP-YOLO: An Effective and Efficient Implementation of Object Detector》。改论文提出的PP-YOLO称已经超越YOLOv4,我们来一睹为快吧!
论文地址:https://arxiv.org/pdf/2007.12099.pdf

简介:
目标检测是计算机视觉研究的重要领域之一,在各种实际场景中起着至关重要的作用。在实际应用中,由于硬件的限制,往往需要牺牲准确性来保证检测器的推断速度。因此,必须考虑目标检测器的有效性和效率之间的平衡。本文的目标不是提出一种新的检测模型,而是实现一种效果和效率相对均衡的对象检测器,可以直接应用于实际应用场景中。考虑到YOLOv3在实际应用中的广泛应用,作者开发了一种新的基于YOLOv3的对象检测器。
本文的作者们主要尝试结合现有的几乎不增加模型参数和FLOPs的各种技巧,在保证速度几乎不变的情况下,尽可能提高检测器的精度。由于本文所有实验都是基于PaddlePaddle进行的,所以作者称之为PP-YOLO。通过多种技巧的结合,PP-YOLO可以在效率(45.2% mAP)和效率(72.9 FPS)之间取得更好的平衡,超过了目前最先进的检测器EfficientDet和YOLOv4。
并且不像YOLOv4花费很大努力在探索高效的主干网络和数据增强策略,并且使用了NAS来搜索超参数(使得模型泛化性降低),PP-YOLO探索了更高效、使得模型更具有泛化性的策略。它的主干网络仅仅使用了ResNet,数据增强也只是直接用了MixUp,这使得PP-YOLO在训练和推理是更加高效。
同时这也说明使用更多Tricks和最新的主干网络,可能会使得PP-YOLO模型更准确。
网络结构:

Backbone:

原始的YOLOv3使用DarkNet-53提取不同尺度的feature map。由于ResNet得到了广泛的应用和研究,有更多不同的变体可供选择,也通过深度学习框架得到了更好的优化。因此,作者在PP-YOLO中将原来的主干DarkNet-53替换为ResNet50-vd。
考虑用ResNet50-vd直接替代DarkNet-53,会影响YOLOv3检测器的性能。作者将ResNet50-vd中的一些卷积层替换为可变形的卷积层。可变形卷积网络(DCN)的有效性已经在许多检测模型中得到验证。DCN本身不会显著增加模型中参数和FLOPs的数量,但在实际应用中,过多的DCN层会大大增加推断时间。因此,为了平衡效率和有效性,作者只在最后阶段用DCNs替换3×3个卷积层。作者将这个修改后的主干表示为ResNet50-vd-dcn,输出为 。
Detection Neck:

PP-YOLO也使用了FPN(特征金字塔)结构,并在特征图之间添加了横向连接。主干网络输出特征层 作为FPN结构的输入,分别得到特征金字塔 ,其中 ,并且对于输入大小为 的图片,有 大小为 。
Detection Head:

检测头很简单,就是使用一个
卷积和一个
卷积获得最后输出预测。每个输出的通道数为
,其中
是类别数,
代表关联的3个不同大小的anchors,
代表预测的坐标框偏移量(4个值)和一个置信度。
对于分类和回归问题,损失函数分别使用了交叉熵损失函数和L1损失函数。
优化技巧:
本节将介绍作者在本文中使用的各种技巧。这些技巧都是已经存在的,来自不同的作品。本文没有提出一种新的检测方法,只是着重结合现有的技术实现一种高效的检测器。因为很多技巧不能直接应用到YOLOv3上,而是需要根据YOLOv3的结构进行调整。
Larger Batch Size:
使用更大的Batch Size会获得更好的模型稳定性,模型精度也会提升,因此作者将Batch Size从64调整到196。
EMA:
当训练一个模型时,保持训练参数的移动平均通常是有益的。使用平均参数的评估有时会产生比最终训练值好得多的结果。指数移动平均(EMA)使用指数衰减计算训练参数的移动平均。因此对于每个参数
,保留一个隐参数:
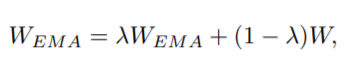
其中
是衰减系数。因此作者使用衰减系数为0.9998的EMA,并使用隐参数
进行评估。
DropBlock:

DropBlock是结构化的dropout的一种形式,它将feature map相邻区域中的单元一起删除。与原论文不同的是,作者只对检测头使用DropBlock,因为作者发现在主干网络中添加DropBlock会导致性能下降。DropBlock的具体插入点在图中用紫色三角形标记。
IoU Loss:
与YOLOv4不同,作者没有直接将L1损失替换为IoU损失,而是增加了一个分支来计算IoU损失。
IoU Aware:
在YOLOv3中,将分类概率和前景得分乘作为最终检测置信度,而不考虑定位精度。为了解决这一问题,作者引入了IoU预测分支来衡量定位精度。在训练过程中,采用IoU感知损失来训练IoU预测分支。在推理时,将预测的IoU乘以分类概率和客观评分来计算最终的检测置信度,置信度与定位精度关系更大。然后使用最终的检测置信度作为后续NMS的输入。这只添加了0.01%的参数和0.0001%的FLOPs,几乎可以忽略。
Grid Sensitive:
网格敏感是YOLOv4引入的一个有效技巧。当我们解码边界盒中心x和y的坐标时,在原始YOLOv3中,我们可以通过以下式子得到它们:
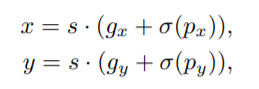
其中,
为sigmoid激活函数,
和
为整数。显然,
和
不能完全等于
或
,这使得预测仅仅位于网格边界上的边界框的中心变得困难。我们通过可以把方程变成以下式子来解决这个问题:
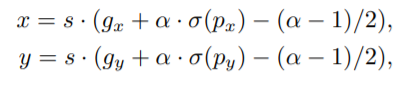
其中,本文将
设置为1.05。这使得模型更容易准确地预测边界框中心位于网格边界上。
Matrix NMS:
Matrix NMS是由Soft NMS演化而来,并以并行的方式实现NMS。因此,Matrix NMS比传统NMS速度快,不会带来任何效率损失。
CoordConv:
CoordConv是通过使用额外的坐标通道对自己的输入坐标进行卷积访问。CoordConv允许网络学习完全的平移不变性或不同程度的平移依赖。考虑到CoordConv会在卷积层增加两个输入通道,因此会增加一些参数和FLOPs。为了尽可能减少效率的损失,作者不改变骨干网中的卷积层,只使用CoordConv替换FPN中的1x1卷积层和检测头中的第一卷积层。在图中,CoordConv的具体插入点由橙色的菱形标记。
SPP:

空间金字塔池(SPP)将SPM集成到CNN中,使用max-pooling操作,而不是bag-of-word操作。YOLOv4通过将大小为 最大池化输出连接起来来应用SPP模块,其中 , 。
PP-YOLO的SPP具体插入点带有红色星号标记。SPP本身没有引入参数,但是接下来的卷积层的输入通道数量会增加。所以增加了大约2%的参数量和1%的FLOPs。

实验结果:

