PPYOLO:不容错过的目标检测调参Tricks
1. 摘要
目标检测是计算机视觉一个重要的领域。而目标检测算法的准确性和推理速度不可兼得,我们工作旨在通过tricks组合来平衡目标检测器的性能以及速度。考虑到yolo3的广泛应用,我们考虑在yolo3基础模型训练得到一个更快,准确率更高的模型,即PP-YOLO。
2. 介绍
最近出现了yolov4,5模型,这些模型也是基于yolo3算法改进得来。但PPYOLO并不像yolov4探究各种复杂的backbone和数据增广手段,也不是靠nas暴力搜索得到一个结构。我们在resnet骨干网络系列,数据增广仅靠mixup的条件下,通过合理的tricks组合,不断提升模型性能。最终与其他模型对比图如下
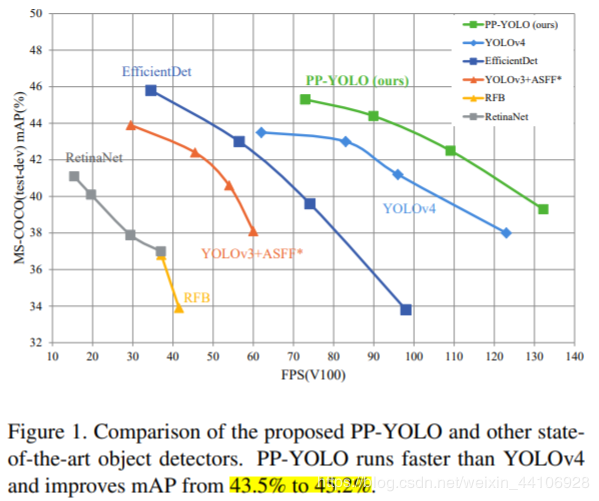
3. 方法
3.1 网络架构

yolov3使用的是较为大型的darknet53,考虑到resnet更广泛的应用以及多样化的分支,我们选用ResNet50-vd作为整个架构,并将部分卷积层替换成可变形卷积,适当增加了网络复杂度。由于DCN会带来额外的推理时间,我们仅仅在最后一层的3x3卷积替换成DCN卷积
3.1.2 DetectionNeck
这里依然采取的是FPN特征金字塔结构做一个特征融合,类似Yolo3,我们选取最后三个卷积层C3, C4, C5,然后经过FPN结构,将高层级语义信息和低层级信息进行融合。由于FPN我们接触的比较多了这里就不展开讲了
3.1.3 DetectionHead
原始yolo3的检测头是一个非常简单的结构,通过3x3卷积并最后用1x1卷积调整到自己所需要的通道数目。输出通道数为,3代表每个层设定的三种尺寸的锚框,K代表类别数目,5又可以分成4+1,分别是目标框的4个参数,以及1个参数来判断框里是否有物体。
3.2 Tricks的选择
3.2.1 更大的batchsize
使用更大的batch能让训练更加稳定,我们将batchsize从64调整到196,并适当调节训练策略以及学习率
3.2.2 滑动平均
类似于BN里的滑动平均,我们在训练参数更新上也做了滑动平均策略
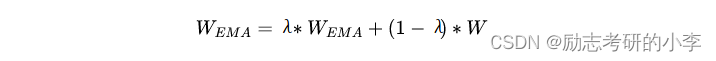
λ这里取0.9998
3.2.3 DropBlock
DropBlock也是谷歌提的一个涨点神器,但是适用范围不大。作者发现给BackBone直接加DropBlock会带来精度下降,于是只在检测头部分添加。关于DropBlock可以看我们写的这篇文章:【科普】神经网络中的随机失活方法
3.2.4 IOU Loss
在yolov3中使用的是smooth L1 Loss来对检测框做一个回归,但这个Loss并不适合以mAP为评价指标。因此yolov4中引入了IOU Loss完全替换掉smooth L1 Loss。不同的是我们在原始的L1 Loss上引入额外的IOU Loss分支,由于各个版本的IOU Loss效果差不多,我们选用最基础的IOU Loss形式
3.2.5 IOU Aware
在yolov3中,分类概率和目标物体得分相乘作为最后的置信度,这显然是没有考虑定位的准确度。我们增加了一个额外的IOU预测分支来去衡量检测框定位的准确度,额外引入的参数和FLOPS可以忽略不计
3.2.6 GRID Sensitive
原始Yolov3对应中间点的调整公式如下
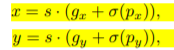
其中 @ 表示sigmoid函数 由于sigmiod函数两端趋于平滑,中心点很难根据公式调节到网格上面 因此我们改进公式为
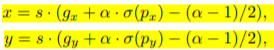
3.2.7 Matrix NMS
受Soft-NMS启发,将NMS转为并行方法运行。Matrix NMS相较传统NMS运行速度更快。
3.2.8 CoordConv
CoordConv的提出是为了解决常规卷积在空间变换的问题。

4. 实验部分
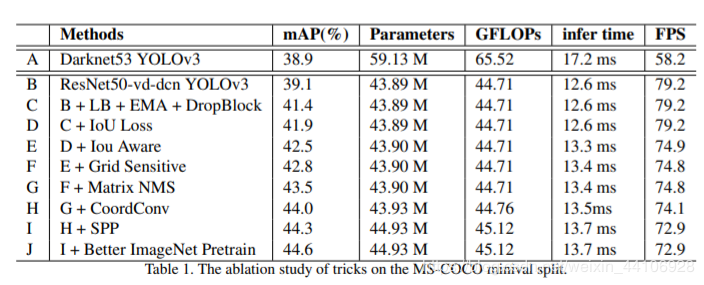
笔者认为这篇论文的实验部分十分精彩,不是无脑的堆叠,而是有理有据的去分析,各个阶段该用什么tricks,非常适合炼丹入门的小伙伴学习
4.1 A->B
首先就是搭建基础版本的PP-YOLO,在尝试替换backbone后,虽然参数小了很多,但是mAP也下降了不少。我们通过增加了DCN卷积,将mAP提高到39.1%,增加的参数仍远远小于原始yolo3
4.2 B->C
基础模型搭建好后,我们尝试优化训练策略 选用的是更大的batch和EMA,并且加入DropBlock防止过拟合,mAP提升到了41.4%
4.3 C->F
我们在这个阶段分别增加了IOU Loss,IOU Aware,Grid Sensitive这三个损失函数的改进。分别得到了0.5%, 0.6%, 0.3%的提升,将mAP提升到了42.8%,推理速度下降仍属于可接受范围内
4.4 F->G
检测框的处理部分也是能提升性能的,通过增加Matrix NMS,mAP提高了0.6%。这个表格暂时不考虑NMS对推理时间的影响,在实际测试中,MatrixNMS是能比传统NMS降低推理时间的
4.5 G->I
到了最后阶段,很难通过增加网络复杂度来提高mAP,因此我们将SPP和CoordConv放到这里再来考虑。这两个结构所带来的额外参数较少,而实验也证明了将mAP提高到44.3%
4.6 I->J
分类模型的好坏不能代表整个检测模型的性能,因此我们最后才考虑是否用更好的预训练模型。我们仍然是在ImageNet上进行预训练得到了一个更好的模型,并且提升了0.3%的mAP
5. 总结
PP-YOLO没有像yolo4那样死抠现有的SOTA网络结构,而是着眼于合理的tricks堆叠。通过有效的计算,很好的平衡了准确率以及推理时间,而其中的实验部分也非常适合学习炼丹的小伙伴。