PP-YOLOv2
目录
数据增强 :+ MixUp
Backbone :换R50 + Better Pre-Train + dcn
Neck :+ SPP + CoordConv + DropBlock + PAN + MISH
Loss :+ IoU Loss + IoU Aware Loss
其他 :+ Large Batch Size + Grid Sensitive + EMA + Matrix NMS + Large Input Size
(黑色为PP-YOLOv1版本添加的内容,红色为 PP-YOLOv2 版本新添加的内容)

数据增强
PP-YOLO 没有探究各种复杂的 backbone 和数据增广手段,也不是靠 NAS 暴力搜索得到一个结构。模型在 ResNet 骨干网络系列,仅靠 mixup,通过合理的 tricks 组合,提升模型性能。(NAS 是给定一个搜索空间的候选神经网络结构集合,用某种策略从中搜索出最优网络结构。)
MixUp(ICLR2018)
背后的直觉:平滑了数据集
影响:增加精度,不减少速度

补充:
当训练集中的图片比较少时,容易造成网络的过拟合。为了避免这种情况,一般要经过图像处理,人为地去增加些图片数据,这样就会增加可用图片的数目,减少过拟合的可能性。
可以通过像素级的剪裁(Crop)、旋转(Rotation)、反转(Flip)、色调(Hue)、饱和度(Saturation)、曝光量(Exposure)、宽高比(Aspect)来做数据增强。另外还可以在图片级数据增强,比如 MixUp、CurMix、Mosaic、Blur。
Mixup(2017):在一张狗的图片中,叠加一只猫的图片,经过两幅图片的加权运算可以看到图片上既有狗又有猫。
Cutout(2017):将图片中某一块区域,填充为某种颜色。
CutMix(2019):将图片某一块区域剪裁掉,然后用另外一幅图像来填充剪裁区域。
Mosaic 数据增强(2020):它把 4 幅图片拼成一幅图,YOLOv5 中数据增强就是采用 Mosaic 方法,该方法由 YOLOv5 作者提出。YOLOv5 在训练过程中,将4幅小图拼成一幅大图,4幅小图在拼接时做了随机的处理,所以4幅小图的大小形状是不一样的。



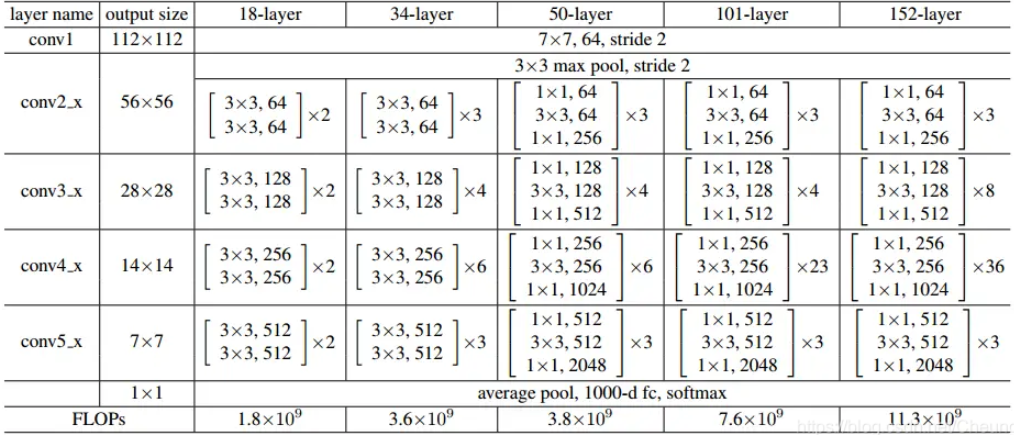
Backbone
DarkNet53 -> ResNet50 + Better PreTrain(ResNet 是比较成熟的 backbone,并且优化过。)

增加 DCN(可变形卷积 2017)(通用的涨点方式,加一点点,PP-YOLO 仅加一层)
背后的直觉:参与计算的点应该集中在物体上
影响:涨点但掉速度

补充
什么是可变形卷积?
可变形卷积指卷积核在每个元素上增加了一个参数方向参数,这样卷积核就能在训练过程中扩展到很大的范围。
(a)传统的标准卷积核,尺寸为3x3(图中绿色的点);
(b)可变形卷积,通过在图(a)的基础上给每个卷积核的参数添加一个方向向量(图b中的浅蓝色箭头),使卷积核变为任意形状;
(c)和(d)是可变形卷积的特殊形式。为什么要可变形卷积?
卷积核的目的是为了提取输入物的特征。传统的卷积核通常是固定尺寸、固定大小的。这种卷积核存在的最大问题就是,对于未知的变化适应性差,泛化能力差。
- 卷积单元对输入的特征图在固定的位置进行采样;
- 池化层不断减小着特征图的尺寸;
- RoI 池化层产生空间位置受限的 RoI。
网络内部缺乏能够解决这些问题的模块,这会产生显著的问题,同一 CNN 层的激活单元的感受野尺寸都相同,这对于编码位置信息的浅层神经网络并不可取,因为不同的位置可能对应有不同尺度或者不同形变的物体,这些层需要能够自动调整尺度或者感受野的方法。再比如,目标检测虽然效果很好但是都依赖于基于特征提取的边界框,这并不是最优的方法,尤其是对于非网格状的物体而言。
因此,希望卷积核可以根据实际情况调整本身的形状,更好的提取输入的特征。

Neck
增加 SPP(2015)
背后的直觉:获得不同的感受野
影响:加一点点参数,涨性能

增加 CoordConv(2018)
背后的直觉:Conv 做不好 one-hot 转坐标这种任务所以把坐标信息传进去
影响:加一点点参数,涨性能

它在输入特征图,添加了两个通道,一个表征 i 坐标,一个表征 j 坐标。这两个通道带有坐标信息,从而允许网络学习完全平移不变性和变化平移相关度。
为了平衡带来的额外参数和 FLOPS,PP-YOLO 只替换掉 FPN 的1x1卷积层以及 detection head 的第一层卷积。
传统卷积具备平移不变性,这使得其在应对分类等任务时可以更好的学习本质特征。不过,当需要感知位置信息时,传统卷积有点力不从心。为了使得卷积能够感知空间信息,作者在输入 feature map 后面增加了两个 coordinate 通道,分别表示原始输入的 x 和 y 坐标,然后再进行传统卷积,从而使得卷积过程可以感知 feature map 的空间信息,该方法称之为CoordConv。使用了 CoordConv 之后,能够使得网络可以根据不同任务需求学习平移不变性或者一定程度的平移依赖性。(平移不变性意味着系统产生完全相同的响应(输出),不管它的输入是如何平移的 。)
+ DropBlock(2018)
Dropout 被广泛的使用作为一种正则化技术在全连接层中,但在卷积层中却收效甚微。作者认为卷积层中的激活单元(特征图上元素)在空间中是相关的,所有尽管 Dropout 可以进行信息丢失,但信息仍然可以通过卷积网络流通。
作者提出了 DropBlock,一种结构化的 Dropout 形式,特征图上的邻域单元被一起丢弃,这样可以提高准确率。大量的实验表明,DropBlock 在正则化的卷积网络中性能优于 Dropout。
DropBlock 是谷歌提的一个涨点神器,但是适用范围不大。在 PP-YOLO 模型中发现给 BackBone 直接加 DropBlock 会带来精度下降,于是只在检测头部分添加。

+ PAN
背后的直觉:增强 Neck 部分的特征融合能力
影响:掉速度,涨性能
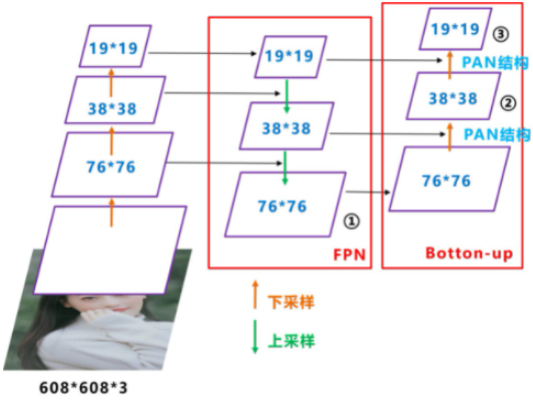
FPN 层自顶向下传达强语义特征(高层语义是经过特征提取后得到的特征信息,它的感受野较大,提取的特征抽象,有利于物体的分类,但会丢失细节信息,不利于精确分割。高层语义特征是抽象的特征。),而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合。FPN+PAN 借鉴的是 18 年 CVPR 的 PANet,当时主要应用于图像分割领域,但 Alexey 将其拆分应用到 Yolov4 中,进一步提高特征提取的能力。
使用 MISH
背后的直觉:处处平滑,<0部分也应该有值
影响:涨性能,几乎不掉速度
Mish Activation Function 已有研究 YOLOv4 与 YOLOv5 表明:Mish 对于改进目标检测器的性能非常有效。由于百度已经有了一个非常强有力的预训练骨干模型(82.4% top1 精度),为保持骨干结构不变,仅将 Mish 用到了 Neck 部分。
Loss
+ IoU Loss
背后的直觉:定位时,x,y,w,h 的 loss 应该一同计算
影响:涨性能,不掉速度

+ IoU Aware Loss
背后的直觉:直接预测 IoU?
影响:涨性能,轻微掉速度

其他
+ Large Batch Size
+ Grid Sensitive
背后的直觉:Sigmoid 后 0,1 很难出,需要调整一下
影响:涨性能,不掉速度

预测时,定位的物体中心点 x,y,首先经过 sigmoid,再加上 grid 的 Cx,Cy。若物体的中心在 grid 的交点处,sigmoid 需要出 0 或 1 才能够很准,但 sigmoid 出 0/1 比较困难。
原始 YOLOv3 对应中间点的调整公式:其中 σ 表示 sigmoid 函数。
由于 sigmoid 函数两端趋于平滑,中心点很难根据公式调节到网格上面,因此改进公式为:α 设为 1.05,能帮助中心点回归到网格线上。
+ 指数滑动平均EMA,直接作用于指数 W 上
背后的直觉:平均一下更容易到最优解
影响:涨性能,不掉速度
在训练参数更新上也做了滑动平均策略。
滑动平均可以使模型在测试数据上更健壮。对神经网络边的权重 weights 使用滑动平均,得到对应的影子变量 shadow_weights。在训练过程仍然使用原来不带滑动平均的权重 weights,之后在测试过程中使用 shadow_weights 来代替 weights 作为神经网络边的权重,这样在测试数据上效果更好。因为 shadow_weights 的更新更加平滑,对于随机梯度下降而言,更平滑的更新说明不会偏离最优点很远;对于梯度下降 batch gradient decent,我感觉影子变量作用不大,因为梯度下降的方向已经是最优的了,loss 一定减小;对于 mini-batch gradient decent,可以尝试滑动平均,毕竟 mini-batch gradient decent 对参数的更新也存在抖动。

+ Matrix NMS
背后的直觉:Soft NMS 的并行处理版本
影响:涨性能,加速度
非极大值抑制问题,解决同一个物体有多于一个候选框输出的问题,用于过滤掉重叠的候选框。
- 算法输入:包含各框的位置坐标,以及置信度得分
- 算法步骤:设定 IOU 阈值;对种类进行循环;对同一种类类别而言,将所有边框按照置信度进行排序,取得分最高的边框并保存,使其与其余边框计算 IOU,去掉计算结果中大于阈值的结果;未处理的边框中继续选一个类别得分最高的,直到处理完所有的边框为止。保留下来的候选框即为检测结果。
存在问题:
- 强制去掉得分较低的边框,影响召回率。
- IOU 阈值难以人为确定。
- 得分高的边框位置不一定更优。
- 速度有点慢
Soft NMS:对于得分小于阈值的边框,不再直接舍弃,而是降低其得分,设其原本得分为S:S = S ×(1 - IOUs),其实是对于 IOU 中较小的一部分框,其1-IOU较大,得分衰减不会很厉害。

+ Large Input Size
大 Batch 还是大 Input size?
背后的直觉:大 Batch 稳定训练,大 Input size 对小物体好
影响:涨性能,不影响速度
PPYOLO 总结
PPYOLO 实际上是 YOLOv3 的一个魔改增强版本,在 YOLOv3 的基础上,尝试了非常多的小改进方法,最终拿到了这样的结果。PP-YOLOv2 在同等速度下,精度超越 YOLOv5!

PP-YOLO Tiny
模型设计和优化(PP-YOLO Tiny 选择第一种大类)
- 网络结构
- 小型高性价比 Backbone
- Head 优化(减小个数,小型化设计,不同 head 特征复用等)
- 深度可分离卷积
- 数据增强
- Image Mixup / Mosaic
- Random Crop
- Auto Augment
- 训练策略
- IoU Loss
- EMA
- Sync Batch norm
- 调整正负样本 assign 方式
模型压缩
- 卷积通道裁剪
- Uniform
- Sensitive
- FPGM
- 知识蒸馏
- L2 Loss
- Soft Label
- FSP
- 量化
- 在线量化
- 离线量化
- PACT
- 搜索
- NAS
优化方法 - Backbone 的选择

Mobilenet V3 是 Google 使用模型搜索的方法搜索出来高性价比的模型,继承了 Mobilenet V1 和Mobilenet V2 模型的特点。

0.5x 指将原来的模型缩小了一半,即将所有的 channel 数×0.5。
目标检测领域使用图像分类作为 backbone 时,一般都会将 fc 层排除掉
优化方法 - head 优化(Neck + Head)


| 模型 | 输入尺寸 | GFLOPs |
| YOLOv3- MobileNetV3 |
608×608 | 17.7 |
| 512×512 | 12.6 | |
| 416×416 | 8.3 | |
| 320×320 | 4.9 | |
| 特征变小,影响召回率 | ||
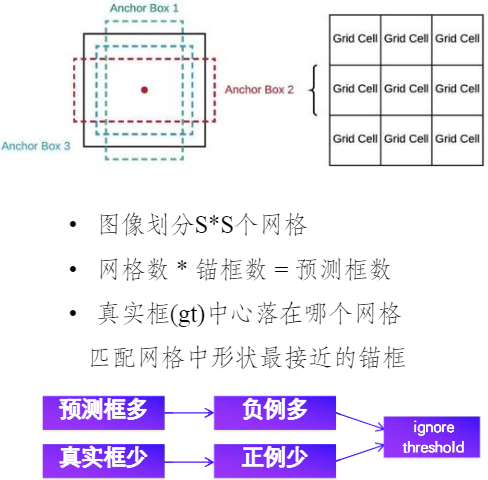
| 提升召回率 |
|
|
| 优化方法 | 效果 | |
| 数据增强 | Image Mixup | 增强背景信息,平滑数据集,提高抗干扰能力 |
| 模型特征 | SPP | 多尺度特征 |
| DropBlock | 随机丢弃特征快,减小过拟合 | |
| 后处理 | Grid Sensitive | 中心坐标回归上的 label smooth,减小过拟合 |
| 损失优化 | IoU Loss | -IoU 加入 loss 中,提升定位精度 |
| 训练优化 | Sync Batch Norm | 卡间同步均值和方差 |
| EMA | 历史梯度平滑,训练更加稳定 | |
| Larger Batch Size | 8 × 32,训练更加稳定 | |
服务器端效果好,而移动端不适用:
- Coord Conv
- 增加两个通道表示 x,y 坐标,获取全局信息
- 移动端 CPU 计算,通道数为 8 的倍数性能最优
- Matrix NMS
- GPU 并行计算各预测框间的 IoU
- 移动端 CPU 无法发挥并行计算优势,计算量增大
- IoU Aware
- 学习预测框和真实框间的 IoU,调整预测排序
- 新增很多细粒度算子,移动端速度影响较大
优化方法 - 后训练量化

模型已经训练好,权重已经存储下来,它是 float32 的权重。通过一个算法,把 float32 映射到 int8 上,让存储的权重以 int8 的形式来存储。在加载 int8 的权重的进行预测时,通过映射函数,将其加载回 float32 的权重。
对精度基本没有损失,压缩了模型体积。

卷积通道裁剪:裁剪冗余通道、减小模型大小、降低 FLOPs,提升预测速度、边裁剪边训练。

知识蒸馏:精度高模型 – teacher、teacher 学习到的预测结果指导student、提升模型精度、不影响 FLOPs 和预测速度。
知识蒸馏是模型压缩的一种常用的方法,不同于模型压缩中的剪枝和量化,知识蒸馏是通过构建一个轻量化的小模型,利用性能更好的大模型的监督信息,来训练这个小模型,以期达到更好的性能和精度。最早是由 Hinton 在 2015年 首次提出并应用在分类任务上面,这个大模型我们称之为 teacher(教师模型),小模型我们称之为Student(学生模型)。来自Teacher 模型输出的监督信息称之为 knowledge(知识),而 student 学习迁移来自 teacher 的监督信息的过程称之为 Distillation(蒸馏)。

YOLOv3 剪裁+蒸馏
- •PaddleDetection 提供一键式剪裁 + 蒸馏脚本
- •YOLOv3-MobileNetV1 剪裁67% FLOPs,精度基本无损,移动端加速 2.3 倍,GPU 加速 60%
- •YOLOv3-ResNet50vd-DCN 剪裁 43% FLOPs,精度提升 0.6,GPU加速20%
| 模型 | 数据集 | 策略 | mAP | FLOPs | Tesla P4推理时延 | 高通855 推理时延 |
| YOLOv3-MobileNetV1 | COCO | — | 29.3 | — | — | 321.35 ms |
| YOLOv3-MobileNetV1 | COCO | 剪裁+ YOLOv3-ResNet34蒸馏 |
29.0 | -67.56% | — | 139.71ms |
| YOLOv3-MobileNetV1 | VOC | — | 76.2 | — | 16.55ms | 289.87ms |
| YOLOv3-MobileNetV1 | VOC | 剪裁+ YOLOv3-ResNet34蒸馏 |
78.8 | -69.57% | 10.06ms | 123.41ms |
| YOLOv3-ResNet50vd-DCN | COCO | — | 39.1 | — | 35.20ms | — |
| YOLOv3-ResNet50vd-DCN | COCO | 剪裁+ YOLOv3-ResNet34蒸馏 |
39.7 | -43.69% | 29.13ms | — |
YOLOv3-MobileNetV3 剪裁+蒸馏
–MobileNetV3,精度速度更优的骨干网络
–剪裁:更优的剪裁方式FPGM,减少模型大小和计算量
–蒸馏:精度更高的YOLOv3-ResNet34作为teacher模型
–PaddleDetection提供了一键式剪裁+蒸馏脚本及教程
| Backbone | 策略 | 剪裁率 | mAP | 320×320 推理时延 |
| MobileNetv3 | baseline | - | 27.1 | 319ms |
| MobileNetv3 | 剪裁+蒸馏 | 50%,75%,87.5% | 25.9 | 107ms |
| MobileNetv3 | 剪裁+蒸馏 | 75%,75%,87.5% | 24.6 | 89ms |
| 注:剪裁率为 YOLOv3 模型 head 部分三个输出分支对应的剪裁率 | ||||

移动端模型库
–低端算力:SSDLite模型 + 量化
–中端算力:兼顾速度和精度的YOLOv3压缩模型
–高端算力:高精度的Cascade Faster RCNN模型
| 模型 | 主干网络 | 模型大小 | COCO mAP |
推理时延 (晓龙845) |
| SSDLite | MobileNetV3 small | 11M | 16.6 | 41ms |
| MobileNetV3 large | 21M | 22.8 | 92ms | |
| SSDLite+量化 | MobileNetV3 small | 2.8M | 16.1 | 34ms |
| MobileNetV3 large | 5.3M | 22.7 | 80ms | |
| YOLOv3+剪裁+蒸馏 | MobileNetV3 large | 28MB | 25.9 | 107ms |
| MobileNetV3 large | 16MB | 24.6 | 89ms | |
| Cascade Faster-RCNN | MobileNetV3 large | 15MB | 25.0 | 87ms |
| MobileNetV3 large | 15MB | 30.2 | 351ms |