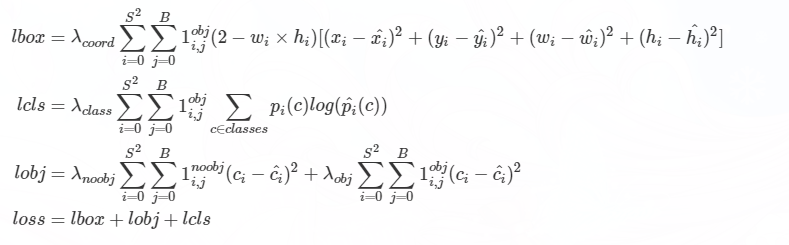YOLO V1(2016)
YOLO将物体检测作为回归问题求解。基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。
YOLO 的核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别。
基本流程:将图片划分为 77=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 492=98 个bounding box,然后通过NMS等。
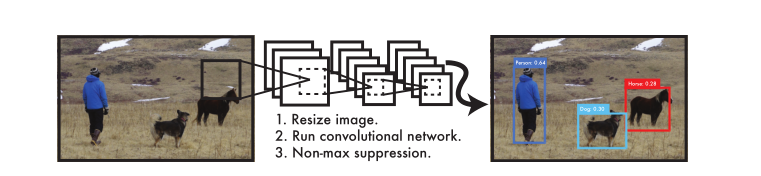
网络模型
YOLO将输入图像分成SxS个格子,每个格子负责检测‘落入’该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。每个格子输出B个bounding box(包含物体的矩形区域)信息,以及C个物体属于某种类别的概率信息。
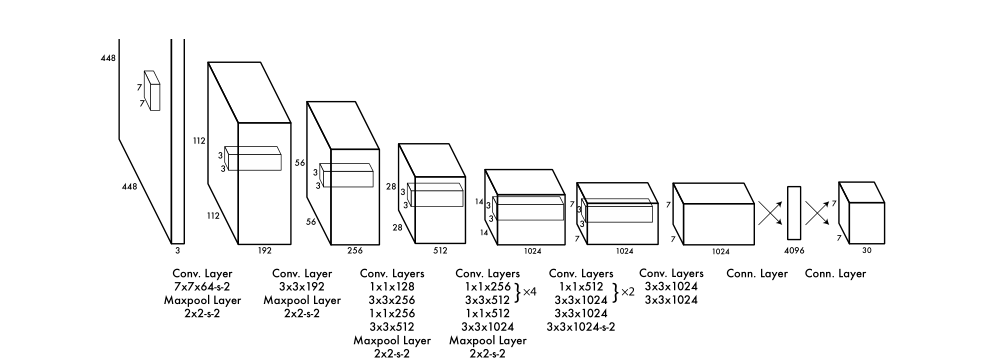
输入与输出
主要是因为YOLO的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入,YOLO论文中,作者训练采用的输入图像分辨率是448x448。YOLO网络最终的全连接层的输出维度是 SS(B*5 + C)。S=7,B=2;采用VOC 20类标注物体作为训练数据,C=20。
每个bounding box需要4个数值来表示其位置(x , y , w , h )以及一个置信度分数confidence。其中坐标的 x, y 用对应网格的 offset 归一化到 0-1 之间,w, h 用图像的 width 和 height 归一化到 0-1 之间。
bounding box的置信度 = 该bounding box内存在对象的概率 * 该bounding box与该对象实际bounding box的IOU
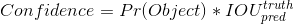
损失函数
损失函数采用均方误差。对没有 object 的 box 的 confidence loss,赋予小的 loss weight,赋值为0.5。坐标损失权重赋予更大的权重,值为5。
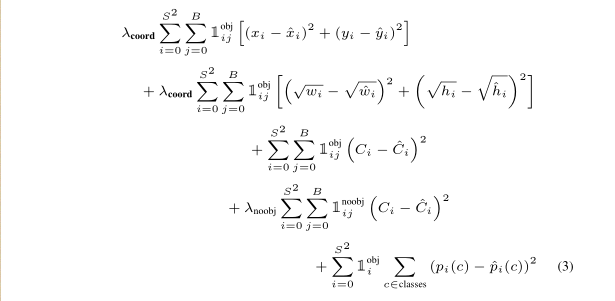
优缺点
优点:速度快,背景预测错误率低,因为是整张图片放到网络里面进行预测。
缺点:识别物体位置精准性差。召回率低。小目标和邻近目标检测效果差,主要是因为网格设置比较稀疏,而且每个网格只预测两个边框,另外Pooling层会丢失一些细节信息,对定位存在影响。
YOLO V2(2017)
V1 缺陷之处:
1、输入尺寸固定:由于输出层为全连接层,因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率。其它分辨率需要缩放成此固定分辨率;
2、占比小的目标检测效果不好:虽然每个格子可以预测 B 个 bounding box,但是最终只选择只选择 IOU 最高的bbox作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
主要贡献有如下:
Fine-Grained Features
在13*13特征图上足够预测大目标了,然而对于小目标来说特征细粒度还不够,添加了一个passthrough层,从26x26的分辨率得到特征,与13x13特征进行拼接。
multi-scale training
在训练过程中,根据迭代次数选择用不同分辨率的图片作为输入。
darknet-19
并且引入了BN层,加速模型的收敛,网络模型为全卷积网络,去掉了全连接层
Anchor Boxes
Faster R-CNN中anchor box 的大小和比例是按经验设定的,YOLOv2 对其做了改进,采用 k-means 在训练集 bbox 上进行聚类产生合适的先验框通过K-means算法得到。论文中选用了K=5,每个格子预测5个边界框。
Direct location prediction
作者就没有采用预测直接的偏移量的方法,而使用了新的方法: 直接预测对于网格单元的相对位置。
其中,pw和 ph都是k-means聚类之后的prior(模板框)的宽和高,yolo直接预测出偏移量 tw和 th,相当于直接预测了bounding box的宽和高。
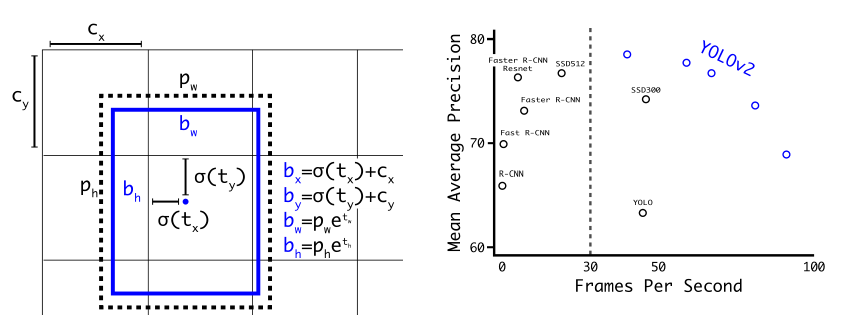
tx,ty经sigmod函数处理过,取值限定在了0~1,就是把偏移量控制在0到1之间。实际意义就是使anchor只负责周围的box,有利于提升效率和网络收敛。 而不是像之前的这个公式没有加以限制条件,所以任何anchor box都可以偏移到图像任意的位置上。
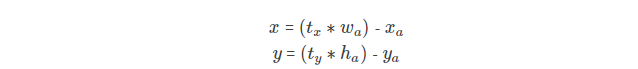
高分辨率分类器
v1使用224 × 224训练分类器网络,扩大到448用于检测网络。v2将ImageNet以448×448 的分辨率微调最初的分类网络,迭代10 epochs。
YOLO V3(2018)
改进之处
1、多尺度预测 (类FPN)
2、更好的基础分类网络(类ResNet)和分类器 darknet-53
3、类别预测方面主要是将原来的单标签分类改进为多标签分类
多尺度预测
每种尺度预测 3 个 box, anchor 的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给 3 个尺度。特征图大小分别为5252,2626,13*13
Backbone网络
采用DarkNet-53,引进了残差结构,网络的特征提取能力大大增强。
yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以输出是一个3*(5 + 80) = 255的张量。
多标签分类
Softmax——> 多个logits二分类器
损失函数
1、一个是xywh部分带来的误差,也就是bbox带来的loss
2、一个是置信度带来的误差,也就是obj带来的loss
3、最后一个是类别带来的误差,也就是class带来的loss