版权声明:转载请注明出处 https://blog.csdn.net/weixin_42683993/article/details/89058712
目标检测算法——Yolo
- YOLO 的核心思想就是利用整张图作为网络的输入,直接在输出层回归 bounding box(边界框) 的位置及其所属的类别。将一幅图像分成 SxS 个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个 object,
- 输出特征向量形式
- 每个网格要预测 B 个 bounding box,每个 bounding box 除了要回归自身的位置之外,还要附带预测一个 confidence 值。 这个 confidence 代表了所预测的 box 中含有 object 的置信度和这个 box 预测的有多准这两重信息,其值是这样计算的:
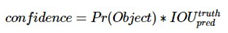
其中如果有 object 落在一个 grid cell 里,第一项取 1,否则取 0。 第二项是预测的 bounding box 和实际的 groundtruth 之间的 IoU 值。 - 每一个栅格还要预测C个 conditional class probability(条件类别概率):Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。 我们只为每个栅格预测一组(C个)类概率,而不考虑框B的数量。
- 每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值,每个网格还要预测一个类别信息,记为 C 类。则 SxS个 网格,每个网格要预测 B 个 bounding box 还要预测 C 个 categories。输出就是 S x S x (5*B+C) 的一个 tensor。(条件类别概率)conditional class probability信息是针对每个网格的。 (置信度)confidence信息是针对每个bounding box的。
- 在测试阶段,将每个栅格的conditional class probabilities与每个 bounding box的 confidence相乘:
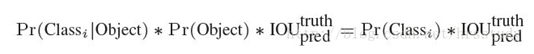
这样既可得到每个bounding box的具体类别的confidence score。 这乘积既包含了bounding box中预测的class的 probability信息,也反映了bounding box是否含有Object和bounding box坐标的准确度。
- 每个网格要预测 B 个 bounding box,每个 bounding box 除了要回归自身的位置之外,还要附带预测一个 confidence 值。 这个 confidence 代表了所预测的 box 中含有 object 的置信度和这个 box 预测的有多准这两重信息,其值是这样计算的:
- 网络结构
YOLO检测网络包括24个卷积层和2个全连接层,如图所示

- 损失函数
- YOLO全部使用了均方和误差作为loss函数.由三部分组成:坐标误差、IOU误差和分类误差。loss=∑i=0s2coordErr+iouErr+clsErr
- 简单相加时还要考虑每种loss的贡献率,YOLO给coordErr设置权重λcoord=5.在计算IOU误差时,包含物体的格子与不包含物体的格子,二者的IOU误差对网络loss的贡献值是不同的。若采用相同的权值,那么不包含物体的格子的confidence值近似为0,变相放大了包含物体的格子的confidence误差在计算网络参数梯度时的影响。为解决这个问题,YOLO 使用λnoobj=0.5修正iouErr。(此处的‘包含’是指存在一个物体,它的中心坐标落入到格子内)。对于相等的误差值,大物体误差对检测的影响应小于小物体误差对检测的影响。这是因为,相同的位置偏差占大物体的比例远小于同等偏差占小物体的比例。YOLO将物体大小的信息项(w和h)进行求平方根来改进这个问题,但并不能完全解决这个问题。
- 综上,YOLO在训练过程中Loss计算如下式所示:

其中有宝盖帽子符号(x,y,w,h,C,p)为预测值,无帽子的为训练标记值。1objij表示物体落入格子i的第j个bbox内.如果某个单元格中没有目标,则不对分类误差进行反向传播;B个bbox中与GT具有最高IoU的一个进行坐标误差的反向传播,其余不进行.
- Yolo v2
相比Yolo v1的改进:- Batchnorm
Batchnorm是2015年以后普遍比较流行的训练技巧,在每一层之后加入BN层可以将整个batch数据归一化到均值为0,方差为1的空间中,即将所有层数据规范化,防止梯度消失与梯度爆炸,加入BN层训练之后效果就是网络收敛更快,并且效果更好。YOLOv2在加入BN层之后mAP上升2%。
梯度消失:因为通常神经网络所用的激活函数是sigmoid函数,这个函数有个特点,就是能将负无穷到正无穷的数映射到0和1之间,并且对这个函数求导的结果是f′(x)=f(x)(1−f(x))f′(x)=f(x)(1−f(x))。因此两个0到1之间的数相乘,得到的结果就会变得很小了。神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层产生的偏差就因为乘了很多的小于1的数而越来越小,最终就会变为0,从而导致层数比较浅的权重没有更新,这就是梯度消失。
梯度爆炸:梯度爆炸就是由于初始化权值过大,前面层会比后面层变化的更快,就会导致权值越来越大,梯度爆炸的现象就发生了。 - 预训练尺寸
yolov1也在Image-Net预训练模型上进行fine-tune,但是预训练时网络入口为224 x 224,而fine-tune时为448 x 448,这会带来预训练网络与实际训练网络识别图像尺寸的不兼容。yolov2直接使用448 x 448的网络入口进行预训练,然后在检测任务上进行训练,效果得到3.7%的提升。 - 更细网络划分
yolov2为了提升小物体检测效果,减少网络中pooling层数目,使最终特征图尺寸更大,如输入为416 x 416,则输出为13 x 13 x 125,其中13 x 13为最终特征图,即原图分格的个数,125为每个格子中的边界框构成(5 x (classes + 5))。需要注意的是,特征图尺寸取决于原图尺寸,但特征图尺寸必须为奇数,以此保存中间有一个位置能看到原图中心处的目标。 - 全卷积网络
为了使网络能够接受多种尺寸的输入图像,yolov2除去了v1网络结构中的全连层,因为全连接层必须要求输入输出固定长度特征向量。将整个网络变成一个全卷积网络,能够对多种尺寸输入进行检测。同时,全卷积网络相对于全连接层能够更好的保留目标的空间位置信息。 - 新基础网络
可以看出作者所使用的darknet-19作为基础预训练网络(共19个卷积层),能在保持高精度的情况下快速运算。而SSD使用的VGG-16作为基础网络,VGG-16虽然精度与darknet-19相当,但运算速度慢。 - anchor机制
yolov2为了提高精度与召回率,使用Faster-RCNN中的anchor机制。在每个网格设置k个参考anchor,训练以GT anchor作为基准计算分类与回归损失。测试时直接在每个格子上预测k个anchor box,每个anchor box为相对于参考anchor的offset与w,h的refine。这样把原来每个格子中边界框位置的全图回归(yolov1)转换为对参考anchor位置的精修(yolov2)。
至于每个格子中设置多少个anchor(即k等于几),作者使用了k-means算法离线对voc及coco数据集中目标的形状及尺度进行了计算。发现当k = 5时并且选取固定5比例值的时,anchors形状及尺度最接近voc与coco中目标的形状,并且k也不能太大,否则模型太复杂,计算量很大。 - 残差层融合低级特征
为了使用网络能够更好检测小物体,作者使用了resnet跳级层结构,网络末端的高级特征层与前一层或者前几层的低级细粒度特征结合起来,增加网络对小物体的检测效果,使用该方法能够将mAP提高1%。
同样,在SSD检测器上也可以看出使用细粒度特征(低级特征)将进行小物体检测的思想,但是不同的是SSD直接在多个低级特征图上进行目标检测,因此,SSD对于小目标检测效果要优于YOLOv2,这点可以coco测试集上看出,因为coco上小物体比较多,但yolov2在coco上要明显逊色于ssd,但在比较简单的检测数据集voc上优于ssd。 - 多尺寸训练
yolov2网络结构为全卷积网络FCN,可以适于不同尺寸图片作为输入,但要满足模型在测试时能够对多尺度输入图像都有很好效果,作者训练过程中每10个epoch都会对网络进行新的输入尺寸的训练。需要注意的是,因为全卷积网络总共对输入图像进行了5次下采样(步长为2的卷积或者池化层), 所以最终特征图为原图的1/32。所以在训练或者测试时,网络输入必须为32的位数。并且最终特征图尺寸即为原图划分网络的方式。
- Batchnorm