参考:
PifPaf: Composite Fields for Human Pose Estimation_MatthewHsw的博客-CSDN博客
OpenPifPaf: encoder过程_MatthewHsw的博客-CSDN博客_openpifpaf
论文地址:https://arxiv.org/pdf/1903.06593.pdf
GitHub地址:GitHub - vita-epfl/openpifpaf: Official implementation of "OpenPifPaf: Composite Fields for Semantic Keypoint Detection and Spatio-Temporal Association" in PyTorch.
官方API:Introduction — OpenPifPaf Guide
浏览器在线测试:https://vita-epfl.github.io/openpifpafwebdemo/
Python openpifpafwebdemo包_程序模块 - PyPI - Python中文网
使用接口文档:Python openpifpaf包_程序模块 - PyPI - Python中文网
使用方法 :
预测单张图片:

运行效果:


调用本地服务,使用浏览器:

运行效果:

Abstract
我们提出了一种新的自下而上的多人2D人体姿态估计方法,特别适合城市交通,如自动驾驶汽车和送货机器人。新的方法PifPaf使用一个Part Intensity Field(PIF)来定位身体部位,一个Part Association Field(PAF)将身体部位相互关联,形成完整的人体姿势。我们的方法在低分辨率和拥挤、杂乱和闭塞的场景中优于以前的方法,这得益于(i)我们新的复合场PAF编码细粒度信息,(ii)回归时选择了包含不确定性概念的拉普拉斯损失。我们的架构是基于完全卷积、单镜头、无盒的(box-free)设计。我们在标准COCO keypoint任务上的表现与现有的最先进的自下而上方法相同,并在运输领域的改进COCO keypoint任务上产生最先进的结果。
1.Introduction
在流行的数据收集运动推动下,在估计人类“in the wild”姿势方面取得了巨大进展。然而,当谈到“交通领域”,如自动驾驶汽车或社交机器人时,我们仍然远远没有达到可接受的精度水平。虽然姿态估计不是最终目标,但它是人类的一种有效的低维和可解释的表示,足以及早发现自主导航系统的关键动作(例如,检测打算穿过街道的行人)。因此,人类姿态检测的效果越好,无人驾驶系统就会越安全。这直接关系到对感知人体姿态所需的最低分辨率的限制。

在本工作中,我们解决了一个已建立的多人2D人体姿态估计问题。我们具体解决了自主导航设置中出现的挑战,如图1所示:(一)宽视角,对人类的分辨率有限,即高度为30-90像素,以及(二)行人相互遮挡的高密度人群。当然,我们的目标是高召回和精确。
虽然在深度学习时代之前,姿态估计已经被研究过,但一个重要的基石是OpenPose[3]的工作,其次是MaskR-CNN[18]。前者是自下而上的方法(检测关节没有人检测器),后者是自顶向下的(首先使用人检测器,并在检测到的边界框中输出关节)。虽然这些方法的性能在足够高的分辨率图像上是惊人的,但它们在有限的分辨率范围内以及在人类部分相互遮挡的密集人群中表现不佳。
在本文中,我们提出将姿态估计[3]中的场的概念扩展到标量场和向量场到复合场。我们提出了具有两个头部网络的神经网络体系结构。
对于每个身体部分或关节,一个头部网络预测置信分数,精确的位置和这个关节的大小,我们称之为Part Intensity Field(PIF),它类似于融合的零件置信图(fused part confidence map)。
另一个头部网络预测部件之间的关联,称为Part Association Field (PAF),它是一种新的复合结构。我们的编码方案具有在低分辨率激活映射上存储细粒度信息的能力。精确回归到关节位置是至关重要的,我们使用基于拉普拉斯 Laplace 的L1损失[23]而不是 vanilla L1损失[18]。我们的实验表明,在低分辨率图像上,我们的性能优于自下而上和建立的自上而下的方法,同时在高分辨率上有同样的表现。该软件是开源的,可在线使用。
2.Related Work
在过去的几年中,最先进的姿态估计方法是基于卷积神经网络。它们的性能优于传统的基于图形结构[12,8,9]和变形零件模型的方法。深度学习始于DeepPose,它使用一系列卷积网络进行全身姿态估计。然后,一些工作不是预测绝对人体关节位置,而是通过预测每次迭代的误差反馈(即校正)来细化姿态估计[4,17]或者使用人体姿态细化网络来利用输入和输出空间[13]之间的依赖关系。现在,在提出替代神经网络架构方面存在着军备竞赛:从卷积姿态机[42],堆叠沙漏网络[32,28],到循环网络[2],以及voting 模式,如[26]。所有这些人类姿态估计方法都可以分为自下而上和自上而下的方法。前者先估计每个身体的关节,然后将它们分组,形成一个独特的姿势。后者首先运行一个人检测器,并在检测到的包围盒中估计身体关节。
Top-down methods
自顶向下方法的例子有PoseNet[35]、RMPE[10]、CFN[20]、Mask R-CNN[18,15]以及最近的CPN[6]和MSRA[44]。这些方法得益于人类探测器和大量标记的bounding-box的进步。利用这些数据的能力将检测器的需求转化为优势。值得注意的是,Mask R-CNN处理关键点检测作为一个语义分割任务。在训练过程中,对于每个独立的关键点,目标被转换为包含单个前景像素的二进制掩码。一般来说,自顶向下的方法是有效的,但当人包围框重叠时,会很难。
Bottom-up methods
自下而上的方法包括Pishchulin与DeepCut[37]和Insafutdinov与DeeperCut[21]的开创性工作。它们解决了与整数线性程序的零件关联,该程序导致单个图像的处理时间为小时。后来的工作加快了预测时间[5]并拓宽了跟踪动物行为的应用。其他方法通过使用贪婪解码器与其他工具相结合大大减少了预测时间,Part Affinity Fields,Associate Embedding PersonLab。最近,MultiPoseNet[24]开发了一种将检测、分割和姿态估计相结合的多任务学习体系结构。其他中间表示已经建立在图像平面上的二维姿态估计之上,包括三维姿态估计[29]、视频中的人体姿态估计[36]和密集姿态估计[16],这些都将从改进的二维姿态估计中获益。
3.Method
关节的定义
过早时期,谷歌提出直接对关键点做回归,通过多次迭代校准关键点的定位(x,y),这样定位还是不是很准确,后来的方法都是基于关键点热力图,将一个关键点
Ground True坐标周围半径R内区域都设为1,之外的区域设为0,转化为分类问题。

我们的方法的目的是估计人在拥挤的图像中的姿势。我们处理与低分辨率和部分闭塞行人有关的挑战。自顶向下的方法,特别是当行人被其他行人遮挡时,bounding boxs 发生碰撞。以前的自下而上方法是无边框的,但仍然包含用于定位的粗特征映射。 我们的方法不受任何基于网格的关节空间定位约束,并且具有估计相互遮挡的多个姿态的能力。
图2显示了我们的总体模型。它是一个共享的ResNet[19]基础网络,有两个头部网络:一个头部网络预测关节的置信度、精确位置和大小,我们称之为部件强度场(PIF),另一个头部网络预测部件之间的关联,称为部件关联场(PAF)。 我们把我们的方法称为PifPaf。在详细描述每个头部网络之前,我们简要地定义了我们的字段表示法。

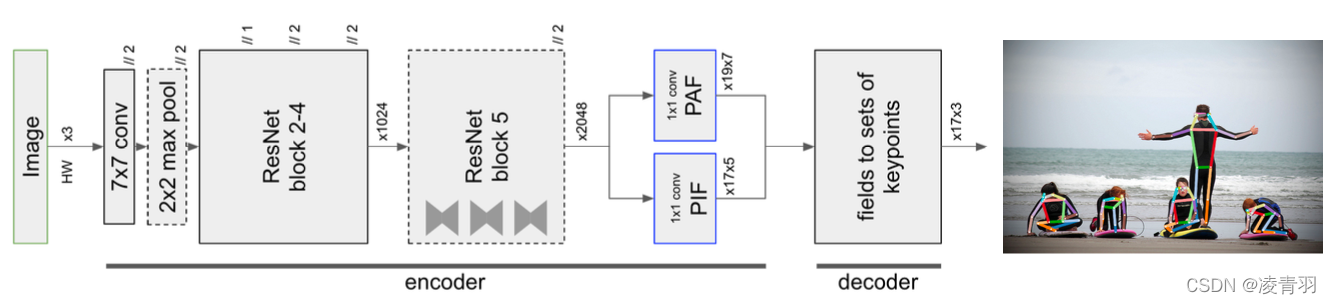
3.1. Field Notation

Filed是解释图像顶部结构的有用工具。复合场的概念直接激励了我们提出的Part Association Fields。我们将使用i,j在空间上枚举神经网络的输出位置,x,y为实值坐标。在域上用
表示一个场,并且可以具有同域(codomain)(场的值)标量、向量或复合场。例如,一个标量场
和向量场
的组合可以表示为
,这相当于用向量场“覆盖(overlaying)”置信映射。
3.2. Part Intensity Fields
Part Intensity Fields (PIF) 检测和精准定位身体部位。[35]介绍了一种用于关键点检测的置信图与回归的融合方法。在这里,我们用复合场的语言重述这种技术,并添加一个规模σ作为一个新的组件来形成我们的PIF场。
PIF具有复合结构。它们由用于置信度的标量分量、指向特定类型中最接近的主体部分的向量分量和用于关节大小的另一个标量分量组成。即在每个输出位置(i,j),PIF可以表示一个置信度c、一个带扩展b的向量(x,y)(第3.4节中的详细信息)和一个标度σ可以,写作。
Pif label是confidence map和regression map的结合, 最早出现在Google发表在CVPR 2017的"Towards Accurate Multi-person Pose Estimation in the Wild". 在Google的这篇文章中, Piflabel只有三个值: confidence score, x offset, y offset. PifPaf文章对这个Pif label进行了扩充, 增加了额外的两个选项: spread b, scale. 具体来说, 就是对于输出的PIF label,是一个(b, h, w, 17, 5)的输出, 17代表需要预测的关键点个数, 5表示: . 也即是,
PIF会预测出每个输出channel上每个位置的, 其中
表示该点的confidence,
和
表示该点的
x_offset和y_offset, 是用来参与loss计算的参数,
用来表示该点的尺度信息, 在生成
pif label的过程中, 人越大, j越大.

有个这个Pif label, 就可以根据 和
、
得到位置精度更高的confidence map. 下图展示了这个过程, (a)是
Pif label里的 , (b)是
和
, (c)是三者融合之后的结果. 可以看出来点的位置更精确, 中心处的响应值更高, 边缘处更低.
PIF的置信度图非常粗糙。图3a显示了用于示例图像的左肩的置信度图。为了改进这个置信图的定位,我们将它与图3b所示的PIF的矢量部分融合成一个高分辨率的置信图。

这个方程强调了无网格定位的性质。
关节的空间范围σ是作为领域的一部分学习的。一个例子如图3c所示。产生的高度局部化关节的特征图用来姿态生成和新关节的评分。

得到(c)的的结果, 通过一个unnormalized Gaussian kernel N 和 来确定新的confidence map:
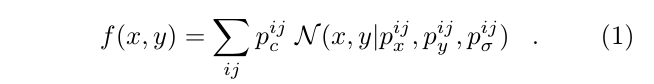
这个kernel和Google CVPR 2017那篇文章采用的bilinear interpolation kernel一直搞不清楚是啥. 看源码中这个unnormalized Gaussian kernel就是对pif label做functional.pyx 里的 scalar_suare_add_gauss操作, 这个操作是把pif里面的值都返回到原图输入大小来做的. 具体步骤大概就是针对原来位置上的点, 以这个点为中心取一定的范围, 然后求得范围内的点的offset, 然后做一个高斯核的操作, 最后把这个值和原来的值相加得到最后的 f(x,y).
# for minxx, minyy, maxxx, maxyy, vv in zip(minx, miny, maxx, maxy, v):
for i in range(l):
# x[i], y[i]就是 pif_fields的offset, l是长度, 这个长度应该就是究竟有多少个点需要参与运算
for xx in range(minx[i], maxx[i]):
deltax = xx - x[i]
for yy in range(miny[i], maxy[i]):
deltay = yy - y[i]
vv = v[i] * exp(-0.5 * (deltax**2 + deltay**2) / sigma[i]**2)
field[yy, xx] += vv
Pif label的生成过程是首先划定好每个groundtruth point的表示范围. 源码中是默认设置为4, 即已groundtruth point为中心左右上下各2个像素, 这个范围内的,j全为1, 其余地方为0. 同样是在这个范围内, 计算每个位置到
groundtruth point的x_offset, y_offset.
3.2.1. 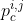 的作用
的作用
在PIF中代表点(i,j)是否是关键点的置信度,用来判断关键点,在PAF里面用来衡量两点的关联性大小
3.2.2. 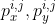 的作用
的作用
有了这个PIF label,就可以根据 得到位置精度更高的
confidence map,公式如下:
公式展开就是
在理解这个公式之前,先看一下《Towards Accurate Multi-person Pose Estimation in the Wild》文章的公式:
:表示
热力图(半径R区域)内的其他关键点的热力图
:表示第k个关键点
:表示当前点
:表示和
:表示
这个公式离说明,特征图上的点越小,因为是高斯函数,所以计算得到的权重G就越大,说明对计算的
的贡献越大,这也符合逻辑


同样的,本篇论文的公式也是表示越近的点权重越大,只不过距离是offset与(x,y)的距离。所以这就是为什么相近的offset(图像种的箭头)方向很接近,远的相差远,呈现渐变的感觉:

- 图(a)是
PIFlabel里的 - 图(b)是PIF预测的结果
offset:,放大后可以看出方向是渐变的,相近的向量方向相近,不仔细分析注意不到这点
- 图(c)是三者融合之后的结果. 可以看出来点的位置更精确, 中心处的响应值更强, 边缘处更弱
3.2.3. 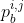 的作用
的作用
用来控制同一张图片上不同大小的目标物的关键点热力图(Heatmap)大小(大的物体,关键点热力图区域就应该大),文章中半径为3σ,loss函数如下:![]()
作为指数函数的幂次,就是
,所以
拓展: 《Rethinking the Heatmap Regression for Bottom-up Human Pose Estimation》论文中也考虑了不同Scale目标应该有不同大小热力图的问题
区别是,文章Scale-Adaptive Heatmap Regression采用增加一个分支去计算Scale maps,得到不同Scale的目标应该有的热力图大小,对预测的Heatmaps重加权;因为Scale maps会导致到特征图出现形变,所以在Loss里面加了正则项:Scale-Adaptive Heatmap Regression会导致背景数量减少,前景和背景样本不均衡,所以加了Weight-Adaptive HeatmapRegression:
就是借鉴Focal Loss处理类别不均衡和难易样本不均衡问题
想了解详细,可以去知乎看作者的讲解:CVPR 2021 论文解读Vol.7 | “自底向上”人体姿态估计的尺度自适应方法



3.2.4. 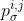 的作用
的作用
:不是高斯的 σ , 是用来将特征图还原到原图进行处理的比例系数,论文里没有详细说明,但是代码(
openpifpaf-main/src/openpifpaf/csrc/src/cif_hr.cpp)中可以看出:
void CifHr::accumulate(const torch::Tensor& cif_field, int64_t stride, double min_scale, double factor) {
if (ablation_skip) return;
auto cif_field_a = cif_field.accessor<float, 4>();
float min_scale_f = min_scale / stride;
float v, x, y, scale, sigma;
for (int64_t f=0; f < cif_field_a.size(0); f++) {
for (int64_t j=0; j < cif_field_a.size(2); j++) {
for (int64_t i=0; i < cif_field_a.size(3); i++) {
v = cif_field_a[f][1][j][i];
if (v < threshold) continue;
scale = cif_field_a[f][4][j][i]; // 每个点(j,i)的scale不一样,相当于权重
if (scale < min_scale_f) continue;
x = cif_field_a[f][2][j][i] * stride;
y = cif_field_a[f][3][j][i] * stride;
sigma = fmaxf(1.0, 0.5 * scale * stride); // 通过stride还原到原图尺寸,scale可以学习的参数
// Occupancy covers 2sigma.
// Restrict this accumulation to 1sigma so that seeds for the same joint
// are properly suppressed.
add_gauss(f, v / neighbors * factor, x, y, sigma, 1.0);
}
}
}
}
void CifHr::add_gauss(int64_t f, float v, float x, float y, float sigma, float truncate) {
auto accumulated_a = accumulated.accessor<float, 3>();
auto minx = std::clamp(int64_t(x - truncate * sigma), int64_t(0), accumulated_a.size(2) - 1); //x < truncate * sigma,等于0
auto miny = std::clamp(int64_t(y - truncate * sigma), int64_t(0), accumulated_a.size(1) - 1);
// -siga < x < sigma -> minx=0 -> x + sigma + 1 > 0 + 1 -> maxx = x + sigma + 1 (0, x + sigma + 1)
// x < -sigma -> minx=0 -> x + sigma + 1 < 0 + 1 -> maxx = min + 1 = 1 (0, 1)
// x > sigma -> minx= x - sigma -> x + sigma + 1 > x - sigma + 1 -> maxx = x + sigma + 1 (x - sigma, x + sigma + 1 || accumulated_a.size(1) - 1)
auto maxx = std::clamp(int64_t(x + truncate * sigma + 1), minx + 1, accumulated_a.size(2));
auto maxy = std::clamp(int64_t(y + truncate * sigma + 1), miny + 1, accumulated_a.size(1));
float sigma2 = sigma * sigma;
float truncate2_sigma2 = truncate * truncate * sigma2;
float deltax2, deltay2;
float vv;
for (int64_t xx=minx; xx < maxx; xx++) {
// x < -sigma -> xx = x = 0 -> deltax2 = 0
deltax2 = (xx - x) * (xx - x);
for (int64_t yy=miny; yy < maxy; yy++) {
deltay2 = (yy - y) * (yy - y);
if (deltax2 + deltay2 > truncate2_sigma2) continue;
if (deltax2 < 0.25 && deltay2 < 0.25) {
// this is the closest pixel
vv = v;
} else {
vv = v * approx_exp(-0.5 * (deltax2 + deltay2) / sigma2);
}
auto& entry = accumulated_a[f][yy][xx];
entry = fmaxf(entry, revision) + vv;
entry = fminf(entry, revision + 1.0);
}
}
}
cif_field_a[f][1][j][i]:cif_field_a[f][2][j][i]、cif_field_a[f][3][j][i]:cif_field_a[f][4][j][i]:
3.3. Part Association Fields
将关节组合成多个姿势在拥挤的场景中是很有挑战性的,在这些场景中,人们部分地相互遮挡。尤其是两个步骤——自上而下的方法——在这种情况下的挑战:首先,他们检测人bounding boxes,然后他们试图为每个bounding boxes找到一个关节类型。自下而上的方法是无边框的,因此不受边框冲突问题的影响。

我们提出自下而上的部件关联场(PAF),以连接在一起的位置成姿势。 图4显示了PAF方案的说明。 在每个输出位置,PAFS预测一个置信度,两个向量到这个关联连接的两个部分,两个宽度b(详见3.4节),用于回归的空间精度。
PAFs表示:![]() 。
。
类似于Pif label, Paf label部分的输出是(b, h, w, 17, 7)。
- 17是需要预测的关键点个数;
- 7代表
。
代表位置(i,j)的confidence;
分别表示该点到真正的两个关节点groundtruth point 的(x_offset, y_offset);
是相对应的两个用来计算loss的系数,宽度因子
生成featuremap某个位置上的PAF components步骤需要两步:
1) 找到离该位置最近的一个点.
2) 一旦一个点确定, 根据groundtruth, 我们就能确定另外一个点的位置从而确定
PAF值.
例如我们需要生成头-脖子这个连接, 那么对于某个位置(i,j), 首先找到离它最近的头部点或者脖子点, 假设我们找到了一个离它最近的头部点, 那么根据groundtruth, 我们知道和这个头部点应该相连的脖子点是哪个, 就可以确定 了.
并不在
Paf label中, 而是网络预测出来的, 通过参与loss计算自动的修改这个值.
左肩和左髋关节之间的关联可视化如图5所示。

图5、PAF组件的可视化,该组件将左肩与左臀部关节关联
【这是19个PAF之一。 特征图的每个位置都是两个向量的起点,它们指向要关联的肩膀和臀部。 在(a)中显示了关联ac的置信度,在(b)中显示了ac> 0.5的向量分量。】
这两个端点都是局部化的,回归不受离散化的影响,因为它们发生在基于网格的方法中。这有助于准确地解决近距离人员的联合位置,并将其解析为不同的annotations。
在COCO数据集中,Person类有19个连接,每个连接两种类型的连接。例如,有一个右膝对右踝连接。在特定特征映射位置构造PAF组件的算法包括两个步骤。首先,找到两种类型中任何一种最接近的关节,它决定了向量分量之一。第二,ground truth姿态决定表示关联的另一个向量分量,第二个关节不一定是最接近的,可以很远。
在训练时,fileds的组件必须指向应该关联的部分。类似于向量场的x分量总是指向与y分量相同的目标,PAF场的分量必须指向相同的部分关联。

3.4. Loss 计算
文章使用的Loss计算分为三类:
- 二分类loss, 使用
binary_cross_entropy_with_logits计算该点是不是有可能是Pif上的关键点或者Paf上的连接处, 就是计算和
.
- 回归loss, 使用
laplace_loss计算pif, paf里的offset. 其中用到了pif paf预测出来的, 计算公式:
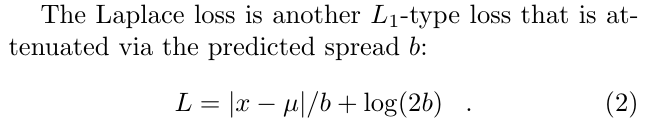
- scale loss. 使用
torch.nn.functional.l1_loss计算pif的.
三种loss加在一起就是整个网络的总Loss.
Adaptive Regression Loss
人类姿态估计算法往往与人类姿态在图像中所能具有的尺度的多样性作斗争。虽然一个大的人的关节的定位错误可能很小,但同样的绝对错误可能是一个小的人的主要错误。我们使用L1型损失来训练回归输出。我们通过在回归损失(SmoothL1 or Laplace loss )中注入尺度依赖来提高网络的定位能力。光滑的L1损失允许调整半径r光滑周围的原点,在那里它产生更软的梯度。


3.5. Greedy Decoding
得到PIF和PAF后,为了确保根据PAF找到的两个点确实是应该连到一起的, 程序会执行reverse操作, 即如果通过point a找到了point b, 那么就会从point b找到point c, 如果point a和point c之间的距离小于设定好的阈值, 那么就说明这两个点应该被连在一起. 计算出来哪些点需要连在一起之后, 然后通过NMS方式将多连接的线去除掉,直到完整的pose被找到。
Greedy Decoding 也就是组装算法
这里的话,比如选择从头顶开始,那么会选择整个图中置信度最高的那个头开始,然后利用paf把这个joint 连到下一个joint,直到把这个人组装好了,这个人就定下来了。然后选择下一个头,再来一遍。
那么对于某个joint ,如何去利用paf?
对于向量X,利用上面这个公式,能给每个paf 的预测向量打分,当然是选择分最高那个。
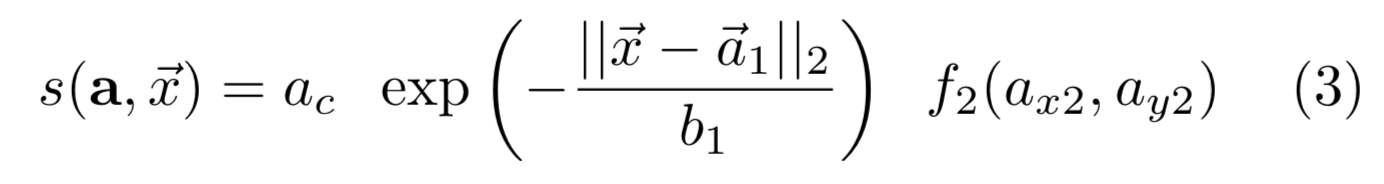
解码是将神经网络的输出特征映射转换成17个坐标集来进行人体姿态估计的过程。我们的过程类似于快速贪婪解码。一个新的姿态是由PIF向量seed的高分辨率置信图f(x,y)在方程1中的最高值。从seed开始,与其他关节的连接是在PAF场的帮助下添加的。算法快速,贪婪。一旦连接到一个新的关节,这个决定是最终的。
多个PAF关联可以在当前关节和下一个关节之间形成连接。给定起始关节的位置 ,可以用以下公式计算通过PAF关联a的分数s,最后选择分最高的。
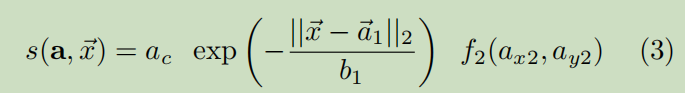
其中考虑了该连接AC的置信度、用双尾拉普拉斯分布概率校准的第一向量位置的距离和第二向量目标位置f2的高分辨率部分置信度。为了确认新关节的propose位置,我们运行反向匹配。这个过程被重复,直到得到一个完整的姿态。我们在关键点级别应用非极大抑制。抑制半径是动态的,基于PIF场的预测尺度分量。训练和测试期间,我们不会改进任何fields。
找到了点, 也找到了合适的连接线段, 那么需要把同属于同一个人的线段都连起来. 文章使用了PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model使用的Greedy decoding方法来做. 具体来说, 首先根据输出的Paf信息重新计算每个连接线段的score值, 计算方式为: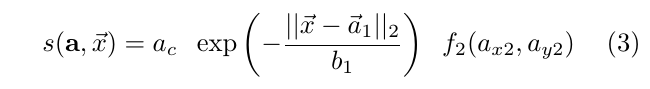
就是
paf里的 ,
就是公式(1)计算得到的新的confidence map;
分别表示
paf信息的. 因为根据文章的方法, 两个应该连接的关键点之间会有几处点用来连接两个点, 就像图4(b)一样, 两个点之间会有一个点(或者多个点,
paf label生成的时候默认三个点或者一个点, 选择方式是两点之间的[0.4, 0.5, 0.6]或者只有[0.5]offset). 再确定一个点之后, 会采用target_with_median or target_with_maxscore方法其中一个来确定另外一个连接点, 这样就找到了另外一个关节点.因为在确定一个点之后, 它对应的paf_fields就可以找到.
首先计算出连接这个点的所有线段的score, target_with_median的意思就是计算剩下的paf_fields的x,y坐标和这个线段的score相乘求平均, 得到一个target x, y. 以下图为例, 就是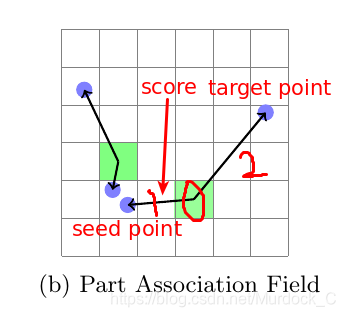
先找到线段1的score:
target_with_median就是和2做平均, (x, y)和score相乘然后求平均, 就是target point 的(x, y)target_with_max就是找到1中最大的score所处的位置, 直接取对应的线段2的点的值,就是target point的(x,y)
为了确保根据paf找到的两个点确实是应该连到一起的, 程序会执行reverse操作, 即如果通过point a找到了point b, 那么就会从point b找到point c, 如果point a和point c之间的距离小于设定好的阈值, 那么就说明这两个点应该被连在一起. 计算出来哪些点需要连在一起之后, 从随机的一个点出发作为种子点, 然后去找和它连接的最大可能性的线段的点, 持续的进行下去, 直到一个完整的pose被找到或者没有满足条件的点为止.
4.Experiments




5.Conclusions
我们开发了一种新的自下而上的多人2D人体姿态估计方法,该方法解决了在交通领域特别普遍的故障模式,即在自动驾驶汽车和社交机器人中。我们证明了我们的方法在低分辨率的情况下优于以前最先进的方法,并且在高分辨率下的性能是标准的。所提出的PAF字段也可以应用于其他任务。在图像域内,预测结构化图像概念是令人兴奋的下一步。