0 - 背景
Facebook AI Research(FAIR)开源了一项将2D的RGB图像的所有人体像素实时映射到3D模型的技术(DensePose)。支持户外和穿着宽松衣服的对象识别,支持多人同时识别,并且实时性良好。
1 - 思路
1.1 - 标注数据集
对于一般的姿态识别(骨骼追踪),能够识别出一二十个点便可以构成一个人体姿态,但如果要构造出一个平滑的3D模型,则需要更多的关键点,DensePose需要336个(24个部位,每个部位14个点)。
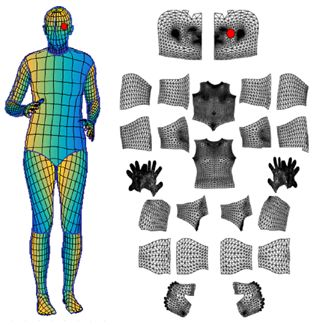


同时要求注释者在标记的时候要标出被衣物掩盖住的部位,比如宽松的裙子。

上述工作进行之后,研究人员对每一个展开部位区域进行采样,会获得6个不同视角的标记图,提供二维坐标图使标记者更直观的判断哪个标记是正确的。

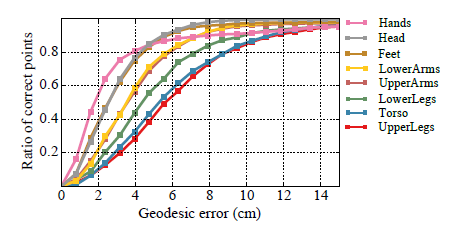
最后将平面重新组合成3D模型,进行最后一步校准。这样下来,可以以高效准确的方式获得准确标记的数据集。各部位错误率如下,可以看到在躯干、背部和臀部存在较大误差。
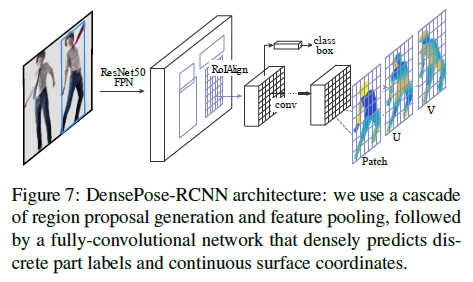
1.2 - 模型
1.2.1 - Fully-convolutional dense pose regression

1.2.2 - Region-based Dense Pose Regression

1.3 - 效果