什么是ID3决策树
- 使用决策树来处理分类问题, 同时也是经常使用的数据挖掘算法
- 输入测试集, 不断推断分解, 逐步缩小待猜测事物的范围, 划分出最优数据子集
- 将无序的数据变得更加有序
- 一次只选一个特征去划分最优数据子集
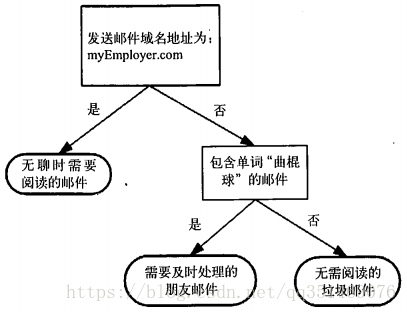
上面的图片就是决策树的最终展现图
优点
- 不需要了解算法
- 时间复杂度不高
- 数据易于展现
- 可以处理不相关特征
缺点:
- 可能会产生过度匹配, 会把没用的特征值全部展现出来
适用数据类型: 标称型
决策树术语


从判断模块引出的左右箭头称作分支
原始香农熵: 表示数据的无序程度,混合的数据越多, 熵越高 公式为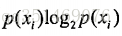
信息增益: 在划分数据集之前之后信息发生变化叫做信息增益, 具体是累加原始香农熵, 计算出信息增益值, 熵越高, 信息增益值越低, 公式为
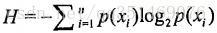
本人归纳:
- 找出划分数据集起决定性作用的特征, 接着划分出最优的数据子集
- 如果某个分支下的数据属于同一类型, 则该节点称为叶子结点, 不需要在划分数据子集
- 如果不属于同一类型, 则需要重复划分数据子集
- 要构造决策树, 就必须知道哪个特征在划分数据子集时起决定性作用, 每次评估一个特征(计算数据无序程度), 通过评估每个特征的熵(计算信息增益), 划分出最优子集, 把最优子集用可视化的方式展现出来就是决策树, 如果特征消耗完了,类别依然不是唯一, 最终会通过多数表决的方式决定叶子节点的分类
具体:
1. 选出起决定性作用的特征, 去重特征那列的值, 遍历不重复特征值, 划分出最优子集, 递归