决策树的概念
决策树是大数据技术进行分类和预测的一种,决策树学习是一种基于实例归纳学习算法,它主要从一组无次序、无规则的实例中推理出以决策树所代表分类规则。它采用从上向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶节点得到结论。
为了理解决策树的概念,下面举个例子说明:
表1.银行贷款者历史数据

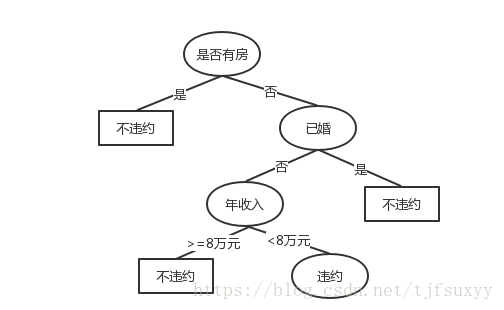
银行依据上表的银行贷款者历史数据构建如下图的决策树,假设有一笔新的贷款客户信息:没有房子、单身、年收入9万元,银行根据决策树首先对这位客户进行了解“是否有房”,没有房子就从上往下的右边“已婚”走,然后继续了解是否结婚。还是单身没有结婚就从上往下的左边“年收入”走。最后了解客户的年收入是否大于8万元,9万元是大于8万元的,最后在叶节点结论看到“不违约”。银行就可以预测客户相对会有违约情况发生可能性较低,所以可以决定贷款给客户。
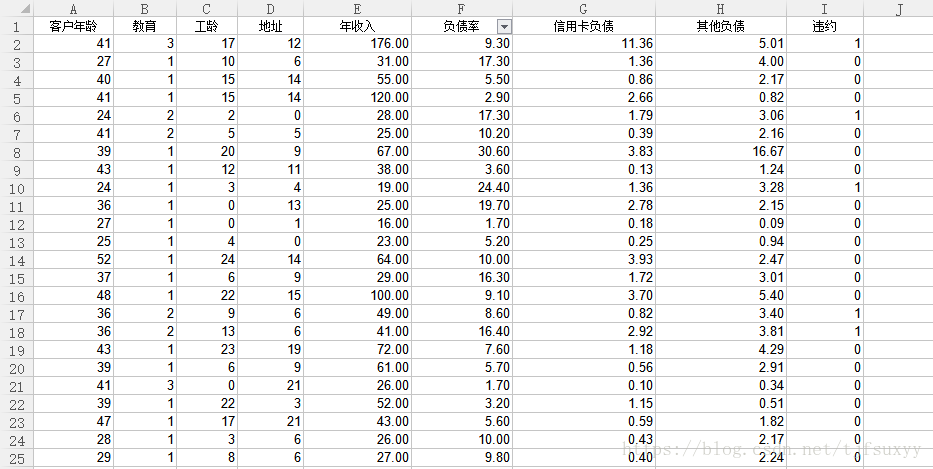
我们现有一笔2017年某银行的客户信息和违约情况经数据处理后,如下图所示,共计700条数据。
表2.2017年某银行历史数据
通过Anaconda3软件对上面数据进行分析,运行下面的代码
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
from sklearn.linear_model import RandomizedLogisticRegression as RLR
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
import pydotplus
from IPython.display import Image
if __name__ == "__main__":
# 取出数据
data = pd.read_excel("C:/2018/2017myjb.xlsx")
x = data.iloc[:, :8].as_matrix()
y = data.iloc[:, 8].as_matrix()
# 筛选特征值
rlr = RLR()
rlr.fit(x, y)
rlr_support = rlr.get_support()
support_col = data.drop('违约', axis=1).columns[rlr_support]
x = data[support_col].as_matrix()
# 建立决策树模型
clf = DTC()
clf = clf.fit(x, y)
dot_data = StringIO()
export_graphviz(clf)
dot_data = StringIO()
export_graphviz(
clf,
out_file=dot_data,
class_names=support_col,
filled=True,
rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
# 写入pdf
graph.write_pdf('c:/2018/bankload_tree.pdf')运行代码过程中,可能会出现这样的问题,是因为我们电脑没有安装GraphViz软件,无法将输出结果转换成pdf。

图2
图3
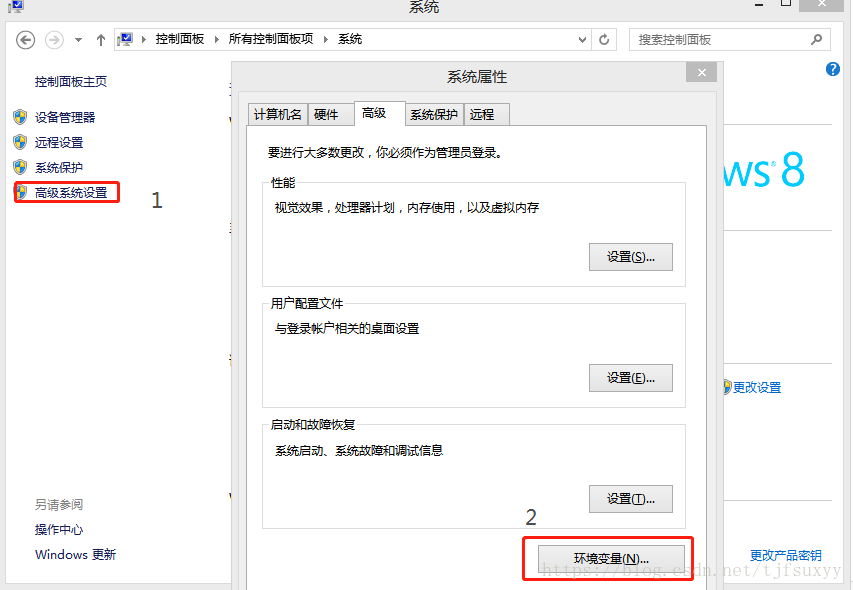
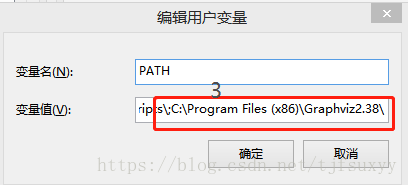
2.将安装软件的目录记下,如C:\Program Files (x86)\Graphviz2.38\
图4
3.将GraphViz的安装目录添加到环境变量path里
我们将获得下图的pdf,获得pdf无法显示其中的中文 ,还需要配置一些其他东西,比较麻烦 。我们可以简单把其中文换英文进行分析。

因为处理2017年某银行历史数据量较大,我们可以看到构建的决策树从上向下的分支特别多。决策树模型和逻辑回归模型一样,模型从数据中获取的有效特征:工龄、地址、负债利、信用卡负债,并根据这根据这四个特征值构建上图的决策树。当有新的客户信息时,首先根据客户的“工龄”找到某银行决策树第一个节点“工龄”,然后进行客户“工龄”值与该节点“工龄”值比较之后确定往向下哪个分支走,重复操作最后在某银行决策树分支的叶末节点找到客户是否会有违约情况发生的结论。