决策树定义
决策树是一种多功能的机器学习算法,它可以实现分类和回归任务,甚至实现多输出任务。决策树简单来说就是带有判决规则(if-then)的一种树,可以依据树中的判决规则来预测未知样本的类别和值。
决策树是一种有监管学习的分类方法。决策树的生成算法有 ID3 、C4.5 和 CART(Classification And Regression Tree)等,CART的分类效果一般优于其他决策树。
决策树的决策过程需要从决策树的根节点开始,待测数据与决策树中的特征节点进行比较,并按照比较结果选择选择下一比较分支,直到叶子节点作为最终的决策结果。
通过iris来实现一个决策树,此处设置最大深度为2。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris=load_iris()
X=iris.data[:, 2:]
y=iris.target
tree_clf=DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)由于sklearn所采用的为CART形式,依照概率来估算类别
tree_clf.predict([[5, 1.5]])结果为:array([1])
tree_clf.predict_proba([[5, 1.5]])结果为:array([[0. , 0.90740741, 0.09259259]])
归于类别1的概率最大,所以认定为这种状态下为类别1的输出。由于sklearn中所采用的是CART决策树,通常使用基尼不纯度进行测量,同时,可以将其中的超参数如下设置。从而选择信息熵作为不纯度的测量方式。一般来说基尼不纯度计算相对快一些,更倾向于从树枝中分裂出最常见的类别,而信息熵更倾向于生产更平衡的树。
DecisionTreeClassifier(criterion="entropy")正则化超参数
决策树很少对训练数据作出假设,如果不加以限制,树的结构随训练集的变化而变化,很可能过度拟合。为了避免过拟合,需要在训练过程中降低决策树的自由度,这个过程被称为正则化。比如可以通过控制max_depth来实现模型正则化,从而降低过拟合的风险。
同样决策树中的其他参数也可以限制决策树的形状,比如min_samples_split(分裂前节点必须有的最小样本数), min_samples_leaf(叶结点必须有的最小样本数),min_weight_fraction_leaf(跟min_samples_leaf一样,表现为加权实例总数的占比),max_leaf_nodes(最大叶结点数),max_featurs(最大特征数)。降低max,或者增大min都能实现将模型正则化。
决策树的基本结构
根节点:内部节点的一种,只不过位置较为特殊;
内部节点:用于属性测试;
叶子节点:输出分类结果;
决策树一般流程:
1、收集数据
2、准备数据(数值型数据必须离散化)
3、分析数据
4、训练数据
5、学习数据,使用经验树计算错误率
构建决策树由以下三部分所构成 :
1、特征选择
2、决策树生成
3、决策树剪枝
特征选取阶段
为了解释清楚各个数学概念,引入例子
上表有15个样本数据表。数据包括贷款申请人的4个特征:年龄、有工作与否、有房子与否、信贷情况,其中最后一列类别的意思是:是否同意发放贷款,这个就是决策树最后要给出的结论,即目标属性——是否发放贷款,即决策树最末端的叶子节点只分成2类:同意发放贷款与不同意发放贷款。
信息熵(entropy)
信息熵是用来衡量一个随机变量出现的期望值。如果信息的不确定性越大,熵的值也就越大,出现的各种情况也就越多。
在这篇文章有详细介绍;
其中,D为所有事件集合,p为发生概率,c为特征总数。
注意:熵是以2进制位的个数来度量编码长度的,因此熵的最大值是。
其中pi表示第i个类别在整个训练数据中出现的概率,可以用属于此类别元素的数量除以训练数据(即样本数据)总数量作为估计。
具体问题具体分析:是否发放贷款,将9个发放归为一类,剩余6个不发放归为一类,这样进行分类的信息熵为:
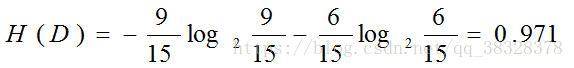
信息增益(information gain)
信息增益是指信息划分前后的熵的变化,也就是说由于使用这个属性分割样例而导致的期望熵降低。也就是说,信息增益就是原有信息熵与属性划分后信息熵(需要对划分后的信息熵取期望值)的差值,具体计算法如下:
:训练集中所有在属性a上取值为的样本的集合;
V:属性a所有可能的数量;
M:整个训练集的样本数量;
:
的样本数量
其中,第二项为属性a对D划分的期望信息。
信息增益率
定义
对于属性a来说,可取值数量越多,越大;
增益率:
具体问题具体分析
年龄为已知条件的条件熵为:
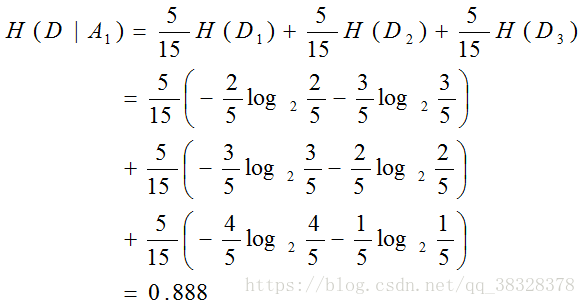
以年龄为条件的信息增益为:

有工作的信息增益:
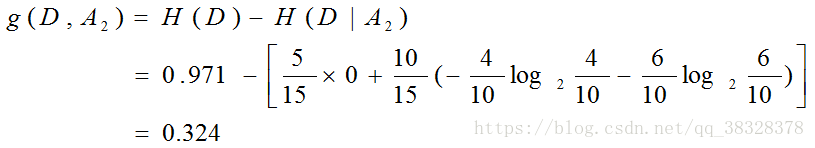
有房子的信息增益:
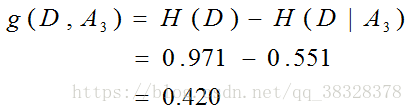
信贷情况的信息增益:

最后比较各特征的信息增益值,对于特征A3有自己房子的信息增益值最大,所以选择特征A3作为最优特征。
由于特征A3(有自己房子)的信息增益值最大,所以选择特征A3作为根节点的特征。它将训练数据集划分为两个子集D1(A3取值为是)和D2(A3取值为否)。由于D1只有同一类样本点,可以明确要贷款给D1,所以它成为一个叶节点,节点类标记为“是”。
对于D2则需要从特征A1(年龄),A2(有工作)和A4(信贷情况)中选择新的特征。计算各个特征的信息增益:

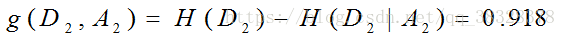
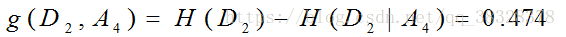
选择信息增益最大的特征A2(有工作)作为节点特征。A2有2个取值,一个对应“是”(有工作)的子节点,包含3个样本,他们属于同一类,所以这是一个叶节点,类标记为“是”;另一个对应“否”(无工作)的子节点,包含6个样本,属于同一类,这也是一个叶节点,类标记为“否”。
换句话有15个贷款人,经过是否有房这一筛选条件,有房子的6个人能够贷款。剩余9个人需要进一步筛选,以是否有工作为筛选条件,有工作的3个人可以贷款,无工作的6个人不能够贷款。
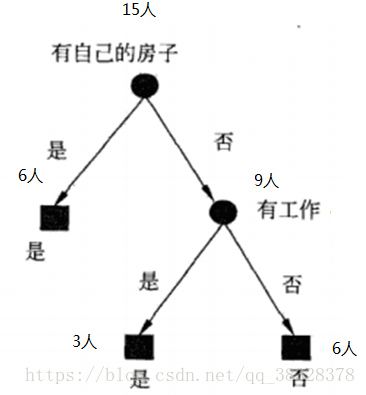
该决策树只用了两个特征(有两个内部结点),以有自己的房子作为首要判决条件,然后以有工作作为判决条件是否可以贷款。
决策树生成
决策树学习比较典型的有三种算法:ID3算法、 C4.5算法和CART算法。
1、ID3算法
ID3算法由Ross Quinlan发明,建立在“奥卡姆剃刀”的基础上:越是小型的决策树越优于大的决策树(be simple简单理论)。
ID3算法中根据信息增益评估和选择特征,每次选择信息增益最大的特征作为判断模块建立子结点。
ID3算法可用于划分标称型数据集,没有剪枝的过程,为了去除过度数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点(例如设置信息增益阀值)。
使用信息增益的话其实是有一个缺点,那就是它偏向于具有大量值的属性。就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性,而这样做有时候是没有意义的。
ID3算法步骤:

2、C4.5算法
C4.5算法用信息增益率来选择属性,继承了ID3算法的优点。并在以下几方面对ID3算法进行了改进:
用信息增益率来选择属性,克服了用信息增益选择属性偏向选择多值属性的不足;
在构造树的过程中进行剪枝;
能够完成对连续属性进行离散化;
能够对不完整的数据进行处理。
C4.5算法产生的分类规则易于理解、准确率较高;但效率低,因树构造过程中,需要对数据集进行多次的顺序扫描和排序。也是因为必须多次数据集扫描,C4.5只适合于能够驻留于内存的数据集。
在实现过程中,C4.5算法在结构与递归上与ID3完全相同,区别只在于选取决决策特征时的决策依据不同,二者都有贪心性质:即通过局部最优构造全局最优。
C4.5算法步骤:
3、CART算法
CART,即分类和回归树(classification and regression tree),也是一种应用很广泛的决策树学习方法。这是一种可以处理离散特征值和连续特征值的决策树,处理离散特征值使用分类决策树,处理连续特征值使用回归决策树。
作为分类树时,其本质与ID3、C4.5并有多大区别,只是选择特征的依据不同而已。另外,CART算法建立的决策树一般是二叉树,即特征值只有yes or no的情况(个人认为并不是绝对的,只是看实际需要)。当CART用作回归树时,以最小平方误差作为划分样本的依据。
基尼指数 (Gini)
分类树采用基尼指数选择最优特征。假设有K个类,样本点属于第k类的概率为pk,则概率分布的基尼指数定义为:
对于给定的样本集合D,其基尼指数为:
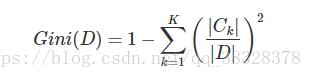
CART分类树的算法步骤:

决策树剪枝
决策树中的过拟合
决策树生成的过程有时候导致决策树的分支过多(分支过多意味着考虑了过多的边缘情况,边缘情况很多时候是由个体差异引起的),从而导致过拟合;
先剪枝:
决策树边生成边进行剪枝的操作;
在决策树生成的过程中,每个节点在划分之前先在验证集上进行一次测试,若当前节点的划分无法提高泛化性能,则不做划分处理,直接将此节点作为叶子节点(使得一些分支不能展开,降低了过拟合)。
过程说明:
1.属性A是否应该被划分?
2.不划分,那么A就成为叶子节点,此时在验证集上测试,得到精度a;
3.划分,在验证集上测试,得到精度b;
4.若b>a,就划分;否则不划分;
后剪枝:
决策树完全生长之后才开始剪枝,并且是自下向上的进行;
过程说明:
1.记完全生成后的决策树在验证集上的精度为a0;
2.从最深的内部节点 开始;
3.判断该内部节点若不进行剪枝的情况在验证集上的精度,记为a1;
4.若a1>a0,则进行剪枝;
5.记a0=a1;
6.重复执行第3步到第6步,直到所有内部节点 都遍历;
其中C4.5算法使用悲观剪枝方法(先剪枝),CART算法则为代价复杂度剪枝算法(后剪枝)。悲观剪枝法的基本思路是:设训练集生成的决策树是T,用T来分类训练集中的N的元组,设K为到达某个叶子节点的元组个数,其中分类错误地个数为J。由于树T是由训练集生成的,是适合训练集的,因此J/K不能可信地估计错误率。所以用(J+0.5)/K来表示。
剪枝的过程是通过极小化决策树整体损失函数来实现的。假设树的叶节点数为|T|,t是树T 的叶节点,该叶节点上有Nt 个样本点,其中属于kk类的样本点有Ntk 个,Ht(T 为叶节点的经验熵α≥0 为参数。则决策树学习的整体损失函数可以定义为: 
其中C(T) 表示模型对训练数据的预测误差,|T| 表示模型的复杂度,参α≥0 控制两者之间的影响,当α 较大时,促使模型变得简单,α=0 时表示模型损失函数只与训练数据集拟合程度相关,与模型复杂度无关。
决策树的剪枝,就是在α确定时,选择损失函数最小的决策树。当α确定时,子树越大,模型复杂度越高,往往与训练数据拟合越好,但是在未知数据集上表现可能会较差;相反,子树越小,模型复杂度越低,训练数据拟合不好,但是泛化能力好。
一些小问题:
1.通常来说,字节点基尼不纯度低于父结点。但是如果字节点之间基尼不纯度差距过大,会导致子结点大于父节点,但是基尼不纯度之和还是会小于父节点
2.决策树的一个优点就是他并不关心数据是否缩放或者集中,因此如果拟合不足的话缩放输入特征反而浪费时间。