CrossKD: Cross-Head Knowledge Distillation for Dense Object Detection, arXiv2306
论文:https://arxiv.org/abs/2306.11369
代码:https://github.com/jbwang1997/CrossKD
解读:学生模型反超老师模型?简单高效的蒸馏机制CrossKD:超越现有所有知识蒸馏方案! - 知乎 (zhihu.com)
模型落地必备 | 南开大学提出CrossKD蒸馏方法,同时兼顾特征和预测级别的信息 - 知乎 (zhihu.com)
摘要
知识蒸馏(KD)已被验证为一种有效的学习压缩对象检测器的模型压缩技术。现有的最先进的目标检测KD方法大多基于特征模拟,通常观察到这比预测模拟更好。本文发现,GT信号和蒸馏目标之间的优化目标不一致是预测模拟效率低下的关键原因。
为了缓解这个问题,论文提出一种简单而有效的蒸馏机制 CrossKD,它将学生模型检测头的中间特征传递给教师模型检测头,并强制使交叉头的预测与教师模型的预测保持一致。通过这种蒸馏方式,学生模型的检测头能够避免接收来自GT注释和教师模型预测的相互矛盾的监督信号,从而大大提高了学生模型的检测性能。
在MS COCO数据集上,仅应用预测蒸馏损失,作者的CrossKD将GFL ResNet-50模型的平均精度从40.2提升到43.7,超过了所有现有的目标检测领域的知识蒸馏方法。
简介
背景知识
根据蒸馏位置的不同,现有的知识蒸馏方法可以大致分为两类:
- 预测模拟 prediction mimicking (预测蒸馏)
- 特征模仿 feature imitation (特征蒸馏)
理解为分别从两个层面来进行蒸馏:预测结果层面 和 中间特征层面。

- 预测模拟(见图1(a)),指出教师的预测结果的平滑分布对学生的学习更有利,而不是GT值的Dirac分布。预测模拟旨在最小化老师模型与学生模型之间的预测差异。

其中,分别表示学生模型与老师模型的预测结果,而区域选择准则
随方案随变化,
则用于度量预测之间的差异,如用于分类的KL散度、用于回归的L1、LD。
由于预测具有明确的物理含义,预测蒸馏可以向学生提供特定任务的知识。然而,与特征蒸馏方法相比,预测蒸馏的性能较差限制了其应用。
- 特征模仿(见图1(b)),认为中间特征包含的信息比教师的预测结果更多。特征模仿旨在增强老师-学生模型在隐特征方面的一致性。

其中,分别表示学生模型与老师模型的中间特征,通常为FPN输出特征。
用于度量特征之间的距离,如MSE、PCC(Pearson Correlation Coefficient)。
表示区域选择原则,它在整个图像区域R中为每个位置r生成一个权重。为了避免大幅度的噪声干扰模型的收敛性,不同的方法可能会使用不同的区域选择原则
来选择用于蒸馏的有效区域,并平衡前景和背景样本的权重。最后,损失将通过整个中间特征上的
的累积|S|进行归一化处理。
特征蒸馏由于其出色的性能已经成为目标检测知识蒸馏方法的主流。然而,这可能强迫学生模型蒸馏教师模型中的不必要的噪声,这可能对最终结果产生负面影响。
出发点
预测蒸馏在蒸馏目标检测模型中起着至关重要的作用。然而,长期以来观察到预测蒸馏比特征蒸馏更低效。局部化蒸馏(LD),通过传递定位知识来改进预测蒸馏。LD表明预测蒸馏具有传递任务特定知识的能力,这使得学生模型能够从与特征蒸馏不同的角度受益。

作者通过观察发现,预测蒸馏需要应对GT目标和蒸馏目标之间的冲突,而这在先前的工作中被忽视了。当通过预测模拟方式进行训练时,学生模型的预测被迫同时最小化与两者之间的差异,进而影响了学生模型的性能。然而,教师模型预测的蒸馏目标通常与分配给学生模型的GT目标存在很大的差异。
如图2所示,教师模型在绿色圈出的区域中产生了不准确的类别概率,这与GT目标产生了冲突。因此,在蒸馏过程中,学生模型经历了一种矛盾的学习过程,作者认为这是阻碍预测蒸馏实现更高性能的主要原因。
贡献
于是,论文提出了一种新颖的交叉检测头的知识蒸馏方法,称为CrossKD,以缓解目标冲突问题。如图1(c)所示,将学生模型检测头的中间特征输入到教师模型检测头中,得到交叉检测头的预测。然后,在新的交叉检测头的预测和教师模型的原始预测之间进行知识蒸馏操作。
CrossKD具有两个主要优势:
- 知识蒸馏损失不会影响学生模型Head的权重更新,避免了原始检测损失和知识蒸馏损失之间的冲突。
- 由于交叉Head预测和教师模型的预测都是通过共享部分教师模型的检测Head生成的,因此交叉Head预测与教师模型的预测相对一致。这减轻了教师-学生对之间的差异,增强了预测蒸馏的训练稳定性。
这两个优势使得作者的CrossKD能够高效地从教师模型的预测中提取知识,并且比先前最先进的特征蒸馏方法具有更好的性能。
CrossKD 方法
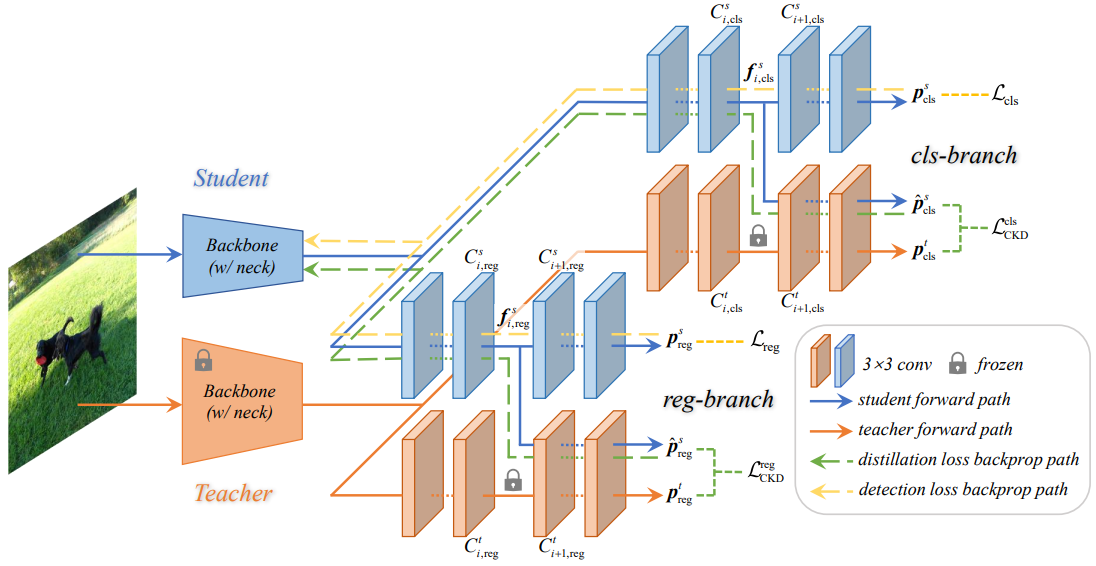

直接蒸馏教师的预测会面临目标冲突问题,这妨碍了预测蒸馏方法取得良好的性能。为了缓解这个问题,本节提出一种新颖的交叉Head知识蒸馏(CrossKD)方法。总体框架如图3所示。与已有预测蒸馏方法类似,CrossKD直接对预测输出进行蒸馏。不同的是,CrossKD将学生的中间特征传递给教师的检测头,并生成交叉头预测以进行蒸馏。
Cross-Head Knowledge Distillation
以稠密检测器(如RetinaNet)为例,每个检测头通常由多个卷积层构成,表示为。为简单起见,假设每个检测头有n个卷积,如RetinaNet的检测头有5个卷积,4个隐层+1个预测层。采用
表示
输出的特征,
是
的输入,预测 p则通过最后的卷积
生成。因此,对于给定的教师-学生对,其预测分别表示为
。
此外,CrossKD额外将学生模型的中间特征送入到教师模型检测头的卷积层
中以生成交叉头预测
。此时,并不计算
之间的蒸馏损失,而是计算
之间的蒸馏损失KD loss。CrossKD的优化目标描述如下:

其中,S(·)和|S|分别表示区域选择原则和归一化因子。为了避免设计复杂的S(·),作者遵循训练密集检测器的默认操作。在分类分支中,S(·)是一个恒定函数,其值为1。在回归分支中,S(·)是指示符,在前景区域生成1,在背景区域生成0。根据每个分支的不同任务(例如分类或回归),使用不同类型的来有效地将特定于任务的知识传递给学生。
通过CrossKD,检测损失与蒸馏损失将独立作用到不同的分支。图3所示:检测损失的梯度通过学生的整个Head传递,而蒸馏损失的梯度通过冻结的教师层传播到学生的潜在特征上,从而在启发式上增加了教师和学生之间的一致性。与直接对教师-学生对之间的预测进行调整相比,CrossKD允许学生的一部分检测头仅与检测损失相关,从而更好地优化GT目标。
优化目标
训练的总损失可以表示为检测损失和蒸馏损失的加权和,如下所示:

其中,和
表示检测损失,它们是在学生的预测值
、
与对应的真实目标值
、
之间计算得出的。额外的CrossKD损失表示为
和
,它们是在交叉头的预测值
、
与教师的预测值
、
之间进行计算的。
在具体实现方面,作者对不同任务分支采用了不同的距离函数。
- 分类分支,将教师模型预测分类得分视作软标签,直接采用Quality Focal Loss(QFL)约束学生模型与老师模型预测结果之间距离;
- 回归分支,对于直接从Anchor(RetinaNet、ATSS)或点(FCOS)回归边界框的回归头,直接采用GIoU作为
;对于预测一个向量来表示框位置的分布(GFL)的回归头,它包含比边界框表示的Dirac分布更丰富的信息,为有效蒸馏位置信息,采用KL散度进行知识迁移。
实验
消融实验
Positions to apply CrossKD

- 在所有蒸馏位置,CrossKD均可提升模型性能;
- 在第3个位置处取得了最佳性能38.7mAP,比已有预测模拟方案LD高出0.9mAP。
CrossKD v.s. Feature Imitation

- PKD作用在FPN特征时可以取得38.0mAP,当作用在检测头时模型性能明显下降;
- CrossKD取得了38.7mAP,比PKD方案高出0.7mAP。

PKD生成的梯度对于完整特征图有大而宽的影响,而CrossKD生成的梯度仅聚焦在有潜在语义信息的区域。
CrossKD v.s. Prediction Mimicking

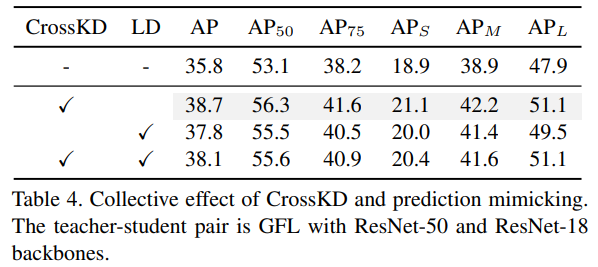
- 将LD替换为CrossKD后可以取得稳定的性能提升;
- CrossKD+LD组合反而出现了性能下降,从CrossKD的38.7下降到了38.1.

CrossKD v.s. HEAD

CrossKD for Lightweight Detectors
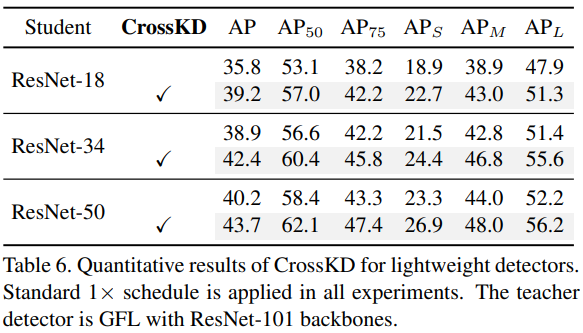
对比实验
Comparison with SOTA KD Methods

CrossKD on Different Detectors

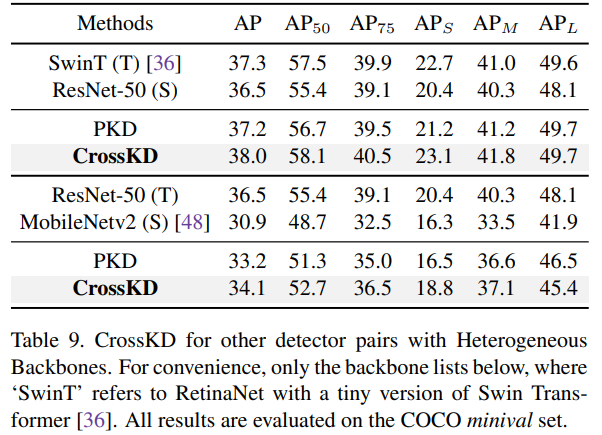

附录
CrossKD的不同变体

不同变体的性能

分类分支蒸馏损失的影响
