paper:On the Efficacy of Knowledge Distillation
本文的题目是《论知识蒸馏的有效性》,主要是对教师模型并不是越大越好这一现象进行研究,并提出了缓解方法:early stop。
Bigger models are not better teachers
知识蒸馏背后的思想是,训练好的教师模型学习到的soft probabilities比标签更能反映数据的真实信息。因此人们可能认为,如果教师模型的预测更加准确,这些soft probabilites就能更好的捕获潜在的类别分布信息并且作为一个更好的教师模型为学生模型提供监督信息。因此直觉上会期望更大更准确的模型应该是更好的教师模型。作者在CIFAR 10和ImageNet数据集上分别进行了实验,其中保持学生模型不变,用不同大小的教师模型进行蒸馏。CIFAR10的结果如下

其中左边是不同深度的教师模型蒸馏下学生模型的error变化,右边是不同宽度的教师模型蒸馏下学生模型的error变化,可以看出随着教师模型变得更大,学生模型的精度一开始可能会有所提升,但随后就开始下降。
下表是在ImageNet上的实验结果

同样的结果,随着教师模型精度越来越高,学生模型的精度反而越来越低。
通过这两个实验得到结论:更大更准确的模型未必是更好的教师模型。
这种下降的原因可能是什么?一种可能性是,随着教师模型变得更加confident和准确,输出概率开始越来越像one-hot的真实标签,因此学生可用的信息就会减少。但是,用更大的 \(T\) 对probabilities进行soften并没有改变这一结果从而否定了这一假设。下面,作者提出了另一种假设。
Analyzing student and teacher capacity
对于更大更准确的教师模型不让提高学生模型的精度,作者给出两个可能的原因:
- 学生能够模仿老师,但这并不能提高其精度。这表明KD损失和我们所关心的精度metric之间的不匹配。
- 学生无法模仿老师,这表明学生和教师的能力capacities的不匹配。
作者在CIFAR 10和ImageNet上评估了这两种假设,下表是CIFAR 10上的KD error,即学生和老师的预测不同的例子的比例。
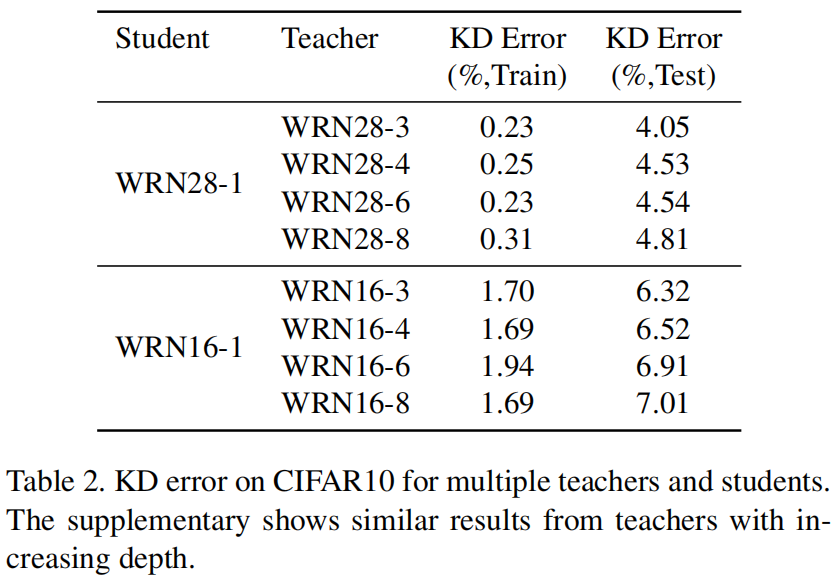
表3的奇数行是学生模型ResNet-18在不同的教师模型蒸馏下在ImageNet数据集上的KD损失
在这两种情况下,更大的教师模型的KD error/loss都要高得多,这反过来又导致了学生模型精度的下降。这表明,学生模型无法模仿很大的教师模型,这指向了第二个假设,即这个问题是一个能力不匹配的问题。因此,我们假设,在ImageNet和CIFAR上,由于容量要低得多,学生无法在其空间中找到与最大的教师相对应的解决方案。
Distillation adversely affects training
注意到知识蒸馏在ImageNet数据集上的效果尤其差,如表1所示,用不同的教师模型进行蒸馏还不如从头训练学生模型的精度高,并且之前知识蒸馏的论文大都在CIFAR数据集上进行实验,很少给出在ImageNet数据集上的实验结果。
作者对这一现象进行了深入研究,图3是从头训练的ResNet-18和用ResNet-34进行蒸馏在验证集上的Error对比。可以看出,虽然一开始KD提高了验证集上的精度,但在训练结束时精度反而降低了。
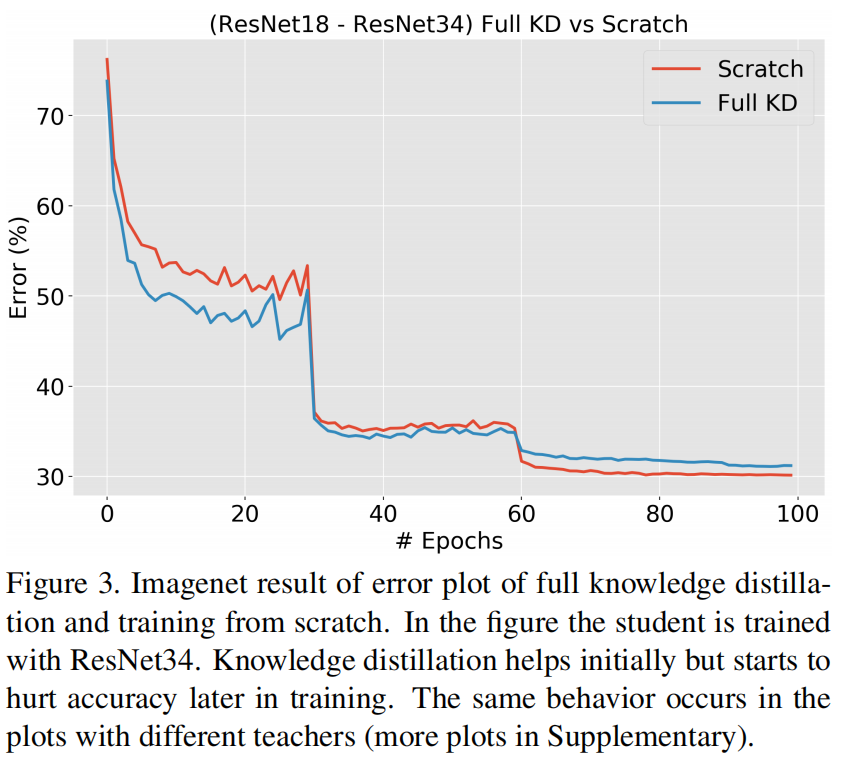
作者假设,因为ImageNet是一个更具挑战性的数据集,较小的学生模型可能处于不拟合的状态。因此可能没有足够的能力来同时优化训练损失和蒸馏损失,并可能最终以牺牲另一个损失(KD损失)为代价来优化一个损失(交叉熵损失),尤其是到训练结束的时候。
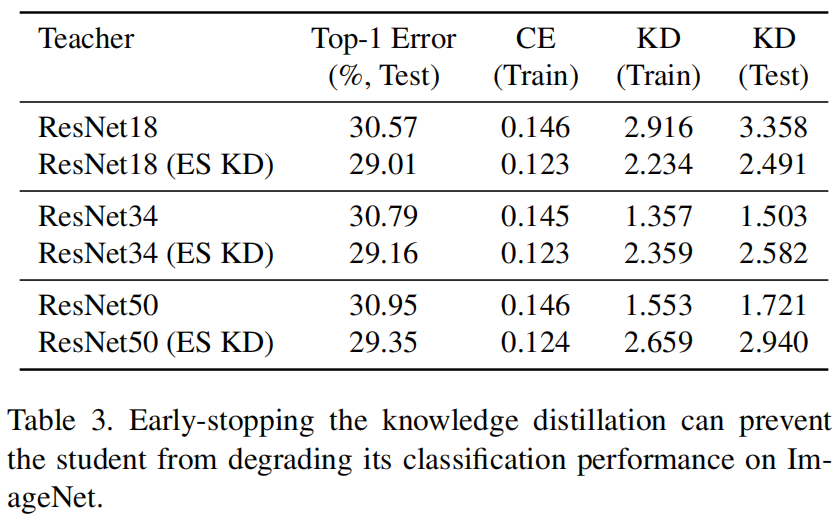
这一假设表明,我们可以在训练过程的早期停止知识蒸馏,并在剩下的训练过程中只对交叉熵损失进行优化。我们将这个过程称为“早期停止(Early-stopped)”的知识蒸馏(“ESKD”)。
表3对比了ESKD和标准KD的精度,可以看出ESKD下不同的教师模型就得到了更高的精度,但是,early stop并没有改变我们最初的观察:更大、更准确的教师模型不会得到更准确的学生模型。即使进行了早停,我们发现测试集上的KD损失随着教师模型的增大而增加,这表明学生仍在努力模仿老师,这确实是学生能力的问题。
The efficacy of repeated knowledge distillation
如果学生模型和教师模型的规格差距过大,一种自然的想法是首先从大教师模型提炼到中间教师模型,然后提炼到学生模型,使得每个知识蒸馏步骤都让学生模型和教师模型能力有更好的匹配。sequence knowledge distillation的概念在之前的文章中已经被提出过,最近有一篇文章提出训练一系列模型,其中第 \(i\) 个模型以第 \(i-1\) 个模型为教师模型进行蒸馏训练,他们发现,与从头开始训练的模型相比,这种顺序知识蒸馏可以提高性能,并且对这一系列模型进行继承可以得到更好的模型。
作者在CIFAR10上对该结论进行了验证,结果如表4所示
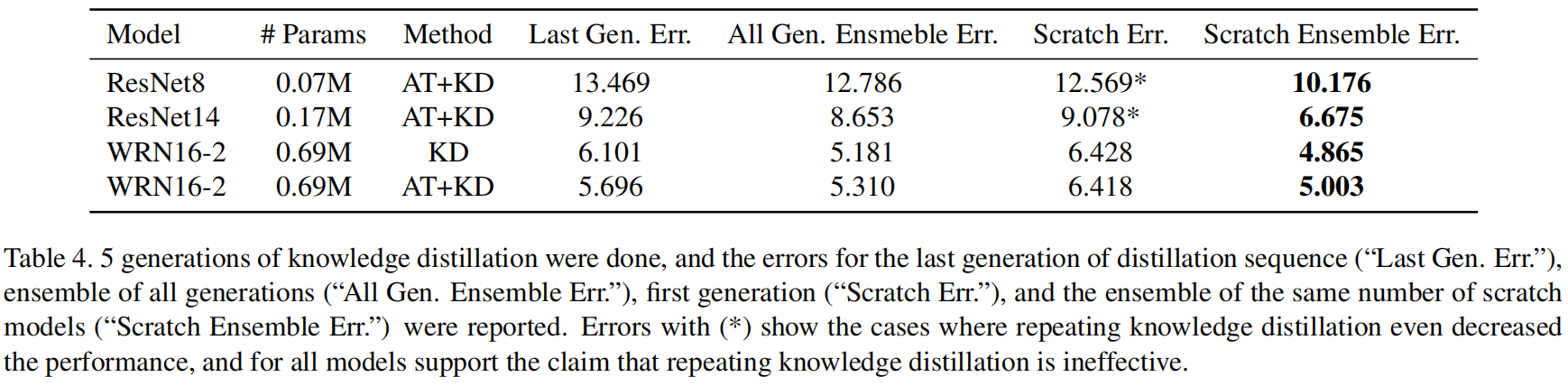
作者对上述观点进行了驳斥,首先对于一些模型比如ResNet-8和ResNet-14,sequence中最后一个学生模型的精度是要比从头训练的精度低的,网络架构在很大程度上决定了sequence KD的成功。其次,作者发现,尽管对整个序列的学生模型进行集成优于从头开始训练的单个模型,但它并不优于从头开始训练的相同数量的学生模型的集成。这可能是因为通过一系列知识蒸馏步骤获得的学生模型可能相互关联,因此可能不会产生一个强大的集成模型。
如果sequential knowledge distillation确实提高了模型的精度,那么一个自然的问题是由此得到的模型是否是一个更好的教师模型?为了评估这个问题,作者做了如下实验,选择WRN16-1作为学生模型,WRN16-3作为教师模型(如图2所示这是最佳的教师模型),然后用5次迭代的sequence蒸馏来训练教师模型,并与从头训练的教师模型进行比较,结果如表5所示,可以看出经过多次迭代蒸馏得到的教师模型尽管本身精度更高,但并不是一个更好的教师模型。
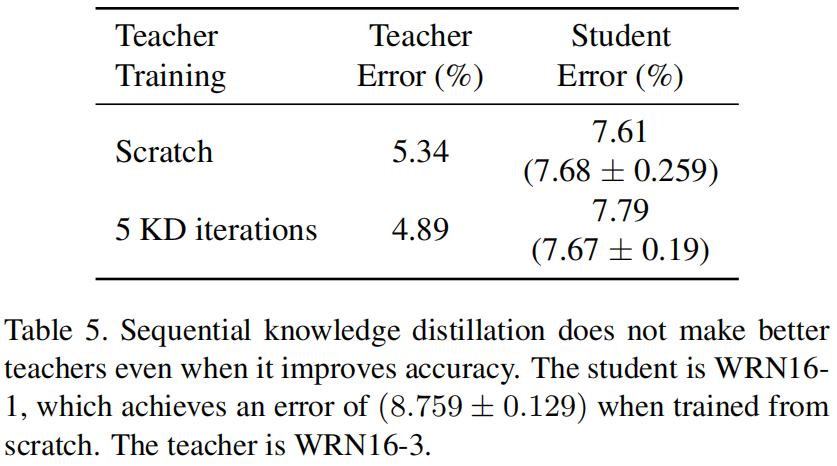
Early-stopped teachers make better teachers
在上一节中作者已经证明了sequence知识蒸馏是无效的,这可能是因为它并没有解决核心问题:大模型找到的解决方案在小模型的能力之外或者说在小模型的solution space之外。唯一的解决方法是找到一个教师模型,它找到的解决方案是小模型能够找到的。
我们可以通过grid search来找到最合适的教师模型,但这代价太大了。作者建议在训练大模型时对其进行正则化regularize,比如对大模型的训练进行early stop。有一些研究表明,一个只训练了少数epoch的大模型的表现和小模型一样,但仍然包含比小模型更大的搜索空间。作者在CIFAR 10和ImageNet上评估了该想法,结果如图4所示
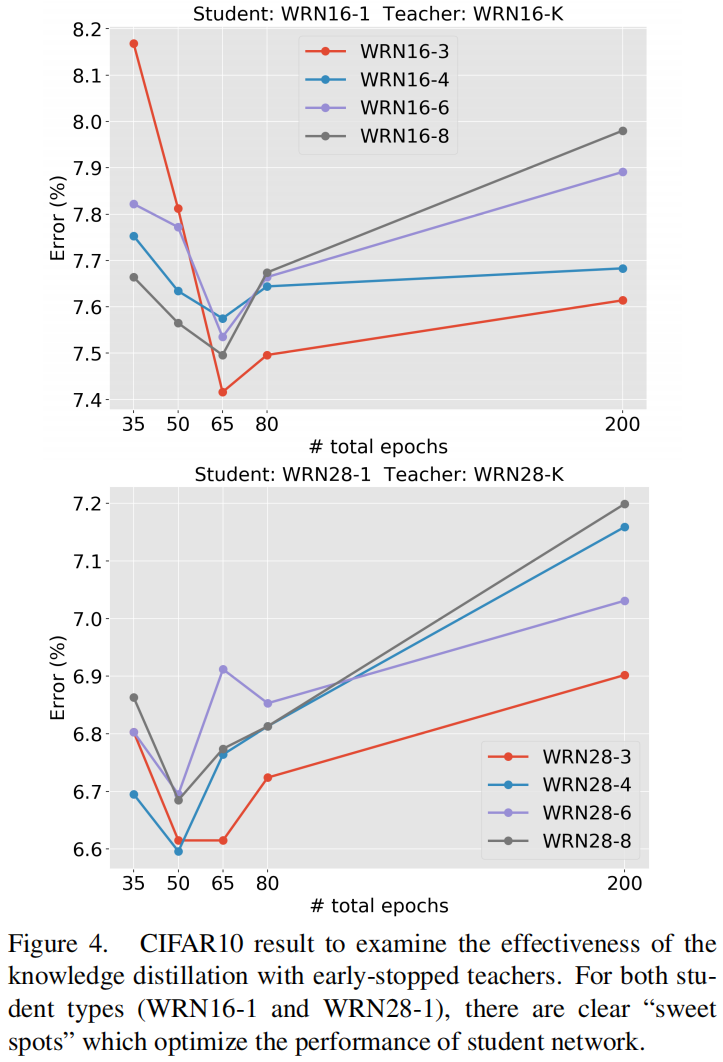
其中x轴是教师模型的训练epoch,纵轴是学生模型的error,可以看出所有提前终止训练的教师模型蒸馏出的学生模型的精度都比完成全部训练的教师模型蒸馏出的学生模型的精度高。
Conclusion
- 并不是更好(精度更高)的教师模型就能教出(蒸馏)更好的学生模型
- 这可能是能力不匹配的问题,教师模型找到的solution在学生模型的solution space之外
- 之前解决该问题的方法是逐步进行蒸馏,本文证明其效果也不好,并且效果和网格结构有关系
- 本文提出提前终止蒸馏可以有效缓解该问题
- 提前终止教师模型的训练也可以有效缓解该问题