还是Tsung-Yi Lin Piotr Dollar kaiming ross他们在Detection领域做的贡献Focal Loss for Dense Object Detection
Motivation
single stage的检测方法如YOLO、SSD等简单高效,但是精度往往不如two stage的如Faster/Mask RCNN,本文发现single stage不如two stage的核心问题在于极度不平衡的正负样本比例,因为anchors/default boxes近似于sliding window的方式会使正负样本接近1000:1,而绝大部分负样本都是easy example,这就导致gradient被easy example主导: 这些easy example虽然loss很低,但由于数量众多,对于loss依旧有很大贡献,从而导致收敛到不够好的一个结果。
PS: Nanyan Wang在知乎上回答 “在我的知识体系内比较颠覆的一个paper,之前一直认为Single stage detector结果不够好的原因是使用的feature不够准确(使用一个位置上的feature),所以需要Roi Pooling这样的feature aggregation办法得到更准确的表示。但是这篇文章基本否认了这个观点”
Framework

主要变化:
- cls和box分开了,然后多加了conv
- 更多的anchors(由于focal loss的加入,能hold住这么多anchors)
Focal loss

γ=0时,FL==CE,是标准的交叉熵损失。
γ为了降低easy example的权重,专注于训练难分负样本而引入,γ越大easy example的权重越小。
我们从图中可以看到,概率>0.6的部分为easy example,虽然能够很好将它们分对loss也很低,但是由于刚刚讲的那样single stage中的产生的anchors/default boxes绝大部分是负样本很容易分对,这些微小的loss积少成多,导致训练很低效,甚至影响了正常的训练,使模型退化,不能区分稍微少一点的样本。
解决样本不均衡的问题,还可以采用Balanced Cross Entropy,对于样本过多的类别,设置较低的权重,比如给负样本设置<0.5的权重,这样也会使减轻被easy example主导的情况,但是实验效果不如Focal loss

(a)中α是给正样本的权重,1-α是给负样本的权重,可以看到α=0.75时取得最好结果

本文在Focal loss的基础上加上权重α,最终的公式如下:
- α:为了解决 Class Imbalance 问题而引入,对于样本数过多的那一类样本,α应设得较低,这样就降低了该类样本对于Loss的重要性
- γ:为了降低易分样本的权重,专注于训练难分负样本而引入,(1 - Pt)∈(0,1),当样本易分类时,(1 - Pt)很小,(1 - Pt)^γ会变得更小,这样就减少了简单易分类样本的重要性,相对增加了那些误分类样本的重要性
单单就α-balanced Focal Loss用在single stage检测中,α和γ的作用是有重合部分的,因为大量负样本就是easy example,它的权重需要下降,即α和γ都要对它改变。
但从(b)中可以看到,γ比α的调整作用更大,baseline是α=0.5,调到最优α=0.75,AP提升了0.9个点,但是α=0.5,γ=0.5时AP提升了2.7个点,α和γ结合后最高提升了3.8个点

附加说明
我们在框架中给BCE或者CE加权重α时,通常需要给每个类别指定,本文这里只给出一个α,对于BCE来说label=0权重为1-α,label=1权重为α;对于CE来说label=0权重为1-α,label>=1的权重都为α
BCE公式
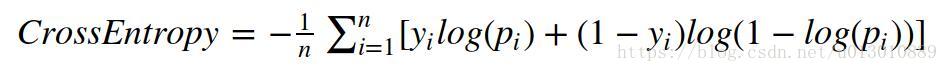
CE公式
ti,j是one-hot向量,只有label处为1,pi,j为预测出来的各个类别的概率。这个公式装成标量就是只在label位置处取概率的log

BCE和CE的公式是统一的,只在label位置处取概率的log。但由于用BCE时只输出是一个标量值,即为正样本的概率p,所以和CE公式不太一样但本质还是一样,我们把BCE的输出变成向量(p,1-p),和CE公式就一致了。-ti,j*log(pi,j): 如果label为1:ti,j=(1,0),pi,j=(p,1-p), loss为-log(p),如果label为0: ti,j=(0,1),pi,j=(p,1-p), loss为-log(1-p)