Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
论文链接: https://arxiv.org/abs/2103.17115
代码仓库: https://github.com/hzhupku/DCNet (基于Python 3.6.5 、 PyTorch 1.1.0.实现)
这是一篇北京大学和北京邮电大学共同发表在2021 CVPR上的一篇关于few-shot目标检测的论文。
提出背景
目前,基于卷积神经网络的深度学习模型用于目标检测取得了SOTA效果,但是这些检测模型需要大量的矩形框标注数据来训练。众所周知,获取这些矩形框的高质量标注十分耗费人力。因此,研究使用少量标注数据进行训练的目标检测框架(Few-Shot目标检测)具有重要意义。Few-Shot目标检测,要学习使用少量的标注样本适应新的类别。Few-Shot目标检测任务只可以使用少量样本,所以很难提取到细粒度特征。
这篇论文的工作建立在元学习框架的基础上。除此之外,论文创新性地提出了Dense Relation Distillation(DRD)模块 和 Context-aware Feature Aggregation(CFA) 模块。DRD模块旨在全面探索支持集的特征,使得支持集和查询集的特征稠密匹配,这种稠密匹配能力不仅能学习到整体特征,还能学习到局部特征,很好地克服了查询集物体外观改变和遮挡的问题,如图1所示。CFA模块通过集成多尺度特征信息,对数据集中尺度不同的物体均可以较好地完成检测。

图1. 物体外观和物体遮挡问题
方法解读
这篇论文的根本目的旨在通过利用从具有大多数样本的基类(base classes)和具有少数样本的新类别(novel classes)中学习到的泛化能力,同时很好地检测到测试集中的base classes 和 novel classes。
Few-Shot目标检测框架
1、任务抽象定义:论文中按照元学习的方法将目标检测任务定义为k-shot任务,即每个novel classes的样本数设定为k。
2、基础目标检测框架:论文中是采用了目标检测框架作为基础进行的创新。作者经过实验发现Faster-RCNN要比YOLO系列的效果好一些,所以整体框架沿用了Faster-RCNN的(Backbone、RPN、ROI Pooling、Detection head)。
3、特征分配权重:输入一张查询图片,{
I s i , M s i {I_{si}, M_{si}} Isi,Msi}, I s i I_{si} Isi表示支持集中的图片, M s i M_{si} Msi表示由矩形框标注转换过来的掩码,N是训练集的类别数量。 Z j ∣ j = 1 n Z^j|_{j=1}^n Zj∣j=1n是由ROI pooling得到的ROI特征, ω i \omega_i ωi是由为特征分配权重的模块得到的权重值。特征分配方法如下:
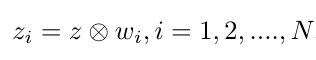
Z i Z_i Zi是经过权重分配后的ROI特征向量。公式内的符号表示的是通道相乘的计算方式。
整体框架
整个检测框架如图2所示。
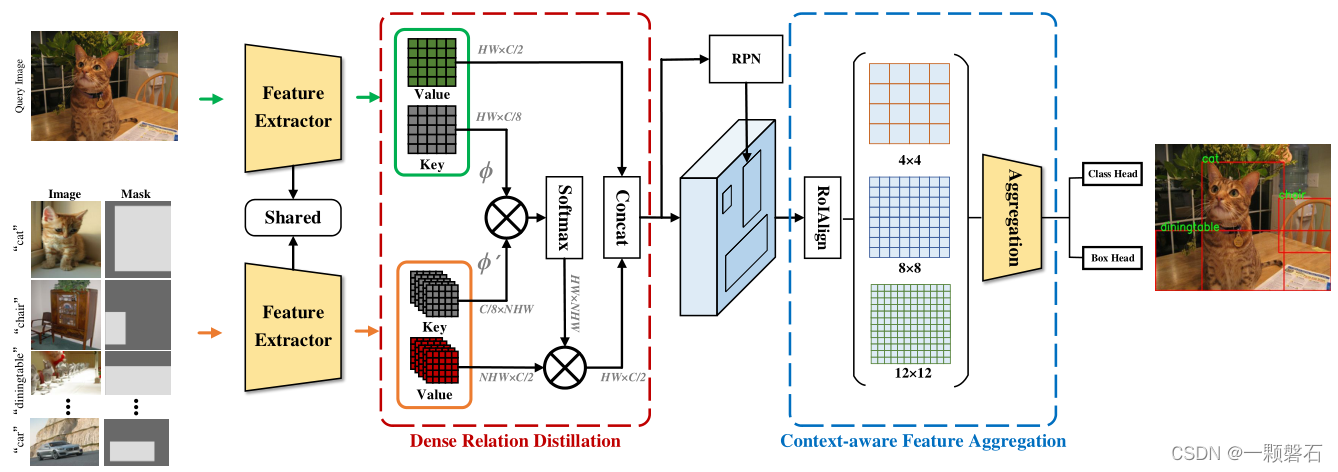
图2. 论文提出的DCNet整体框架
框架图中显示,查询图像和支持集的图像同时输入参数共享的特征提取网络,输出的特征图送入DRD模块,经过3*3的卷积运算(论文中提到的)分别得到key和value。查询集的key与支持集内的key进行相似度计算后通过softmax输出,查看查询图像与支持集图像的哪些像素区域的相关性较大,即检索的过程。之后将相似性度量与支持集图像的value集合相乘,相当于按照与查询图像的相似度给支持集图像分配权重,再与查询集图像的value进行concat得到与输入相同分辨率的特征图。特征图送入RPN网络提取ROI,提取的ROI进行ROI Align操作后得到三种不同分辨率的特征图,送入CFA模块进行整合,整合后的特征图送入Detection head进行分类和回归,得到检测结果。
key和value的embedding
查询图像和支持集图像通过参数共享的特征提取网络得到查询特征和支持特征集。查询特征和支持特征集丢进各自的深度编码器(结构相同 [两个并行的3*3卷积层],但参数不共享)内得到key和value的映射。这一步将特征图在通道维度上进行了降维以减少计算量。
Relation Distilled 关系蒸馏
得到key和value的集合后,就可以沿着Transformer的思路,计算查询图像和支持集图像在空间位置上的相似性了,Relation Distilled的做法如下:
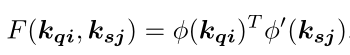
其中, K q i K_{qi} Kqi和 K s j K_{sj} Ksj是查询图像和支持集图像的在空间位置 i 和 j 上的key值,经过线性变换 ψ \psi ψ之后相乘得到相似性度量。
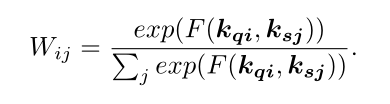
之后通过softmax得到支持集内每张图片的各个位置的key关于查询图像该位置的相关性权重 W i j W_{ij} Wij。
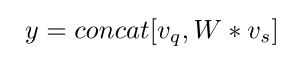
权重向量W和支持集图像的value相乘后与查询图像的value拼接得到与输入特征图维度相同的特征图,用于送入RPN生成ROI。
Context-aware Feature Aggregation (CFA)
CFA的目的是为了融合多尺度的语义信息生成更高级更丰富的特征,有助于增强模型对于各种尺度目标的检测能力。RPN输出的ROI输入经过ROI得到三种不同分辨率的特征图,这三种特征图经过CFA整合送入Detection head做分类和回归。
CFA的工作原理如下:
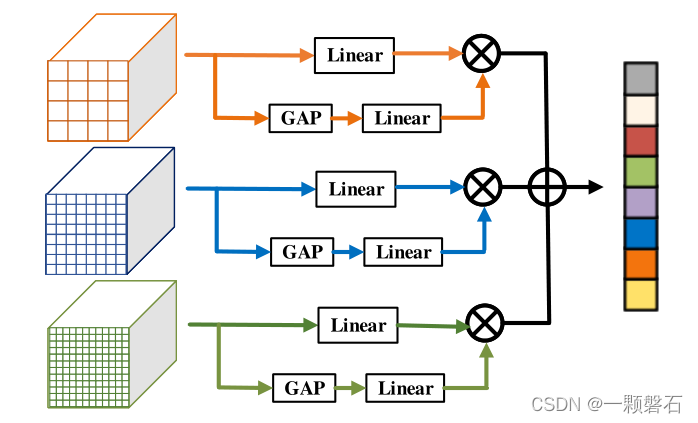
作者在这一部分加入了attention机制,三在种不同分辨率的特征图都分别经过两个分支,下面的分支首先对特征图进行GAP,然后送入Linear模块(全连接层)得到各个通道的权重,上边的分支送入Linear模块(我猜着此处的Linear模块是为了调整特征图的分辨率,方便后边相加),权重与经过线性变化的特征图进行通道相乘。最后三种不同分辨率的特征图进行相加得到最终的特征。该特征中融合了不同尺度的语义信息,大分辨率的特征负责检测小目标,小分辨率的特征负责检测大目标(根据感受野的概念进行理解)。
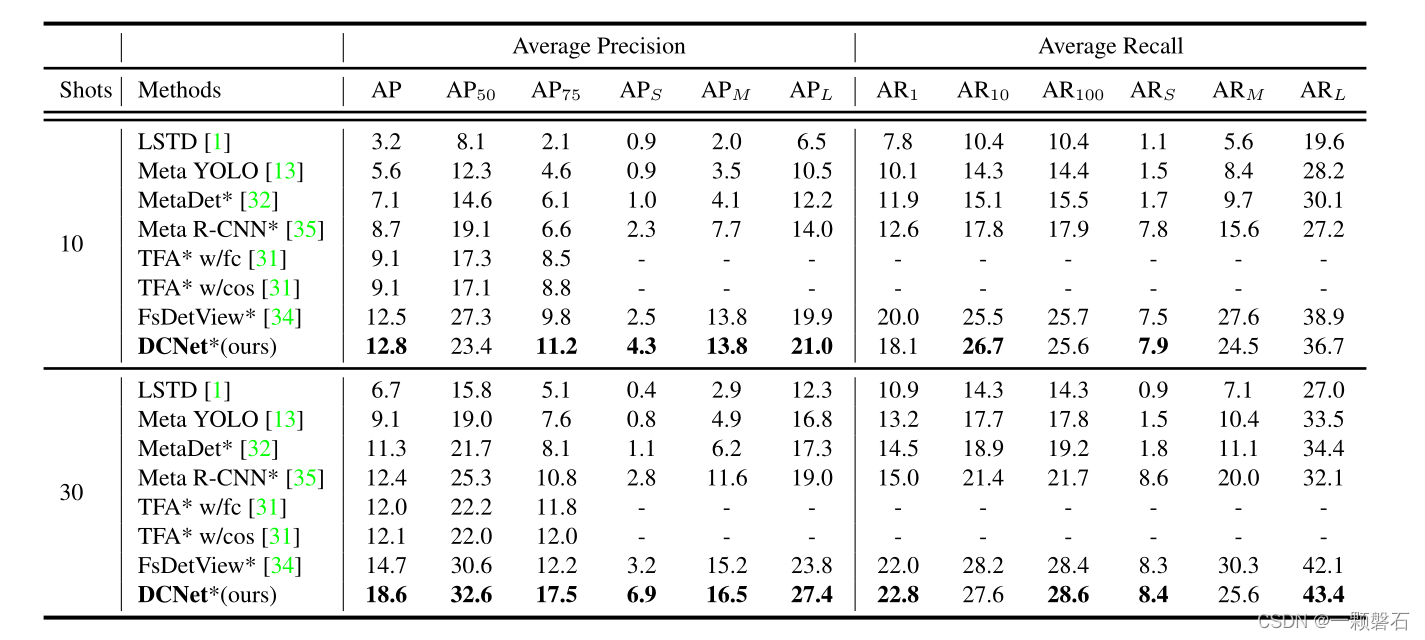
实验效果

总结
这篇论文针对小样本的目标检测问题提出一种基于K-Shot元学习方法的目标检测框架。论文中提出了针对查询集物体出现外观变化和遮挡的问题提出了Dense Relation Distilled模块,用于生成查询集和支持集之间的稠密匹配,帮助模型在有整体视野的前提下观察局部细节特征。同时,为了提升模型对不同尺度目标的敏感度,引入了Context-aware Feature Aggregation模块,在ROI Align阶段提取三种不同分辨率的ROI特征图,引入Attention机制对每个特征图生成通道权重进行线性变化,最后将三个变换后的特征图相加得到最终送入Detection head的特征图,在此基础上进行精细化的回归和分类,得到检测结果。