论文地址:https://arxiv.org/pdf/1708.02002.pdf
最近YOLO_V3版本刚刚出世,很强,下面一篇博客我们再介绍,这篇博客我们主要来读读大神何凯明的大作Focal Loss(焦点损失),其主要就是一个解决分类问题中类别不平衡、分类难度差异的一个 loss。Focal loss 这个损失函数在标准的交叉熵标准上添加了一个因子
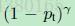
目前目标检测的框架一般分为两种:基于候选区域的two-stage的检测框架(比如fast r-cnn系列),基于回归的one-stage的检测框架(yolo,ssd这种),two-stage的效果好,one-stage的快但是效果差一些。对于two-stage的检测器而言,通常分为两个步骤,第一个步骤即产生合适的候选区域,而这些候选区域经过筛选,一般控制一个比例(比如正负样本1:3),另外还通过hard negatiive mining(OHEM),控制难分样本占据的比例,以解决样本类别不均衡的问题。
对于one-stage的检测器来说,尽管可以采用同样的策略(OHEM)控制正负样本,但是还是有缺陷。
参考地址:https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/78920998
https://blog.csdn.net/qq_34564947/article/details/77200104
https://blog.csdn.net/u014380165/article/details/77019084
作者以二分类为例进行说明:
首先是我们常使用的交叉熵损失函数:
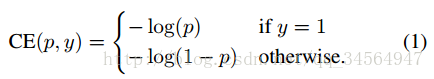
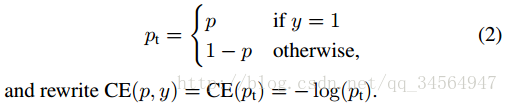
要对类别不均衡问题对loss的贡献进行一个控制,即加上一个控制权重即可,最初作者的想法即如下这样,对于属于少数类别的样本,增大α即可
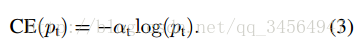
因此后面有了如下的形式:
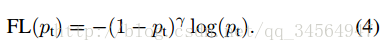
显然,样本越易分,pt越大,则贡献的loss就越小,相对来说,难分样本所占的比重就会变大。
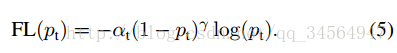
这里的两个参数α和γ协调来控制,本文作者采用α=0.25,γ=2效果最好
另外:作者提到了类别不均衡和模型的初始化问题,即数量很多的某一类样本会起主导作用,在开始训练的时候可能导致不稳定。
实验框架
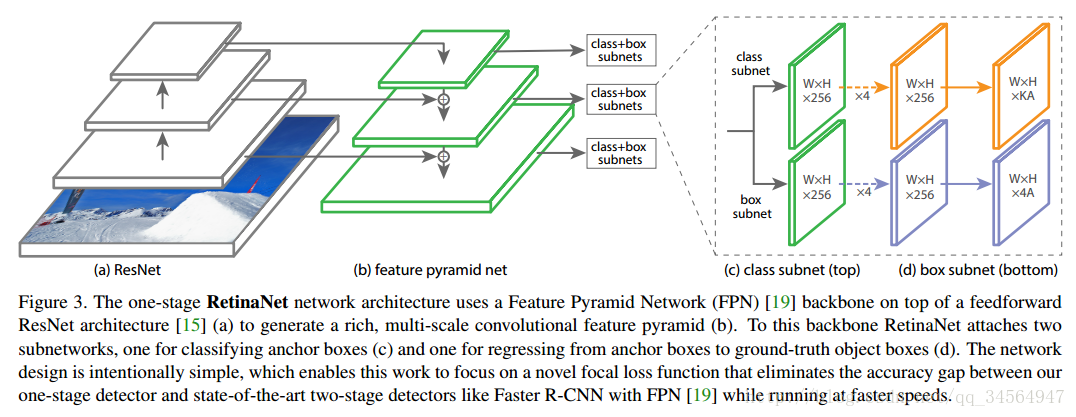
实验时设计了一个叫RetinaNet的one-satge的网络结构,以证明通过Focal Loss,one-stage的网络结构也能够达到two-stage的准确率,实际上采用的是基于resnet的FPN(特征金字塔网络,可自行查阅论文论文链接),网络框架如下: