图像 检测 - RetinaNet: Focal Loss for Dense Object Detection - 密集目标检测中的焦点损失(arXiv 2018)
声明:此翻译仅为个人学习记录
文章信息
- 标题:RetinaNet: Focal Loss for Dense Object Detection (arXiv 2018)
- 作者:Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár
- 文章链接:https://arxiv.org/pdf/1708.02002.pdf
- 文章代码:https://github.com/facebookresearch/Detectron
(推荐:亦可参考 图像 处理 - 开源算法集合)
摘要
迄今为止,最高精度的目标检测器是基于R-CNN推广的两阶段方法,其中将分类器应用于候选目标位置的稀疏集。相比之下,对可能的目标位置进行定期、密集采样的单级检测器有可能更快、更简单,但迄今为止的精度落后于两级检测器。在本文中,我们调查了为什么会出现这种情况。我们发现,在密集检测器的训练过程中遇到的极端前景-背景类不平衡是主要原因。我们建议通过重塑标准交叉熵损失来解决这种类别不平衡问题,使其对分配给分类良好的示例的损失进行加权。我们的新颖的Focal Loss将训练集中在一组稀疏的困难例子上,并防止在训练过程中大量容易出现的阴性影响淹没检测器。为了评估我们损失的有效性,我们设计并训练了一个简单的密集检测器,我们称之为RetinaNet。我们的结果表明,当使用焦点损失进行训练时,RetinaNet能够与以前的单级检测器的速度相匹配,同时超过所有现有最先进的两级检测器的精度。代码位于:https://github.com/facebookresearch/Detectron.

图1. 我们提出了一种新的损失,我们称之为焦点损失,它在标准交叉熵标准中添加了一个因子 ( 1 − p t ) γ (1−p_t)^γ (1−pt)γ。设置 γ > 0 γ>0 γ>0可以减少分类良好的示例的相对损失 ( p t > . 5 ) (p_t>.5) (pt>.5),从而更加关注难以分类的错误示例。正如我们的实验所证明的那样,所提出的焦点损失能够在大量简单背景示例的情况下训练高精度的密集目标检测器。

图2. COCO test-dev的速度(ms)与精度(AP)。由于焦点损失,我们的简单单级RetinaNet检测器优于以前的所有单级和两级检测器,包括[20]中报道最好的Faster R-CNN[28]系统。我们展示了在五个尺度(400-800像素)上具有ResNet-50-FPN(蓝色圆圈)和ResNet-101-FPN(橙色菱形)的RetinaNet变体。忽略低精度状态(AP<25),RetinaNet形成了所有当前检测器的上包络,改进的变体(未显示)达到40.8 AP。详细信息见§5。
1. 引言
目前最先进的目标检测器是基于两阶段、提案驱动机制。正如在R-CNN框架[11]中推广的那样,第一阶段生成候选目标位置的稀疏集,第二阶段使用卷积神经网络将每个候选位置分类为前景类之一或背景。通过一系列的进步[10,28,20,14],这个两阶段的框架在具有挑战性的COCO基准[21]上始终实现了最高的准确性。
尽管两级检测器取得了成功,但一个自然的问题是:一个简单的单级检测器能达到类似的精度吗?单级检测器应用于目标位置、尺度和纵横比的规则、密集采样。最近对单级检测器的研究,如YOLO[26,27]和SSD[22,9],证明了有希望的结果,与最先进的两级方法相比,产生了精度在10-40%以内的更快检测器。
本文进一步推进了这一概念:我们提出了一种单级目标检测器,它首次与更复杂的两级检测器的最先进的COCO AP相匹配,如特征金字塔网络(FPN)[20]或Faster R-CNN[28]的Mask R-CNN[14]变体。为了实现这一结果,我们将训练过程中的类不平衡确定为阻碍单级检测器实现最先进精度的主要障碍,并提出了一种新的损失函数来消除这一障碍。
通过两阶段级联和采样启发式算法,解决了类CNN检测器中的类不平衡问题。提议阶段(例如,选择性搜索[35]、边缘框[39]、深度掩码[24,25]、RPN[28])迅速将候选目标位置的数量缩小到一个小数字(例如,1-2k),过滤掉大多数背景样本。在第二个分类阶段,执行采样启发法,如固定的前景与背景比率(1:3)或在线困难示例挖掘(OHEM)[31],以保持前景和背景之间的可管理平衡。
相比之下,单级检测器必须处理在图像上定期采样的一组更大的候选目标位置。在实践中,这通常相当于列举了大约100k个密集覆盖空间位置、尺度和纵横比的位置。虽然也可以应用类似的采样启发法,但它们效率低下,因为训练过程仍然由容易分类的背景示例主导。这种低效率是目标检测中的一个经典问题,通常通过自举[33,29]或困难示例挖掘[37,8,31]等技术来解决。
在本文中,我们提出了一个新的损失函数,作为处理类别不平衡的先前方法的更有效的替代方案。损失函数是一个动态缩放的交叉熵损失,其中缩放因子随着对正确类的置信度增加而衰减为零,见图1。直观地说,这个缩放因子可以在训练过程中自动降低简单示例的贡献,并快速将模型集中在困难示例上。实验表明,我们提出的Focal Loss使我们能够训练高精度的单级检测器,该检测器显著优于使用采样启发法或困难示例挖掘进行训练的替代方案,这是以前训练单级检测器的最先进技术。最后,我们注意到焦点损失的确切形式并不重要,我们表明其他实例可以获得类似的结果。
为了证明所提出的焦点损失的有效性,我们设计了一个名为RetinaNet的简单单级目标检测器,该检测器因其对输入图像中目标位置的密集采样而得名。它的设计特点是一个高效的网络内特征金字塔和使用锚框。它借鉴了[22,6,28,20]中的各种最新思想。RetinaNet高效准确;我们的最佳模型基于ResNet-101-FPN主干,在以每秒5帧的速度运行时,实现了39.1的COCO test-dev AP,超过了之前公布的单级和两级检测器的最佳模型结果,见图2。
2. 相关工作
经典目标检测器:将分类器应用于密集图像网格的滑动窗口范式有着悠久而丰富的历史。最早的成功之一是LeCun等人的经典工作。他将卷积神经网络应用于手写数字识别[19,36]。Viola和Jones[37]使用增强的目标检测器进行人脸检测,导致了此类模型的广泛采用。HOG[4]和整体通道特征[5]的引入产生了行人检测的有效方法。DPM[8]有助于将密集检测器扩展到更通用的目标类别,并在PASCAL[7]上取得了多年的最佳结果。虽然滑动窗口方法是经典计算机视觉中的主要检测范式,但随着深度学习[18]的复兴,接下来描述的两阶段检测器很快就主导了目标检测。
两阶段检测器:现代目标检测的主导范式是基于两阶段方法。正如选择性搜索工作[35]所开创的那样,第一阶段生成一组稀疏的候选提案,该候选提案应包含所有目标,同时过滤掉大多数阴性位置,第二阶段将提案分类为前景类/背景。R-CNN[11]将第二阶段分类器升级为卷积网络,从而在精度上获得了很大的提高,并开创了目标检测的现代时代。多年来,R-CNN在速度[15,10]和使用学习目标提案[6,24,28]方面都有所改进。区域提案网络(RPN)将提案生成与第二阶段分类器集成到单个卷积网络中,形成更快的R-CNN框架[28]。已经提出了对该框架的许多扩展,例如[20,31,32,16,14]。
单级检测器:OverFeat[30]是第一个基于深度网络的现代单级目标检测器之一。最近,SSD[22,9]和YOLO[26,27]对一阶段方法重新产生了兴趣。这些检测器经过了速度调整,但其精度落后于两阶段方法。SSD的AP降低了10-20%,而YOLO则专注于更极端的速度/精度权衡。见图2。最近的工作表明,只需降低输入图像分辨率和提案数量,就可以快速实现两阶段检测器,但即使计算预算更大,单阶段方法的精度也落后[17]。相比之下,这项工作的目的是了解单级检测器在以类似或更快的速度运行时是否能够匹配或超过两级检测器的精度。
我们的RetinaNet检测器的设计与以前的密集检测器有很多相似之处,特别是RPN[28]引入的“锚”概念,以及SSD[22]和FPN[20]中特征金字塔的使用。我们强调,我们的简单检测器取得了最佳结果,这不是基于网络设计的创新,而是由于我们的新损失。
类别不平衡:经典的单阶段目标检测方法,如增强检测器[37,5]和DPM[8],以及最近的方法,如SSD[22],在训练过程中都面临着较大的类别不平衡。这些检测器评估每个图像104-105个候选位置,但是只有少数位置包含目标。这种不平衡导致了两个问题:(1)训练效率低下,因为大多数位置都是容易产生阴性影响的,没有提供有用的学习信号;(2) 总的来说,简单的阴性影响可能会淹没训练,并导致退化模型。一种常见的解决方案是执行某种形式的困难阴性挖掘[33,37,8,31,22],在训练或更复杂的采样/重新加权方案[2]期间对困难示例进行采样。相反,我们表明,我们提出的焦点损失自然地处理了单级检测器所面临的类别不平衡,并使我们能够在没有采样的情况下对所有示例进行有效训练,也没有容易的阴性压倒损失和计算的梯度。
鲁棒估计:人们对设计鲁棒损失函数(例如,Huber损失[13])非常感兴趣,该函数通过对具有大误差的示例(困难示例)的损失进行加权来减少异常值的贡献。相反,我们的焦点损失不是解决异常值,而是通过对异常值(简单的例子)进行加权来解决类别不平衡问题,即使它们的数量很大,它们对总损失的贡献也很小。换句话说,焦点损失扮演着与鲁棒损失相反的角色:它将训练集中在一组稀疏的困难例子上。
3. 焦点损失
Focal Loss旨在解决单级目标检测场景,在该场景中,在训练期间前景和背景类别之间存在极端不平衡(例如,1:1000)。我们从二进制分类的交叉熵(CE)损失开始引入焦点损失(将焦点损失扩展到多类情况是直接的,并且效果良好;为了简单起见,我们在这项工作中重点关注二进制损失。):

在上面的示例中,y∈{±1}指定了真值类,p∈[0,1]是模型对标签为y=1的类的估计概率。为了便于注释,我们定义 p t p_t pt:

并重写 C E ( p , y ) = C E ( p t ) = − l o g ( p t ) CE(p,y)=CE(p_t)=-log(p_t) CE(p,y)=CE(pt)=−log(pt)。
CE损失如图1中的蓝色(顶部)曲线所示。这种损失的一个值得注意的特性是,即使是易于分类的示例 ( p t > > . 5 ) (p_t>>.5) (pt>>.5)也会产生不小的损失,这一点在其图表中很容易看出。当对大量简单的示例进行总结时,这些小的损失值可能会淹没罕见的类别。
3.1 平衡交叉熵
解决类不平衡的一种常见方法是为类1引入加权因子α∈[0,1],为类−1引入1-α。在实践中,α可以通过反类频率设置,或者被视为通过交叉验证设置的超参数。为了便于记法,我们定义 α t α_t αt的方式类似于定义 p t p_t pt的方式。我们将α-balanced CE损失写成:

这种损失是对CE的简单扩展,我们将其视为我们提出的焦点损失的实验基线。
3.2 焦点损失定义
正如我们的实验所表明的,在密集检测器的训练过程中遇到的大类不平衡压倒了交叉熵损失。容易分类的阴性类构成了大部分损失,并主导了梯度。虽然α-balanced了阳性/阴性示例的重要性,但它没有区分容易/困难的示例。相反,我们建议重塑损失函数,以减轻权重简单的示例,从而将训练重点放在困难的阴性上。
更正式地说,我们建议在交叉熵损失中添加一个调制因子 ( 1 − p t ) γ (1−p_t)^γ (1−pt)γ,可调聚焦参数γ≥0。我们将焦点损失定义为:

在图1中,对于 γ ∈ [ 0 , 5 ] γ∈[0,5] γ∈[0,5]的几个值,可以直观地看到焦点损失。我们注意到焦点损失的两个性质。(1) 当一个示例被错误分类并且pt很小时,调制因子接近1,并且损失不受影响。作为 p t → 1 p_t→ 1 pt→1,因子变为0,并且对分类良好的示例的损失进行向下加权。(2) 聚焦参数 γ γ γ平滑地调整了简单示例向下加权的速率。当 γ = 0 γ=0 γ=0时,FL相当于CE,并且随着 γ γ γ的增加,调制因子的作用也同样增加(我们发现 γ = 2 γ=2 γ=2在我们的实验中效果最好)。
直观地,调制因子减少了来自简单示例的损失贡献,并扩展了示例接收低损失的范围。例如,在 γ = 2 γ=2 γ=2的情况下,与CE相比, p t = 0.9 p_t=0.9 pt=0.9分类的示例的损失将降低100倍,而在 p t ≈ 0.968 p_t≈0.968 pt≈0.968的情况下其损失将降低1000倍。这反过来又增加了纠正错误分类示例的重要性(对于 p t ≤ . 5 p_t≤.5 pt≤.5和 γ = 2 γ=2 γ=2,其损失最多可减少4倍)。
在实践中,我们使用焦点损失的α-balanced变体:

我们在实验中采用了这种形式,因为它比non-α-balanced形式的精度略有提高。最后,我们注意到,损失层的实现将计算p的sigmoid运算与损失计算相结合,从而提高了数值稳定性。
虽然在我们的主要实验结果中,我们使用了上面的焦损失定义,但其精确形式并不重要。在附录中,我们考虑了焦点损失的其他实例,并证明了这些实例同样有效。
3.3 类别不平衡与模型初始化
默认情况下,二分类模型被初始化为输出y=-1或1的概率相等。在这样的初始化下,在类别不平衡的情况下,频繁的类别造成的损失会主导总损失,并导致早期训练的不稳定。为了应对这种情况,我们在训练开始时为稀有类(前景)的模型估计的p值引入了“先验”的概念。我们用π表示先验,并将其设置为使得模型对稀有类实例的估计p较低,例如0.01。我们注意到,这是模型初始化的变化(见§4.1),而不是损失函数的变化。我们发现,在严重类别不平衡的情况下,这可以提高交叉熵和焦点损失的训练稳定性。
3.4 类别不平衡和两级检测器
两级检测器通常使用交叉熵损失进行训练,而不使用α-balanced或我们提出的损失。相反,他们通过两种机制来解决类别不平衡问题:(1)两级级联和(2)有偏差的微批量采样。第一个级联阶段是一个目标提案机制[35,24,28],它将几乎无限的可能目标位置集减少到一千或两千个。重要的是,所选择的提案不是随机的,而是可能对应于真实的目标位置,这消除了绝大多数容易产生的阴性。在训练第二阶段时,通常使用有偏采样来构建包含例如1:3比例的阳性与阴性示例的迷你批次。这个比率就像一个通过采样实现的隐含的α-balanced因子。我们提出的焦点损失旨在通过损失函数直接解决单级检测系统中的这些机制。
4. RetinaNet检测器
RetinaNet是一个单一的统一网络,由一个骨干网络和两个特定任务的子网络组成。主干负责计算整个输入图像上的卷积特征图,并且是一个非自卷积网络。第一个子网对骨干网的输出执行卷积目标分类;第二个子网执行卷积边界框回归。这两个子网络的特点是我们专门为一阶段密集检测提出的简单设计,见图3。虽然这些部件的细节有很多可能的选择,但如实验所示,大多数设计参数对精确值并不特别敏感。接下来我们将描述RetinaNet的每个组件。
特征金字塔网络主干:我们采用[20]中的特征金字塔网络(FPN)作为RetinaNet的骨干网络。简言之,FPN通过自上而下的路径和横向连接增强了标准卷积网络,因此该网络从单分辨率输入图像中有效地构建了丰富的多尺度特征金字塔,见图3(a)-(b)。金字塔的每个级别都可以用于检测不同比例的目标。FPN改进了全卷积网络(FCN)[23]的多尺度预测,如其对RPN[28]和DeepMask式方案[24]的增益所示,以及在两阶段检测器(如Fast R-CNN[10]或Mask R-CNN[14])中的增益。
在[20]之后,我们在ResNet架构[16]的基础上构建FPN。我们构建了一个具有级别 P 3 P_3 P3到 P 7 P_7 P7的金字塔,其中 l l l表示金字塔级别( P l P_l Pl的分辨率比输入低 2 l 2^l 2l)。如在[20]中一样,所有金字塔级别都具有C=256个通道。金字塔的细节通常遵循[20],但有一些适度的差异(RetinaNet使用特征金字塔级别 P 3 P_3 P3到 P 7 P_7 P7,其中 P 3 P_3 P3到 P 5 P_5 P5是使用自上而下和横向连接从相应的ResNet残差级( C 3 C_3 C3到 C 5 C_5 C5)的输出计算的,就像在[20]中一样,P6是通过 C 5 C_5 C5上的3×3 stride-2 卷积获得的, P 7 P_7 P7是通过在 P 6 P_6 P6上应用ReLU和3×3 stride-2 卷积来计算的。这与[20]略有不同:(1)由于计算原因,我们不使用高分辨率金字塔级 P 2 P_2 P2,(2) P 6 P_6 P6是通过跨步卷积而不是下采样计算的,(3)我们包括 P 7 P_7 P7以改进大目标检测。这些微小的修改在保持准确性的同时提高了速度)。虽然许多设计选择并不重要,但我们强调FPN主干的使用是;仅使用来自最终ResNet层的特征的初步实验产生低AP。
锚:我们使用了类似于[20]中RPN变体中的平移不变锚框。锚分别在金字塔水平 P 3 P_3 P3到 P 7 P_7 P7上具有 3 2 2 32^2 322至 51 2 2 512^2 5122的面积。如在[20]中所述,在每个金字塔级别,我们使用三种纵横比 { 1 : 2 、 1 : 1 、 2 : 1 } \{1:2、1:1、2:1\} { 1:2、1:1、2:1}的锚。对于比[20]中更密集的尺度覆盖,在每个级别上,我们添加原始3个纵横比锚的尺寸为 { 2 0 , 2 1 / 3 , 2 2 / 3 } \{2^0,2^{1/3},2^{2/3}\} { 20,21/3,22/3}的锚。这改善了我们设置中的AP。每个级别总共有A=9个锚点,在各个级别上,它们覆盖了相对于网络输入图像的32-813像素的比例范围。
每个锚点被分配一个长度K分类目标的独热向量,其中K是目标类的数量,以及一个框回归目标的4向量。我们使用RPN[28]中的分配规则,但针对多类检测进行了修改,并调整了阈值。具体地,使用0.5的交并比(IoU)阈值将锚点分配给真值目标框;如果它们的IoU在[0,0.4中,则设置为背景)。由于每个锚点最多分配给一个目标框,我们将其长度K标签向量中的相应条目设置为1,将所有其他条目设置为0。如果未分配锚点(可能在[0.4,0.5)中发生重叠),则在训练过程中会忽略该锚点。框回归目标计算为每个锚点与其分配的目标框之间的偏移,如果没有分配,则会忽略该目标。

图3. 单级RetinaNet网络架构使用前馈ResNet架构[16](a)之上的特征金字塔网络(FPN)[20]主干来生成丰富的多尺度卷积特征金字塔(b)。在这个主干上,RetinaNet连接了两个子网络,一个子网络用于对锚框进行分类(c),另一个子网络则用于从锚框回归到真值目标框(d)。网络设计有意简单,这使这项工作能够专注于一种新的焦点损失函数,该函数消除了我们的单级检测器和最先进的两级检测器之间的精度差距,如具有FPN[20]的Faster R-CNN,同时以更快的速度运行。
分类子网:分类子网预测A个锚点和K个目标类中的每一个的目标存在于每个空间位置的概率。该子网是连接到每个FPN级别的小型FCN;该子网的参数在所有金字塔级别上共享。它的设计很简单。从给定金字塔级别获取具有C通道的输入特征图,子网应用四个3×3 conv层,每个层具有C过滤器,每个层之后是ReLU激活,然后是具有KA过滤器的3×3 conv层。最后,附加sigmoid激活,以输出每个空间位置的KA二进制预测,见图3(c)。在大多数实验中,我们使用C=256和A=9。与RPN[28]相比,我们的目标分类子网更深,仅使用3×3 CONV,并且不与框回归子网共享参数(下面将描述)。我们发现这些更高层次的设计决策比超参数的特定值更重要。
框回归子网:与目标分类子网并行,我们将另一个小FCN附加到每个金字塔级别,目的是回归从每个锚框到附近真值目标的偏移量(如果存在)。框回归子网的设计与分类子网相同,只是它终止于每个空间位置的4A线性输出,见图3(d)。对于每个空间位置的每个A锚,这4个输出预测锚和真值框之间的相对偏移(我们使用R-CNN[11]中的标准框参数化)。我们注意到,与最近的工作不同,我们使用了一个类不可知的边界框回归器,它使用的参数更少,我们发现它同样有效。目标分类子网和框回归子网虽然共享一个公共结构,但使用不同的参数。
4.1 推理与训练
推理:RetinaNet形成一个单一的FCN,由ResNet FPN主干网、分类子网和框回归子网组成,见图3。因此,推理包括简单地通过网络转发图像。为了提高速度,在将检测器置信度阈值设置为0.05之后,我们仅对每个FPN级别最多1k个最高得分预测的框预测进行解码。合并来自所有级别的顶部预测,并应用阈值为0.5的非最大值抑制以产生最终检测。
焦点损失:我们使用本工作中引入的焦点损失作为分类子网输出上的损失。正如我们将在§5中所示,我们发现γ=2在实践中运行良好,并且RetinaNet对γ∈[0.5,5]相对稳健。我们强调,在训练RetinaNet时,焦点损失应用于每个采样图像中的所有~100k个锚。这与使用启发式采样(RPN)或困难示例挖掘(OHEM,SSD)为每个小批量选择一小组锚(例如,256)的常见做法形成对比。图像的总焦点损失计算为所有~100k个锚点的焦点损失之和,通过分配给真值框的锚点数量进行归一化。我们通过指定锚的数量而不是总锚的数量来执行归一化,因为绝大多数锚都是容易负的,并且在焦点损失下接收的损失值可以忽略不计。最后,我们注意到,分配给稀有类的权重α也有一个稳定的范围,但它与γ相互作用,因此有必要将两者一起选择(见表1a和1b)。一般情况下,α应随着γ的增加而略有下降(对于γ=2,α=0.25效果最好)。
初始化:我们用ResNet-50-FPN和ResNet-101-FPN主干进行了实验[20]。基础ResNet-50和ResNet-101模型在ImageNet1k上进行预训练;我们使用[16]发布的模型。为FPN添加的新层如[20]中所述进行初始化。除了RetinaNet子网中的最后一个层之外,所有新的conv层都用偏置b=0和σ=0.01的高斯权重填充进行初始化。对于分类子网的最终conv层,我们将偏差初始化设置为 b = − l o g ( ( 1 − π ) / π ) b=−log((1−π)/π) b=−log((1−π)/π),其中π指定在训练开始时,每个锚都应标记为前景,置信度为~π。我们在所有实验中都使用π=.01,尽管结果对精确值是稳健的。如§3.3所述,这种初始化防止了大量背景锚在训练的第一次迭代中产生大的、不稳定的损失值。

表1. RetinaNet和焦点损失(FL)的消融实验。除非另有说明,否则所有模型都在trainval35k上进行训练,并在minival上进行测试。如果未指定,默认值为:γ=2;用于3个比例和3个纵横比的锚;ResNet-50-FPN骨干网;以及600像素的序列和测试图像尺度。(a) 具有α-balanced CE的RetinaNet最多可达到31.1 AP。(b) 相反,使用具有相同精确网络的FL可获得2.9的AP增益,并且对精确的γ/α设置相当稳健。(c) 使用2-3比例和3纵横比锚产生良好的结果,之后点性能饱和。(d) FL的性能优于在线困难示例挖掘(OHEM)[31,22]的最佳变体3点AP。(e) RetinaNet在各种网络深度和图像尺度的test-dev中的准确性/速度权衡(另见图2)。
优化:RetinaNet使用随机梯度下降(SGD)进行训练。我们在8个GPU上使用同步SGD,每个小批量总共有16个图像(每个GPU有2个图像)。除非另有规定,否则所有模型都以0.01的初始学习率进行90k迭代的训练,然后在60k迭代时除以10,在80k迭代时再次除以10。除非另有说明,否则我们使用水平图像翻转作为数据增强的唯一形式。使用0.0001的权重衰减和0.9的动量。训练损失是用于框回归的焦点损失和标准平滑L1损失的总和[10]。对于表1e中的模型,训练时间在10到35小时之间。
5. 实验
我们介绍了具有挑战性的COCO基准[21]的边界框检测轨道的实验结果。对于训练,我们遵循常见做法[1,20],并使用COCO trainval35k划分(来自训练的80k图像和来自40k图像val划分的随机35k图像子集的联合)。我们报告了通过评估minival划分(来自val的剩余5k图像)进行的损伤和敏感性研究。对于我们的主要结果,我们报告了test-dev划分的COCO-AP,它没有公共标签,需要使用评估服务器。
5.1 密集检测训练
我们进行了大量的实验来分析密集检测的损失函数的行为以及各种优化策略。对于所有实验,我们使用深度50或101 ResNets[16],并在顶部构建特征金字塔网络(FPN)[20]。对于所有消融研究,我们使用600像素的图像尺度进行训练和测试。
网络初始化:我们第一次尝试训练RetinaNet使用标准交叉熵(CE)损失,而不对初始化或学习策略进行任何修改。这很快就失败了,网络在训练过程中会出现发散。然而,简单地初始化我们模型的最后一层,使检测到目标的先验概率为π=.01(见§4.1),就可以实现有效的学习。用ResNet-50训练RetinaNet,这种初始化已经在COCO上产生了30.2的可观AP。结果对π的精确值不敏感,因此我们对所有实验都使用π=.01。

图4. 收敛模型中不同γ值的正样本和负样本归一化损失的累积分布函数。对于正示例,改变γ对损失分布的影响很小。然而,对于负示例,增加γ会使损失严重集中在困难示例上,几乎所有的注意力都从容易的负示例上转移开。
平衡交叉熵:我们下一次改进学习的尝试涉及使用§3.1中描述的α-balanced CE损失。各种α的结果如表1a所示。设置α=.75可获得0.9点AP的增益。
焦点损失:使用我们提出的焦点损失的结果如表1b所示。焦点损失引入了一个新的超参数,焦点参数γ,它控制调制项的强度。当γ=0时,我们的损失相当于CE损失。随着γ的增加,损失的形状发生了变化,因此具有低损失的“简单”示例得到了进一步的折扣,见图1。随着γ的增加,FL表现出比CE大的增益。在γ=2的情况下,FL比α-balanced的CE损失提高了2.9AP。
对于表1b中的实验,为了进行公平的比较,我们发现每个γ的最佳α。我们观察到,对于较高的γ,选择较低的α(由于容易的阴性被向下加权,因此需要较少强调阳性)。然而,总的来说,改变γ的好处要大得多,事实上,最好的α仅在[0.25,.75]范围内(我们测试了α∈[0.01,.999])。我们在所有实验中使用γ=2.0,α=.25,但α=.5几乎同样有效(低.4AP)。
焦点损失分析:为了更好地理解焦点损失,我们分析了收敛模型的损失的经验分布。为此,我们采用默认的ResNet-101 600像素模型,该模型使用γ=2(具有36.0 AP)进行训练。我们将该模型应用于大量随机图像,并对$10^7$个负窗口和 1 0 5 10^5 105个正窗口的预测概率进行采样。接下来,对于阳性和阴性,我们分别计算这些样本的FL,并归一化损失,使其总和为1。给定归一化损失,我们可以从最低到最高对损失进行排序,并绘制正样本和负样本以及γ的不同设置的累积分布函数(CDF)(即使模型是用γ=2训练的)。
阳性和阴性样本的累积分布函数如图4所示。如果我们观察阳性样本,我们会发现不同γ值的CDF看起来相当相似。例如,大约20%的最困难阳性样本约占阳性损失的一半,随着γ的增加,更多的损失集中在前20%的样本中,但影响很小。
γ对阴性样品的影响是显著不同的。对于γ=0,正CDF和负CDF非常相似。然而,随着γ的增加,更多的权重集中在困难阴性的示例上。事实上,当γ=2(我们的默认设置)时,绝大多数损失来自一小部分样本。可以看出,FL可以有效地淡化容易阴性的效果,将所有注意力集中在困难阴性的示例上。
在线困难示例挖掘(OHEM):[31]提出了通过使用高损失示例构建迷你批次来改进两阶段检测器的训练。具体来说,在OHEM中,每个示例都根据其损失进行评分,然后应用非最大值抑制(nms),并用最高损失的示例构建迷你批次。nms阈值和批处理大小是可调的参数。与焦点损失一样,OHEM更强调错误分类的示例,但与FL不同,OHEM完全抛弃了简单的示例。我们还实现了SSD中使用的OHEM的变体[22]:在将nms应用于所有示例之后,构建迷你批次以强制执行阳性和阴性之间的1:3比例,以帮助确保每个迷你批次都有足够的阳性。
我们在一阶段检测的环境中测试了两种OHEM变体,这具有较大的类别不平衡。原始OHEM策略和“OHEM 1:3”策略对选定批次大小和nms阈值的结果如表1d所示。这些结果使用ResNet-101,我们用FL训练的基线在这种设置下达到36.0 AP。相反,OHEM的最佳设置(没有1:3的比例,批量大小128,nms为.5)达到32.8 AP。这是一个3.2 AP的差距,表明FL在训练密集检测器方面比OHEM更有效。我们注意到,我们尝试了OHEM的其他参数设置和变体,但没有取得更好的结果。
合页损失:最后,在早期的实验中,我们试图用 p t p_t pt上的合页损失[13]进行训练,该损失在 p t p_t pt的某个值以上设置为0。然而,这是不稳定的,我们未能获得有意义的结果。探索替代损失函数的结果见附录。

表2. 目标检测单模型结果(边界框AP)与COCO test-dev的最先进技术。我们展示了我们的RetinaNet-101-800模型的结果,该模型使用比例抖动进行训练,比表1e中的相同模型长1.5倍。我们的模型取得了最好的结果,优于单阶段和两阶段模型。有关速度与精度的详细细分,请参见表1e和图2。
5.2 模型架构设计
锚密度:单级检测系统中最重要的设计因素之一是它覆盖可能的图像框空间的密度。两级检测器可以使用区域池操作对任何位置、尺度和纵横比的框进行分类[10]。相比之下,由于单级检测器使用固定的采样网格,在这些方法中,实现框高覆盖率的一种流行方法是在每个空间位置使用多个“锚”[28]来覆盖各种尺度和纵横比的框。
我们扫过FPN中每个空间位置和每个金字塔级别使用的比例和纵横比锚的数量。我们考虑了从每个位置的单个方形锚到每个位置的12个锚的情况,这些锚跨越4个sub-octave尺度( 2 k / 4 2^{k/4} 2k/4,对于k≤3)和3个纵横比[0.5,1,2]。使用ResNet-50的结果如表1c所示。仅使用一个方形锚就实现了令人惊讶的良好AP(30.3)。然而,当每个位置使用3个尺度和3个纵横比时,AP可以提高近4个点(到34.0)。我们在这项工作的所有其他实验中都使用了这个设置。
最后,我们注意到,超过6-9个锚并没有显示出进一步的收益。因此,虽然两阶段系统可以对图像中的任意框进行分类,但性能关于密度的饱和意味着两阶段系统的更高潜在密度可能不会带来优势。
速度与准确性:较大的主干网络产生更高的准确性,但推理速度也较慢。对于输入图像比例(由较短的图像侧定义)也是如此。我们在表1e中显示了这两个因素的影响。在图2中,我们绘制了RetinaNet的速度/准确性权衡曲线,并将其与最近在COCO test-dev中使用公共数字的方法进行了比较。该图显示,由于我们的焦点损失,RetinaNet在所有现有方法中形成了一个上限,而不考虑低精度方案。具有ResNet-101-FPN和600像素图像标度的RetinaNet(为了简单起见,我们用RetinaNet-101-600表示)与最近发布的ResNet-101-FPN Faster R-CNN[20]的精度相匹配,同时每张图像的运行时间为122毫秒对比172毫秒(均在Nvidia M40 GPU上测量)。使用更大的规模可以使RetinaNet超越所有两阶段方法的准确性,同时仍然更快。对于更快的运行时间,只有一个操作点(500像素输入)使用ResNet-50-FPN比ResNet-101-FPN有所改进。解决高帧速率机制可能需要特殊的网络设计,如[27]所述,这超出了本工作的范围。我们注意到,在发表后,[12]中的faster R-CNN变体现在可以获得更快、更准确的结果。
5.3 与现有技术的比较
我们在具有挑战性的COCO数据集上评估了RetinaNet,并将test-dev结果与最近最先进的方法(包括一阶段和两阶段模型)进行了比较。表2中显示了我们的RetinaNet-101-800模型的结果,该模型使用比例抖动进行训练,比表1e中的模型长1.5倍(给出1.3的AP增益)。与现有的一阶段方法相比,我们的方法与最接近的竞争对手DSSD[9]实现了健康的5.9点AP差距(39.1对33.2),同时速度也更快,见图2。与最近的两阶段方法相比,RetinaNet比基于Inception-ResNet-v2-TDM[32]的性能最高的Faster R-CNN模型高出2.3个百分点。插入ResNeXt-32x8d-101-FPN[38]作为RetinaNet主干进一步提高了1.7个AP,超过了COCO上的40个AP。
6. 结论
在这项工作中,我们将类别不平衡确定为阻止单级目标检测器超越性能最佳的两级方法的主要障碍。为了解决这一问题,我们提出了焦点损失,它将调制项应用于交叉熵损失,以便将学习集中在困难阴性示例上。我们的方法简单而高效。我们通过设计全卷积单级检测器来证明其有效性,并报告了大量的实验分析,表明其达到了最先进的精度和速度。源代码位于https://github.com/facebookresearch/Detectron[12]

图5. 作为 x t = y x x_t=yx xt=yx的函数,与交叉熵相比的焦点损失变化。对于分类良好的示例 ( x t > 0 ) (x_t>0) (xt>0),原始FL和备选变体FL*都降低了相对损失。

表3. 选定设置的FL和FL*与CE的对比结果。
附录A:焦点损失*
焦点损失的确切形式并不重要。我们现在展示了焦点损失的另一个实例,该实例具有相似的特性并产生可比较的结果。以下内容还提供了对焦点损失特性的更多见解。
我们首先以与正文略有不同的形式考虑交叉熵(CE)和焦点损失(FL)。具体来说,我们定义一个量 x t x_t xt如下:

其中 y ∈ { ± 1 } y∈\{±1\} y∈{ ±1}指定了如前所述的真值类。然后我们可以写 p t = σ ( x t ) p_t=σ(x_t) pt=σ(xt)(这与方程2中 p t p_t pt的定义兼容)。当 x t > 0 x_t>0 xt>0时,一个示例被正确地分类,在这种情况下 p t > . 5 p_t>.5 pt>.5。
我们现在可以用 x t x_t xt来定义焦点损失的另一种形式。我们对 p t ∗ p^*_t pt∗和 F L ∗ FL* FL∗的定义如下:

FL有两个参数,γ和β,控制损失曲线的陡峭度和偏移。我们在图5中绘制了两个选定设置γ和β的FL以及CE和FL。可以看出,与FL一样,具有选定参数的FL*减少了分配给分类良好的示例的损失。
我们使用与以前相同的设置来训练RetinaNet-50-600,但我们用选定的参数将FL替换为FL*。这些模型实现了与用FL训练的模型几乎相同的AP,见表3。换言之,FL*是FL的一个合理替代方案,在实践中效果良好。
我们发现,各种γ和β设置都给出了良好的结果。在图7中,我们显示了在一组广泛的参数下,具有FL*的RetinaNet-50-600的结果。损失图是彩色编码的,使得有效设置(模型收敛且AP超过33.5)显示为蓝色。为了简单起见,我们在所有实验中都使用了α=0.25。可以看出,减少分类良好的示例 ( x t > 0 ) (x_t>0) (xt>0)的权重的损失是有效的。
更普遍地说,我们期望任何与FL或FL*具有类似性质的损失函数都同样有效。

图6. 根据图5 关于x推导损失函数。

图7. FL*在不同设置γ和β下的有效性。绘图是用颜色编码的,因此有效设置显示为蓝色。
附录B:导数
作为参考,CE、FL和FL*关于x的导数为:
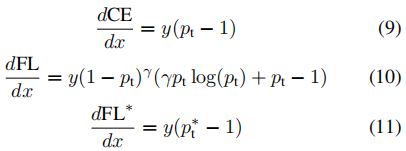
所选设置的图如图6所示。对于所有损失函数,对于高置信度预测,导数往往为-1或0。然而,与CE不同的是,对于FL和FL*的有效设置,只要 x t > 0 x_t>0 xt>0,导数就很小。
References
[1] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, 2016. 6
[2] S. R. Bulo, G. Neuhold, and P. Kontschieder. Loss maxpooling for semantic image segmentation. In CVPR, 2017.3
[3] J. Dai, Y. Li, K. He, and J. Sun. R-FCN: Object detection via region-based fully convolutional networks. In NIPS, 2016. 1
[4] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, 2005. 2
[5] P. Doll´ar, Z. Tu, P. Perona, and S. Belongie. Integral channel features. In BMVC, 2009. 2, 3
[6] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. In CVPR, 2014.2
[7] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes (VOC) Challenge. IJCV, 2010. 2
[8] P. F. Felzenszwalb, R. B. Girshick, and D. McAllester. Cascade object detection with deformable part models. In CVPR, 2010. 2, 3
[9] C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg. DSSD: Deconvolutional single shot detector. arXiv:1701.06659, 2016. 1, 2, 8
[10] R. Girshick. Fast R-CNN. In ICCV, 2015. 1, 2, 4, 6, 8
[11] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014. 1, 2, 5
[12] R. Girshick, I. Radosavovic, G. Gkioxari, P. Doll´ar, and K. He. Detectron. https://github.com/facebookresearch/detectron, 2018. 8
[13] T. Hastie, R. Tibshirani, and J. Friedman. The elements of statistical learning. Springer series in statistics Springer, Berlin, 2008. 3, 7
[14] K. He, G. Gkioxari, P. Doll´ar, and R. Girshick. Mask R-CNN. In ICCV, 2017. 1, 2, 4
[15] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV. 2014. 2
[16] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016. 2, 4, 5, 6, 8
[17] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, and K. Murphy. Speed/accuracy trade-offs for modern convolutional object detectors. In CVPR, 2017. 2, 8
[18] A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012. 2
[19] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural computation, 1989. 2
[20] T.-Y. Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017. 1, 2, 4, 5, 6, 8
[21] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick. Microsoft COCO: Common objects in context. In ECCV, 2014. 1, 6
[22] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, and S. Reed. SSD: Single shot multibox detector. In ECCV, 2016. 1, 2, 3, 6, 7, 8
[23] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. 4
[24] P. O. Pinheiro, R. Collobert, and P. Dollar. Learning to segment object candidates. In NIPS, 2015. 2, 4
[25] P. O. Pinheiro, T.-Y. Lin, R. Collobert, and P. Doll´ar. Learning to refine object segments. In ECCV, 2016. 2
[26] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In CVPR, 2016. 1, 2
[27] J. Redmon and A. Farhadi. YOLO9000: Better, faster, stronger. In CVPR, 2017. 1, 2, 8
[28] S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015. 1, 2, 4, 5, 8
[29] H. Rowley, S. Baluja, and T. Kanade. Human face detection in visual scenes. Technical Report CMU-CS-95-158R, Carnegie Mellon University, 1995. 2
[30] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. In ICLR, 2014.2
[31] A. Shrivastava, A. Gupta, and R. Girshick. Training region-based object detectors with online hard example mining. In CVPR, 2016. 2, 3, 6, 7
[32] A. Shrivastava, R. Sukthankar, J. Malik, and A. Gupta. Beyond skip connections: Top-down modulation for object detection. arXiv:1612.06851, 2016. 2, 8
[33] K.-K. Sung and T. Poggio. Learning and Example Selection for Object and Pattern Detection. In MIT A.I. Memo No.1521, 1994. 2, 3
[34] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. A. Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In AAAI Conference on Artificial Intelligence, 2017. 8
[35] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. IJCV, 2013. 2, 4
[36] R. Vaillant, C. Monrocq, and Y. LeCun. Original approach for the localisation of objects in images. IEE Proc. on Vision, Image, and Signal Processing, 1994. 2
[37] P. Viola and M. Jones. Rapid object detection using a boosted cascade of simple features. In CVPR, 2001. 2, 3
[38] S. Xie, R. Girshick, P. Doll´ar, Z. Tu, and K. He. Aggregated residual transformations for deep neural networks. In CVPR, 2017. 8
[39] C. L. Zitnick and P. Doll´ar. Edge boxes: Locating object proposals from edges. In ECCV, 2014. 2