Focal Loss for Dense Object Detection
论文地址:https://arxiv.org/pdf/1708.02002.pdf
何凯明 ICCV 2017 best student paper
论文核心:提出了一种用于单阶段目标检测算法的聚焦损失函数
论文的出发点
读完本论文后,这里我自己总结一下。
论文的出发点总结了当前两阶段目标检测算法和单阶段目标检测算法的优缺点。
两阶段目标检测算法:
- 第一阶段能过滤掉无关背景,第二阶段更精细化包围框回归,所以两阶段目标检测算法精确度更高;
- 由于有两个阶段,算法训练与检测都很耗时,实时性上没有单阶段目标检测算法好;
单阶段目标检测算法:
- 只有一个阶段,直接利用生成的anchor框进行回归,生成的anchor框中存在着大多数的无关背景,单阶段算法的精确度没有两阶段算法高;
- 只有一个阶段,没有第一阶段进行前景和背景的选择,时效性更好,更便于落地;
作者的出发点:
作者对比了单阶段与两阶段的目标检测算法,发现两者各自都有优缺点。所以作者产生了一个思路,想训练和学习一个单阶段目标检测器,能够保证时效性的同时也提高其准确率提升到两阶段目标检测算法的水平。
发现问题
作者的出发点已经确定了,那么下面几个问题需要解决:
- 两阶段目标检测算法有第一阶段淘汰大量的无关背景anchor,那么单阶段目标检测算法的准确度低是什么原因造成的呢?
imbalance encountered during training of dense detectors is the central cause To achieve this result, we identify class imbalance during training as the main obstacle impeding one-stage detector from achieving state-of-the-art accuracy and propose a new loss function that eliminates this barrier. ```
所遇到的极端的前景背景类不平衡是中心原因
问题解释
因为anchors/default boxes近似于sliding window的方式会使正负样本接近1000:1,而绝大部分负样本都是easy example,这就导致gradient被easy example主导: 这些easy example虽然loss很低,但由于数量众多,对于loss依旧有很大贡献,从而导致收敛到不够好的一个结果。
训练集存在着类别不平衡导致训练是低效的,因为大多数位置都是简单的负样本,没有提供有用的学习信号;
总的来说,简单的负样本会压倒训练,导致退化模型。 一个常见的解决方案是执行某种形式的硬负样本挖掘
两阶段目标检测算法是如何解决类别不平衡问题的?
它们通过两种机制来解决类不平衡:(1)两阶段级联和(2)biased minibatch sampling 。
- 两阶段级联:也就是通过第一阶段过滤掉大量的背景框,保留可能性最高的前景框,比如FasterRCNN中第一阶段生成的anchor有上万个,通过RPN过滤掉大多数前景框,只保留300-2000个anchor
- biased minibatch sampling:也就是很典型的硬负样本挖掘,一般使得正负样本的比例为1:3
解决问题
如何解决单阶段目标检测算法中的极端背景和前景的类别不平衡问题呢?
作者的思路是修改交叉熵分类损失函数!!!
目的:
修改交叉熵损失函数的目的就是为了使得简易样本对损失函数的贡献变小,使得损失函数的贡献集中到硬负样本上来。

Cross Entropy 交叉熵损失
传统的二分类交叉熵损失函数是

所以交叉熵损失函数也可以写成:
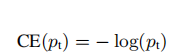
Balanced Cross Entropy 平衡交叉熵损失
一个解决类别不平衡的公认的方法是为正类添加比例因子a和为负类添加比例因子1-a。
作者将这这种方法引入的平衡损失函数作为改进算法的baseline.

对于平衡交叉熵损失的理解,举例一个正样本p=0.9,一个负样本p=0.1,这两个样本都分类错误。
正常的交叉熵损失loss = -0.9log0.9 - (1-0.1)log(1-0.1)=-(0.9log0.9+0.9log0.9)。
从公式上来看,这两个样本分类错误对损失函数做出的贡献是一致的。
举例加上平衡因子a=0.75后,计算的平衡交叉熵损失为loss=-0.75*(0.9log0.9)-0.25*(0.9log0.9)=-3/4*(0.9log0.9+1/3*0.9log0.9)
这相当于在损失函数上惩罚了负样本。
因为生成的anchor中绝大多数都是负样本,所以惩罚负样本能够使得损失函数更多的看重正样本分类错误的损失。
其实这么做的目的和难样本挖掘使得正样本和负样本的比例为1:3的思想抑制,只不过难样本挖掘是减少负样本参与训练的数量,平衡交叉熵损失是减少负样本对与损失函数的贡献。
**
Focal Loss
作者设计了一个损失函数对交叉熵损失函数进行改进
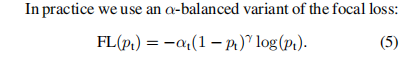
关于聚焦损失函数的优点:
- 当一个例子被错误分类且pt较小时,调制因子接近1,损失不受影响。 由于pt→1,因子变为0;
- 当分类良好的例子,pt较大,调制因子接近0,比如的0.12*log0.9损失相比交叉熵损失log0.9是向下加权的,这表明了简单的样本对于损失函数的贡献明显被抑制,使得损失函数更多的关注硬负样本,相对比平衡交叉熵损失仅仅只是抑制某一类样本而言更能够使得损失函数更多的关注于硬负样本;
- 根据图中显示,聚焦参数γ平稳地调整简单样本被降权的速度。

通过Focal Loss构造单节段目标检测器

观察这个网络结构,基本上就是单阶段FPN+Focal Loss
classification子网是一个全卷积网络,仅仅使用3*3的卷积层,分类子网预测每个A锚和K个对象类在每个空间位置的对象存在的概率。

box regression子网也是一个全卷积网络,

实验结果

用到的技巧
- FPN中anchor的设置;
- 基于速度与精确度的权衡;