paper:Channel-wise Knowledge Distillation for Dense Prediction
official implementation:https://github.com/irfanICMLL/TorchDistiller/tree/main/SemSeg-distill
摘要
之前大多数用于密集预测dense prediction任务的蒸馏方法在空间域spatial domain中将教师和学生网络的激活图进行对齐,通过标准化normalize每个空间位置的激活值,并减小point-wise and/or pair-wise之间的差异来实现知识的传递。
和之前的方法不同,本文提出对每个通道的激活图进行标准化从而得到一个soft probabality map,通过减小两个网络channel-wise概率图之间的KL散度,使蒸馏过程更关注每个通道最显著的区域,这对密集预测任务非常有价值。

背景
密集预测任务是像素级的预测问题,比图像级的分类问题更具挑战性。以往的研究发现,直接将分类中的蒸馏方法应用到语义分割中得到的效果令人无法满意。严格地对齐教师和学生网络之间poit-wise分类得分或特征图可能会施加过于严格的约束,只能得到次优解。
最近的一些研究主要关注于加强不同空间位置之间的相关性。如图2(a)所示,每个空间位置上的激活值被标准化然后通过聚合不同空间位置的子集来得到一些特定任务的关系,比如pair-wise relations和inter-class relations。这些方法在捕获空间结构信息和提高学生网络的性能方面可能比point-wise对齐效果更好。然而,激活图中的每个空间位置对知识转移的贡献相同,这可能会从教师网络带来冗余的信息。
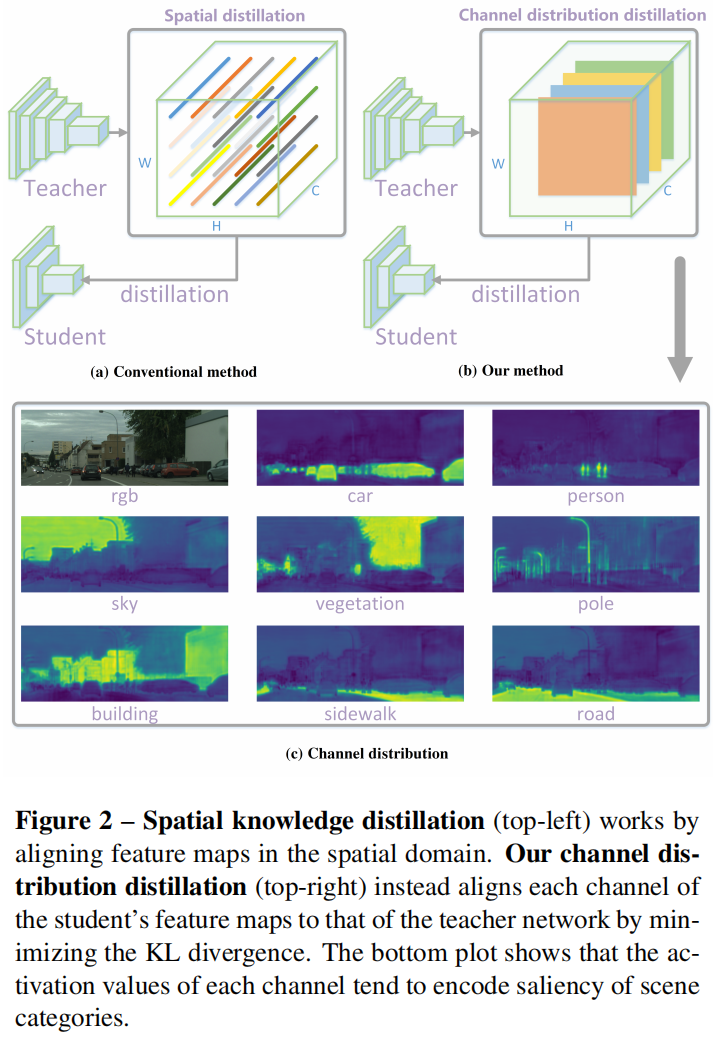
本文提出了一种新的通道级channel-wise知识蒸馏方法,通过对每个通道中的激活图进行标准化,用于密集预测任务,如图2(b)所示。然后减小教师和学生网络标准化后的通道激活图之间的KL散度。一个channel-wise distribution的例子如图2(c)所示,可以看出每个通道的激活图倾向于编码特定场景类别的显著区域。对于每个通道,引导学生网络更加关注于模拟激活值大的区域,从而在密集预测任务中实现更准确的定位。比如在目标检测任务中,让学生网络更关注于学习前景区域的激活。
本文的贡献
- 与现有的spatial蒸馏方法不同,本文提出了一种新的通道蒸馏范式用于密集预测任务,方法简单有效。
- 在语义分割和目标检测方面,本文提出的通道级蒸馏方法显著优于最先进的KD方法。
- 我们在语义分割和目标检测任务上的四个基准数据集上进行了一致的改进,证明了我们的方法是通用的。鉴于它的简单性和有效性,我们相信我们的方法可以作为一个strong baseline KD方法用于密集预测任务。
方法介绍
为了更好的利用每个通道中的知识,作者提出softly对齐教师网络和学生网络对应通道的激活。为此,首先将一个通道的激活转换为概率分布,这样就可以使用一个概率距离度量例如KL散度来衡量差异。如图2(c)所示,不同通道的激活倾向于编码输入图像中某个特定类别场景的显著saliency区域。此外,一个训练好的语义分割教师模型在每个通道显示出了清晰的类别特定掩码的激活图,这是符合预期的,如图1右侧所示。因此作者提出了一种新的通道蒸馏范式来指导学生从一个训练有素的教师那里学习知识。
首先定义教师网络和学生网络分别为 \(T\) 和 \(S\),\(T\) 和 \(S\) 的激活分别表示为 \(y^{T}\) 和 \(y^{S}\),通道蒸馏损失的一般表示形式如下
![]()
其中 \(\phi(\cdot)\) 用于将激活值转换为概率分布,如下

其中 \(c=1,2,...,C\) 表示通道,\(i\) 示一个通道的spatial location的索引,\(\mathcal{T}\) 是温度超参。如果我们使用更大的 \(\mathcal{T}\),概率分布会变得更softer,意味着每个通道中关注的spatial region更加wider。通过使用softmax归一化,消除了大网络和小网络之间尺度的差异。如果教师网络和学生网络的通道不匹配,则使用1x1卷积上采样小网络的通道数使两者相等。\(\varphi(\cdot)\) 评估教师模型和学生模型通道分布之间的差异,具体使用KL散度
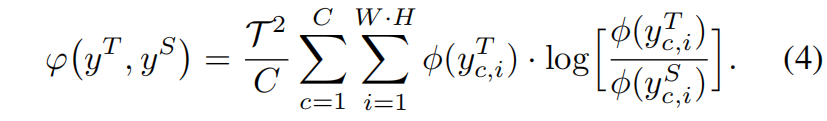
KL散度是一种非对称度量。从式4可以看出,如果 \(\phi(y^{T}_{c,i})\) 很大,\(\phi(y^{S}_{c,i})\) 应该像 \(\phi(y^{T}_{c,i})\) 一样大从而减小KL散度。相反,如果 \(\phi(y^{T}_{c,i})\) 非常小,KL散度对减小 \(\phi(y^{S}_{c,i})\) 的关注相对较少。通过教师网络的监督,学生网络倾向于在前景显著区域产生和教师网络相似的激活分布,而教师网络背景区域中的激活对学生网络的影响较小。作者认为KL这种不对称性有助于密集预测任务中蒸馏的学习。
和分类任务中的channel-wise蒸馏的区别
在Channel Distillation: Channel-Wise Attention for Knowledge Distillation这篇文章中,作者也提出了使用通道蒸馏的方式,但主要应用于分类任务。受SENet的启发,通过全局平局池化将一个通道的特征图转换为一个标量,然后应用KL散度衡量教师网络和学生网络对应通道的标量之间的差异。
而本文主要考虑的是密集预测任务,GAP或许对image-level的分类任务有帮助,但所有空间位置的权重相同,丢失了空间信息,不适用于密集预测任务。本文通过softmax标准化的方式,考虑到了不同空间位置重要性的不同,保留了空间位置信息,因此更适用于密集预测任务。
实验结果
表2是本文提出的channel蒸馏和其它spatial蒸馏在Cityscapes数据集上复杂度和验证集上的mIoU的对比,可以看出通道蒸馏的精度最高,且复杂度较小

表5是在Cityscapes数据集上,不同的学生模型用不同的蒸馏方法的精度对比,可以看出,对于不同结构的学生网络,本文提出的通道蒸馏的效果都要好于其它蒸馏方法。

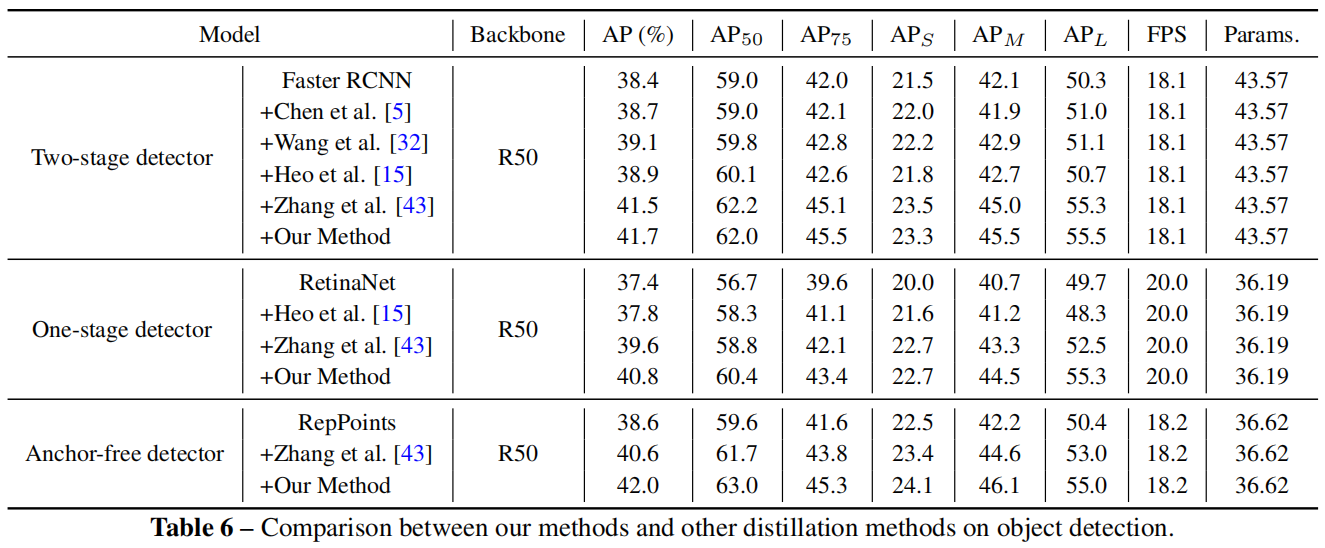
表6是在目标检测任务上与其它蒸馏方法的对比,可以看出,在两阶段、单阶段、anchor-free不同结构的目标检测模型中,本文提出的通道蒸馏的效果都是最好的。
代码解析
官方实现如下,其中归一化采用channel_norm损失采用KL损失是论文中给出的方法,官方实现中还给出了其它的归一化方法和损失函数的选择。
import torch.nn as nn
class ChannelNorm(nn.Module):
def __init__(self):
super(ChannelNorm, self).__init__()
def forward(self, featmap):
n, c, h, w = featmap.shape
featmap = featmap.reshape((n, c, -1))
featmap = featmap.softmax(dim=-1)
return featmap
class CriterionCWD(nn.Module):
def __init__(self, norm_type='none', divergence='mse', temperature=1.0):
super(CriterionCWD, self).__init__()
# define normalize function
if norm_type == 'channel':
self.normalize = ChannelNorm()
elif norm_type == 'spatial':
self.normalize = nn.Softmax(dim=1)
elif norm_type == 'channel_mean':
self.normalize = lambda x: x.view(x.size(0), x.size(1), -1).mean(-1)
else:
self.normalize = None
self.norm_type = norm_type
self.temperature = 1.0
# define loss function
if divergence == 'mse':
self.criterion = nn.MSELoss(reduction='sum')
elif divergence == 'kl':
self.criterion = nn.KLDivLoss(reduction='sum')
self.temperature = temperature
self.divergence = divergence
def forward(self, preds_S, preds_T):
n, c, h, w = preds_S.shape
# import pdb;pdb.set_trace()
if self.normalize is not None:
norm_s = self.normalize(preds_S / self.temperature)
norm_t = self.normalize(preds_T.detach() / self.temperature)
else:
norm_s = preds_S[0]
norm_t = preds_T[0].detach()
if self.divergence == 'kl':
norm_s = norm_s.log()
loss = self.criterion(norm_s, norm_t)
# item_loss = [round(self.criterion(norm_t[0][0].log(),norm_t[0][i]).item(),4) for i in range(c)]
# import pdb;pdb.set_trace()
if self.norm_type == 'channel' or self.norm_type == 'channel_mean':
loss /= n * c
# loss /= n * h * w
else:
loss /= n * h * w
return loss * (self.temperature ** 2)