paper:Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes
official implementation:GitHub - ydhongHIT/DDRNet: The official implementation of "Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes"
third-party implementation:https://github.com/open-mmlab/mmsegmentation/tree/main/configs/ddrnet
方法介绍
本文的创新点主要是设计了一个新的网络Deep Dual-resolution Network, DDRNet和一个Deep Aggregation Pyramid Pooling Module, DAPPM。在DDRNet中,包含一个high-resolution的spatial分支和一个low-resolution的context分支,作者设计了一种新的bilateral fusion来更好的融合两个分支的信息,具体包括high-to-low fusion和low-to-high fusion。在DAPPM中,为了更好的从low-resolution特征中提取语义信息,作者借鉴了Res2Net的思想,以一种hierarchial-residual的方式来融合不同尺度的语义信息。
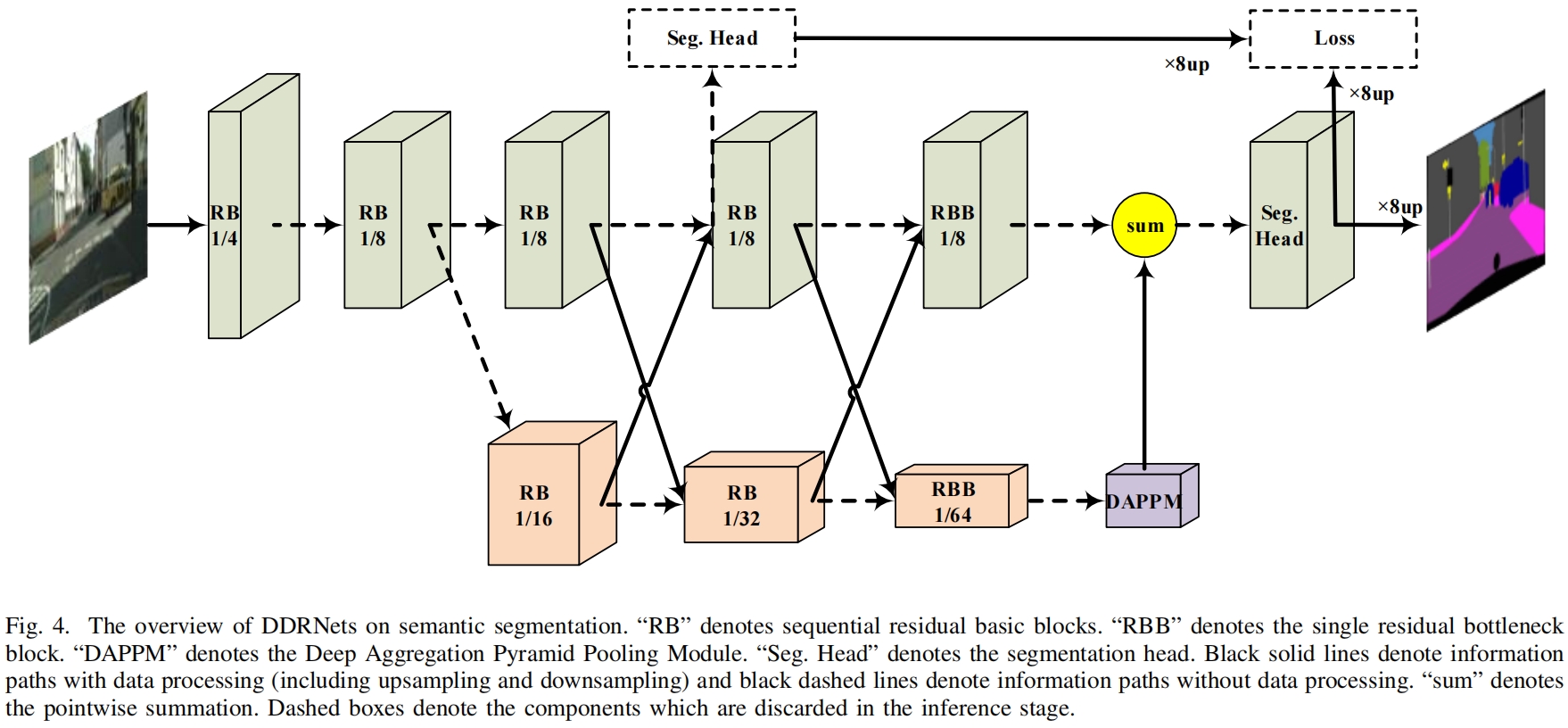
DDRNet的完整结构如下图所示
DDRNet和其它常见语义分割backbone结构的对比如下图

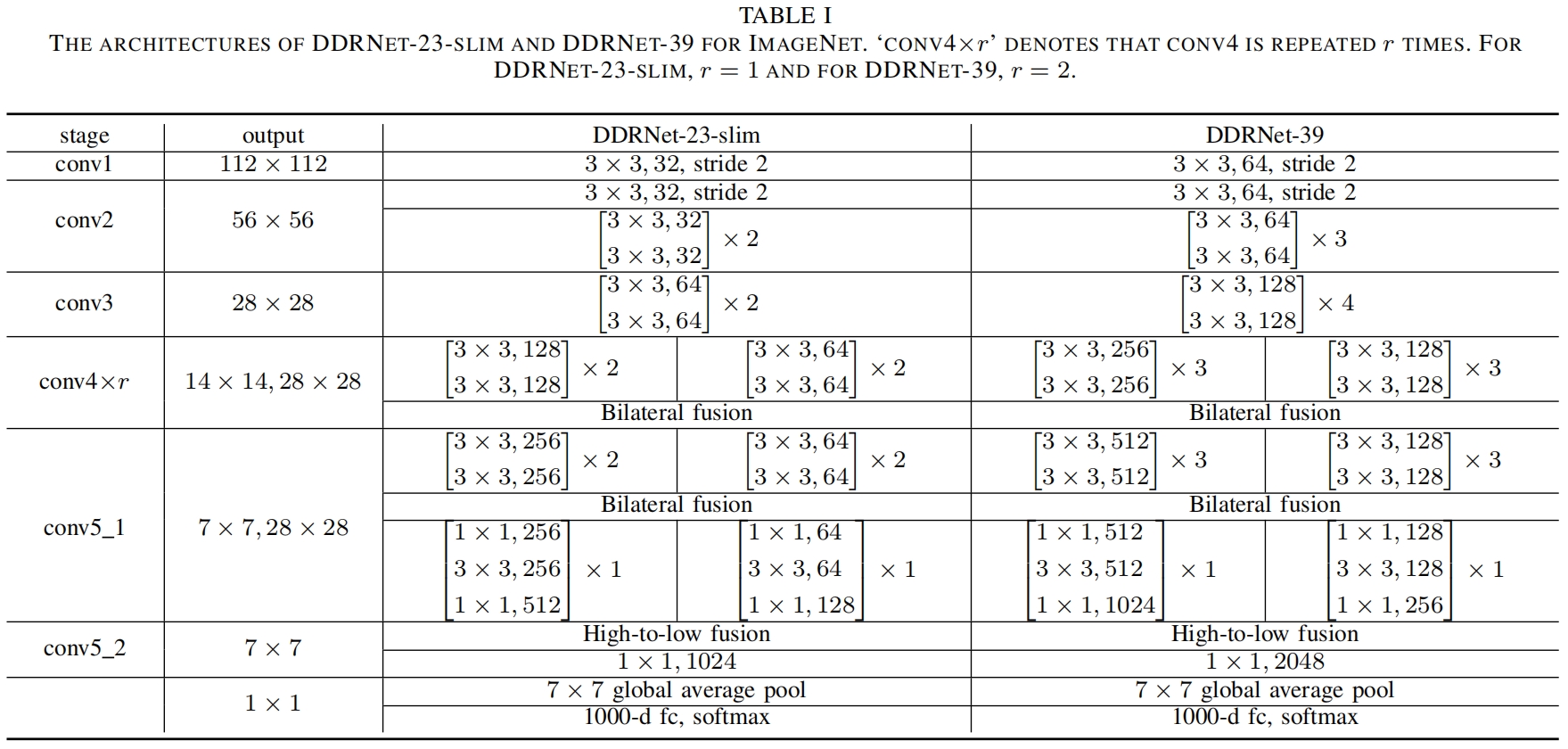
作者采用不同的depth和width设计了四种尺度的网络DDRNet-23、DDRNet-23-slim、DDRNet-39、DDRNet-39 1.5x,其中DDRNet-23 is twice as wide as DDRNet-23-slim,DDRNet-39 1.5x is a 1.5 wider version of DDRNet-39。DDRNet-23-slim和DDRNet-39的具体结构如下表所示
Bilateral fusion的结构如下图所示,其中低分辨率的context特征上采样后与高分辨率的spatial特征融合后得到spatial分支的输出,即low-to-high fusion。反过来高分率的spatial特征下采样后与低分辨率的context特征融合得到context分支的输出,即high-to-low fusion。

DAPPM的结构如下所示,其中借鉴了Res2Net的思想,关于Res2Net的介绍见Res2Net_x = checkpoint.checkpoint(_inner_forward, x)_00000cj的博客-CSDN博客

代码解析
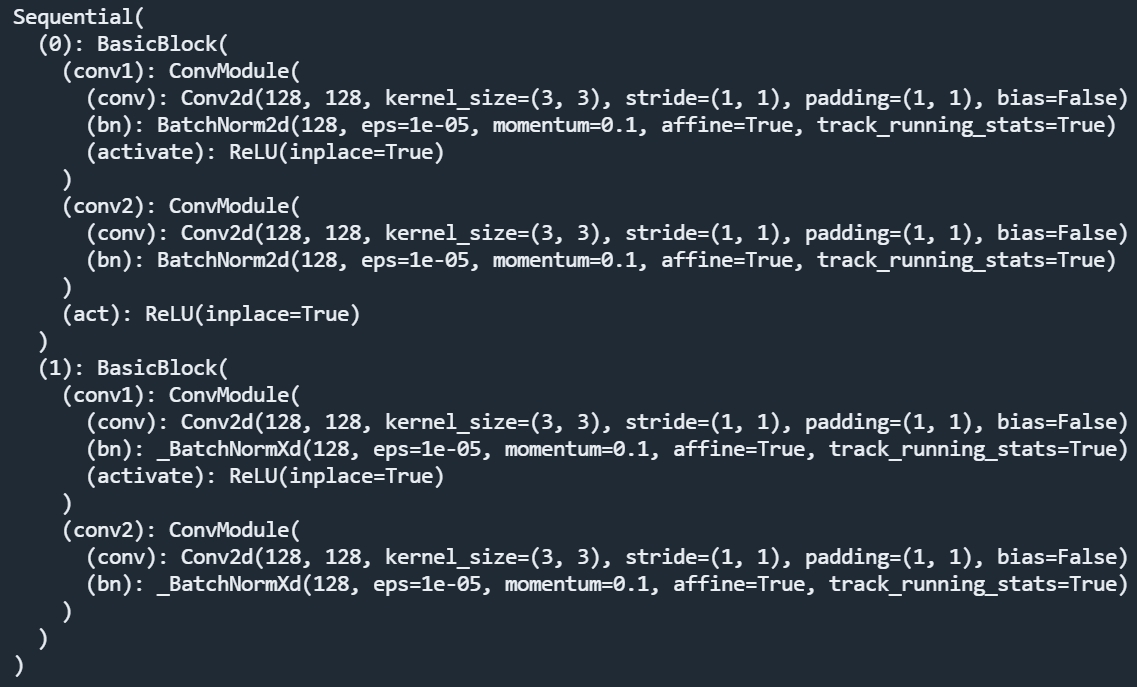
ddrnet的网络结构实现在mmsegmentation/mmseg/models/backbones/ddrnet.py中,这里输入shape为(16, 3, 480, 480)。self.stem包括表1中的conv1、conv2、conv3,其中conv2、3中是ResNet中的BasicBlock结构,得到输出(16, 128, 60, 60)。
然后网络就分成了context和spatial两个分支,经过3个stage的bilater fusion,这里以第一个阶段的bilateral fusion为例介绍一下具体实现。
# stage3
x_c = self.context_branch_layers[0](x) # (16,256,30,30)
x_s = self.spatial_branch_layers[0](x) # (16,128,60,60)
comp_c = self.compression_1(self.relu(x_c)) # (16,128,30,30)
x_c += self.down_1(self.relu(x_s)) # (16,256,30,30)
x_s += resize(
comp_c,
size=out_size,
mode='bilinear',
align_corners=self.align_corners) # (16,128,60,60)输入x就是conv3的输出。context分支和spatial分支结构如下,都由两个BasicBlock构成,区别在于context分支进行了stride=2的下采样,同时输出通道是spatial分支的两倍。

然后context分支的输出经过1x1卷积即self.compression_1将通道数减半和spatial分支一样,然后经过bilinear上采样使得分辨率也与spatial分支一样,然后与spatial分支的输出相加得到输出x_s。而原始的spatial分支的输出经过3x3 stride=2的卷积即self.down_1将通道数翻倍分辨率减半与context分支保持一致,然后与contenxt分支的原始输出相加得到输出x_c。
另外在stage5中,两个分支中的BasicBlock换成了BottleNeck,即图4中的RBB,两者的区别见https://blog.csdn.net/ooooocj/article/details/122226401
stage5中的self.spp就是DAPPM,实现如下
class DAPPM(BaseModule):
"""DAPPM module in `DDRNet <https://arxiv.org/abs/2101.06085>`_.
Args:
in_channels (int): Input channels.
branch_channels (int): Branch channels.
out_channels (int): Output channels.
num_scales (int): Number of scales.
kernel_sizes (list[int]): Kernel sizes of each scale.
strides (list[int]): Strides of each scale.
paddings (list[int]): Paddings of each scale.
norm_cfg (dict): Config dict for normalization layer.
Default: dict(type='BN').
act_cfg (dict): Config dict for activation layer in ConvModule.
Default: dict(type='ReLU', inplace=True).
conv_cfg (dict): Config dict for convolution layer in ConvModule.
Default: dict(order=('norm', 'act', 'conv'), bias=False).
upsample_mode (str): Upsample mode. Default: 'bilinear'.
"""
def __init__(self,
in_channels: int,
branch_channels: int,
out_channels: int,
num_scales: int,
kernel_sizes: List[int] = [5, 9, 17],
strides: List[int] = [2, 4, 8],
paddings: List[int] = [2, 4, 8],
norm_cfg: Dict = dict(type='BN', momentum=0.1),
act_cfg: Dict = dict(type='ReLU', inplace=True),
conv_cfg: Dict = dict(
order=('norm', 'act', 'conv'), bias=False),
upsample_mode: str = 'bilinear'):
super().__init__()
self.num_scales = num_scales
self.unsample_mode = upsample_mode
self.in_channels = in_channels
self.branch_channels = branch_channels
self.out_channels = out_channels
self.norm_cfg = norm_cfg
self.act_cfg = act_cfg
self.conv_cfg = conv_cfg
self.scales = ModuleList([
ConvModule(
in_channels,
branch_channels,
kernel_size=1,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
**conv_cfg)
])
for i in range(1, num_scales - 1):
self.scales.append(
Sequential(*[
nn.AvgPool2d(
kernel_size=kernel_sizes[i - 1],
stride=strides[i - 1],
padding=paddings[i - 1]),
ConvModule(
in_channels,
branch_channels,
kernel_size=1,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
**conv_cfg)
]))
self.scales.append(
Sequential(*[
nn.AdaptiveAvgPool2d((1, 1)),
ConvModule(
in_channels,
branch_channels,
kernel_size=1,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
**conv_cfg)
]))
self.processes = ModuleList()
for i in range(num_scales - 1):
self.processes.append(
ConvModule(
branch_channels,
branch_channels,
kernel_size=3,
padding=1,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
**conv_cfg))
self.compression = ConvModule(
branch_channels * num_scales,
out_channels,
kernel_size=1,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
**conv_cfg)
self.shortcut = ConvModule(
in_channels,
out_channels,
kernel_size=1,
norm_cfg=norm_cfg,
act_cfg=act_cfg,
**conv_cfg)
def forward(self, inputs: Tensor): # (16,1024,8,8)
feats = []
feats.append(self.scales[0](inputs))
for i in range(1, self.num_scales):
feat_up = F.interpolate(
self.scales[i](inputs),
size=inputs.shape[2:],
mode=self.unsample_mode)
feats.append(self.processes[i - 1](feat_up + feats[i - 1]))
# [(16,128,8,8),(16,128,8,8),(16,128,8,8),(16,128,8,8),(16,128,8,8)]
return self.compression(torch.cat(feats,
dim=1)) + self.shortcut(inputs) # (16,256,8,8)其中self.scales就是图5中最上面两行的池化、卷积、上采样

实验结果
在cityscapes上和其它模型的对比
