0. 前言
这是一篇2021年1月份发表的关于实时语义分割的文章,目前在arXiv上还可以下载,不过上面标注了该论文之后可能版权会有所变化,大家可以先抓紧下载下来。论文传送门
作者给出的代码实现:github-DDRNet
1. Abstract
实时语义分割对于自动驾驶技术的发展十分重要,近年来发展迅速,已经有技术可以在一张1080Ti显卡上实现超过100FPS的速度。但是本文作者认为对于目前的实时语义分割,速度和性能之间的最佳平衡还没有找到,换句话来说就是有些实时的方法并不能达到很好地性能。本文提出了一种新的语义信息提取结构——深度融合金字塔池化模块(Deep Aggregation Pyramid Pooling Module, DAPPM),他能够增大感受野和更好地融合图像语义信息。虽然上面的这几个词都已经被各大论文说烂了,但是本文提出的方法在一些常用的驾驶场景分割数据集上(Cityscapes, Camvid等)无论是速度还是准确率都优于目前其它的实时语义分割方法。
2. Introduction
因为语义分割是一种稠密细致的预测任务,所以我们需要获得图像的高分辨率特征图和大的感受野以获得更好的结果。
基于HRNet,本文提出一种新的深度双分辨率网络(deep dual resolution network,简称DDRNet)。DDRNet有两个并行的分支,深度分支用来获得高分辨率的特征表示,语义分支用来提取丰富的语义信息。另外,本文还提出了DAPPM(Deep Aggregation Pyramid Pooling Module,简称DAPPM)模块来进行特征融合和金字塔池化,以获取更加丰富的语义信息。
3. Related Work
现在语义分割大致可以分为两个方向:高精度的语义分割和实时语义分割。高精度语义分割追求高的准确率,基本受推理时间的限制,已经取得了很好的发展。而实时语义分割要求在需要很少推理时间的同时还要基本保证精度,发展相对来说还比较滞后。
实时语义分割中,比较流行的大致分为三种结构:
基于编码器-解码器的结构,如ERFNet和ESPNet等;基于双路径信息融合的结构,如BiSeNet系列和Fast-SCNN等,本文属于这种结构;基于轻量级编码器的结构,如Xception、MobileNets系列、ShuffleNets系列等。
对于现有的特征提取模块,本文也做了一个简单的总结。经典的模块有基于空洞卷积(扩张卷积)的ASPP以及PSPNet中的PPM等。注意力机制也被加入特征提取模块中,大致分为空间级注意力与通道级注意力,使用注意力机制的轻量级网络优OCNet和CCNet等,本文的结构,同时具有空间级注意力和通道级注意力的优点。
4. Method
作者在这一部分首先重新思考了一下HRNet,然后基于HRNet提出了用于图像分类的双分辨率网络,再对预训练好的双分辨率网络进行修正来完成图像分割任务。
4.1 重新思考HRNet
在本文中,HRNet有狭义和广义的解释。狭义来说,HRNet就是在论文High-Resolution Representations for Labeling Pixels and Regions中提出的一种用于目标检测或语义分割的网络。广义来说,HRNet泛指通常具有高分辨率特征流的特征提取网络(整个特征提取过程中的所有特征全是高分辨率的网络)。
本文作者又开始思考能否设计一种简化的HRNet以达到实时语义分割的要求。语义分割中的两个关键点就是丰富的语义信息和大的感受野,也就是基于这一点,本文作者提出DDRNet,换句话来说,也就是将HRNet简化成有两个分支组成的网络,而DDRNet的好处就在于,占用更少的内存资源,达到实时的效果。
个人觉得这段是本文中比较失败的一个自然段,因为读完了这段给人的感觉就是这文章不就是将HRNet改成了类似BiSeNet的双分支结构,感觉创新点并不是很足。
4.2 双分辨率图像分类网络
4.2.1 整体结构
为了了解整个双分辨率图像分类网络的整体结构,我们可以先简单回顾一下ResNet18和ResNet34的结构,如下两图:
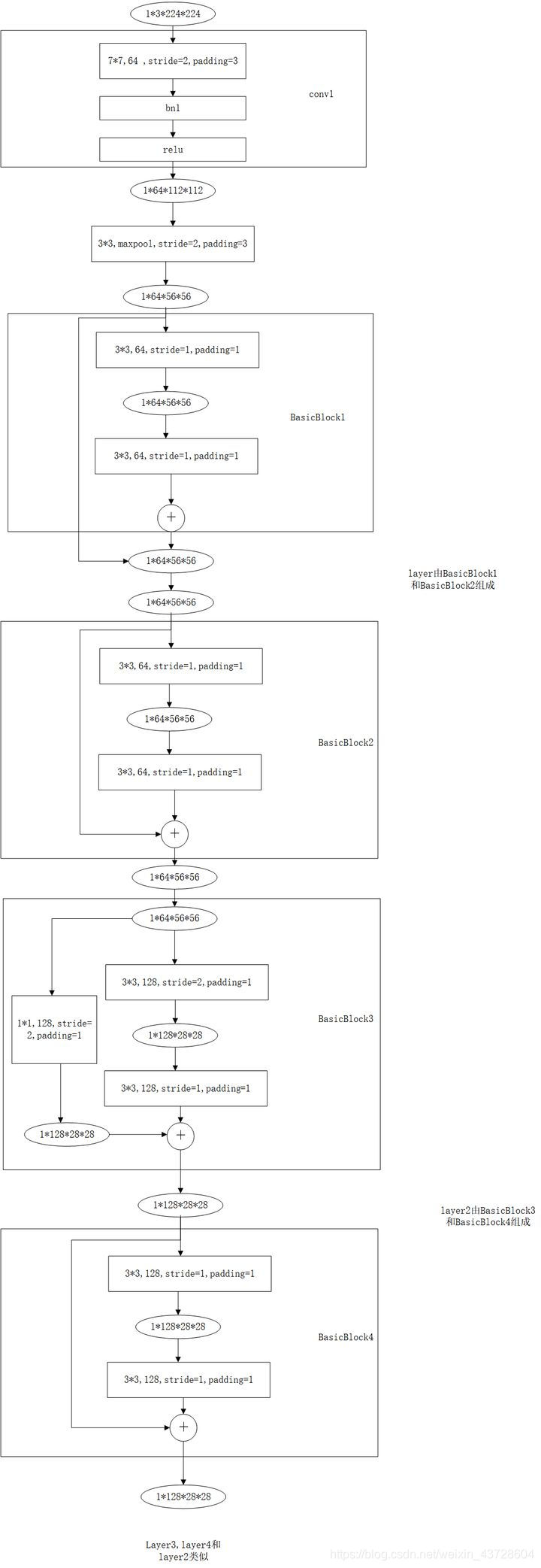
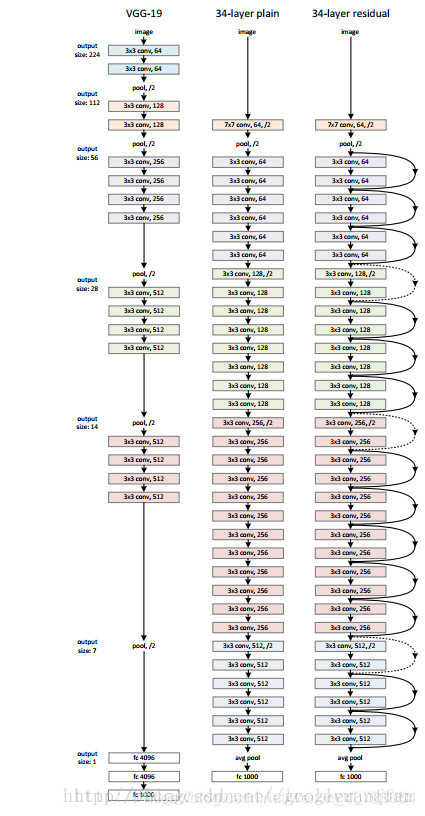
(以上两图分别引自知乎和CSDN上其它博主的文章)
回顾完ResNet,我们来说一说DDRNet(分类)的整体结构。整体结构很简单,作者为了方便直接在现有的分类性能很好的backbone上也就是ResNet上添加了一个高分辨率分支。本文构建的高分辨率分支最后的输出是输入的1/8,而低分辨率分支最后的输出是输入的1/32,这个在原始backbone上新加的高分辨率分支不使用池化,而是使用步长为2的卷积一步一步来进行下采样操作。DDRNet的三种结构,整体的参数如下面两个表所示:(表中初始的输入尺寸为224x224,conv1的output尺寸为112x112)


从两个表中和原文中可知,这个双分支结构是从conv3之后开始的,conv1阶段,ResNet用的是一个7x7卷积(参考上文回顾ResNet的部分),在本文中,作者将一个7x7卷积改为两个连续的3x3卷积。整体的结构在这两张表上非常清晰,所以我建议你忽略原文中那两个不太像公式的公式,其实表达的就是图中的这个结构。
4.2.2 Bilateral fusion
从整体结构中我们可以看出,有一种Bilateral fusion(双边融合)的东西将两个分支的的特征进行了融合,用原文的话来说,这个东西由High-to-low fusion 和Low-to-high fusion组成,具体的结构如下图所示。

这种交叉结构乍一看就让我想起了BiSeNetV2中似乎也有这样的结构,所以没有什么太创新的东西,就是利用两个方向不同的卷积以及相加,就可以将两个分支的特征融合起来,形成更好的高分辨率的特征。从高分辨率分支到低分辨率分支的卷积和相加就是High-to-low fusion,反过来就是Low-to-high fusion。从Table1和Table2中可以看到,在两个分支最后还有一次High-to-low fusion的操作。
4.2.3 训练过程
阅读关于深度学习的论文,了解模型的训练过程是很重要的,如果对训练的一些参数不了解,可能我们在复现时很难达到原文的效果。
本文将DDRNet在ImageNet数据集上进行训练,采用和ResNet论文中提到的相同的数据增加的方法。输入图像的尺寸为224x224,在4块2080Ti上进行训练,batchsize为256, batchsize为256,初始学习率为0.1,在训练到30、60、90epoch时,学习率减少10倍,共训练100epoch,使用SGD优化算法,weight衰减率为0.0001, Nesterov动量为0.9.
训练完了作者发现DDRNet在ImageNet上的表现并不如其他的轻量级分类网络好,但是后面在图像分割数据集上的表现却很不错,这也就是为啥这篇论文标题没提分类的事情。
4.3 DAPPM
论文在这部分基本就介绍了DAPPM的结构以及与PSPnet中的PPM模块之间的对比。
首先结构如下图所示:

图中上采样采用的方法是双线性插值,粉色的部分是平均池化操作,不同尺度下的横向连接是直接相加(以上细节参看原文代码)。这个模块的输入特征图的尺寸是原始输入的1/64,也就是说如果样本的分辨率是1024x1024,那么输入特征图的尺寸就是16x16。也正是因为这个输入尺寸特别小,所以并不会增加很多推理时间。
本文还通过下表来与PPM进行比较,证明DAPPM能够提取到更丰富的语义特征。

4.4 整体DDRNet语义分割的网络结构

整体的结构如上图,上边一条主线是高分辨率分支,下边是低分辨率分支,RB是Residual block(残差块),RBB是bottleblock。DAPPM就是4.3中的结构。图中的虚线连接表示不经过上采样或下采样处理,实线连接则代表有那样的处理。Seg.Head可以理解为额外的监督机制,这是为了让网络训练的更好,可以通过改变seg.head上的卷积通道数来改变计算复杂度。之前的论文中Seg.Head上使用的是3x3卷积,这里作者改为3x3连接1x1。所有的模块都在ImageNet上进行了预训练。
从图中来看,深度监督的Loss值获得过程如下:
通过上采样Seg.Head获得的特征图,RB1/8生成的特征图经过Seg.Head也得到的特征图,这两个特征图通过比较获得误差Loss。(文中没有提到具体的损失函数)
4.5 深度监督
这部分就介绍了上面Seg.Head监督机制产生的损失如何加到整个的损失中。这里应该有个系数加权之后再把这个辅助损失加到里面,公式如下:

注意其中的 α \alpha α就是上面说的系数,这个系数应该通过大量的实验来得到,本文直接追随PSPNet的脚步将系数设置为0.4.
4.6 与其他双边结构进行比较
这一部分主要就是将DDRNet与BiseNet和Fast-SCNN进行简单比较。BiseNet的问题就是没有使用深度监督,而且仅仅使用非常浅的卷积层来提取高分辨率特征,很难提高分割精度。Fast-SCNN前三层没有分成两个分支,但是与BiseNet的问题一样,也是提取高分辨率特征的结构特别浅。
DDRNet开始于Fast-SCNN一样共用一个分支,然后采用的双分支结构联系紧密并且有一定深度,还利用深度监督和预训练增加了优势,最终获得了比较高的分割精度。
5. 实验部分
5.1 数据集
本论文采用的数据集为Cityscapes和Camvid。
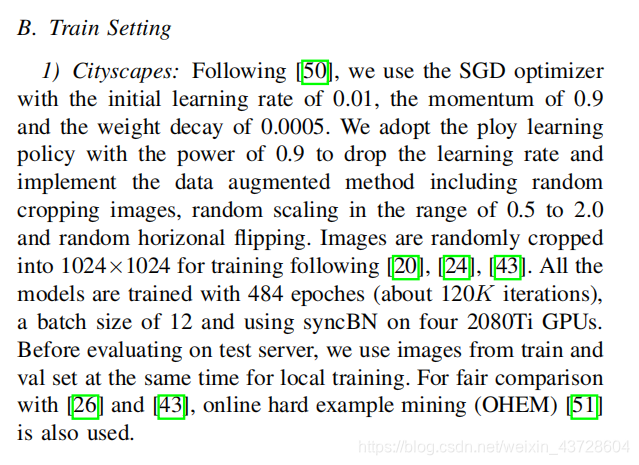
5.2 训练相关设置
论文中介绍的十分详细,原文如下:

5.3 测量推理速度的方法
测量推理时间时,BatchSize设置为1,在2080Ti上推理500次求平均时间,在测试时需要把BN层去掉。
5.4 结果比较