一,DAN
由于使用了关键点热力图的可视化信息,故可以将整张图输入网络。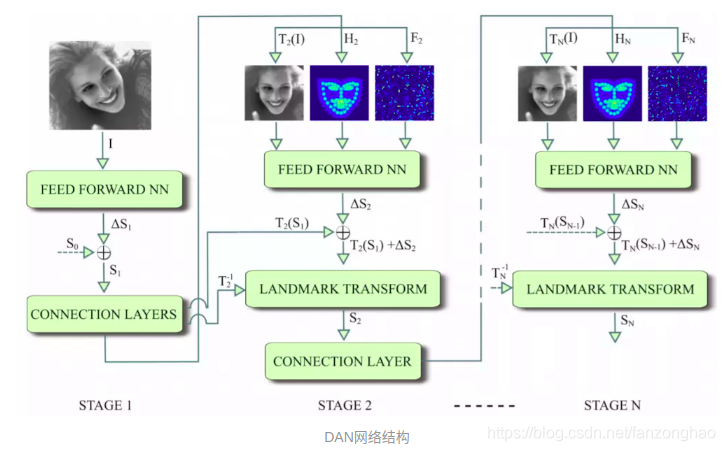

网络分为多个阶段(STAGE),每个阶段的结构都是相同的(STAGE 1除外)。第一阶段的输入仅有原始图片,和S0。面部关键点的初始化即为S0,S0是由所有关键点取平均得到。每个STAGE都由前馈网络和connection层组成。前馈网络用来估计特征点的位置,connection层生成下一个STAGE的输入。connection层由Transform Estimation层, Image Transform 层, Landmark Transform 层, Heatmap Generation 层 和 Feature Generation 层组成。结构如下:
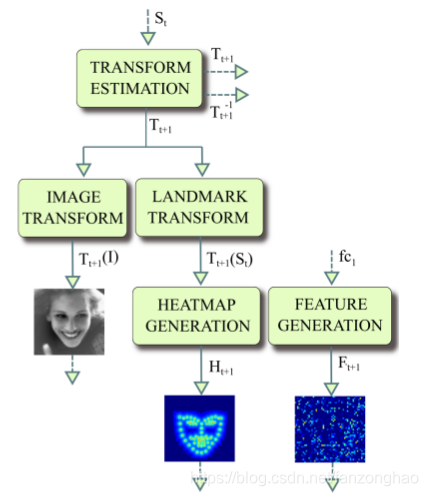
transform estimation 层生成变换,t是当前stage的序号。变换(IMAGE TRANSFORM 和 LANDMARK TRANSFORM)用来扭曲输入图像
和当前的特征点
,使得
和规范形态的
接近。变换后的特征点
被传入热度图生成层。逆变换
用来将前面几个stage生成的特征点映射到原来的坐标系。

从图中发现,DAN要做的“变换”,就是把图片给矫正了,尤其是一行,那么DAN对姿态变换具有很好的适应能力,或许就得益于这个“变换”。