本文介绍的Deep Interest NetWork是阿里妈妈盖坤带领的团队2018年8月发表在KDD的Paper,在点击率预估等场景有不错的效果。由于最近团队也准备尝试下该模型,因此提前熟悉下DIN的原理与实现。

引言
点击率预估在搜索、推荐、广告等领域具有很广泛及成功的应用,众多学者和公司也纷纷发表了相关Paper。随着深度学习在计算机视觉,自然语言处理等领域的重大突破,有许多研究将DNN模型应用于CTR预估中,常见的比如,DeepFM, Wide&Deep,PNN等。这类模型将原始高维的离散特征映射为固定长度的低维embedding向量,并将embedding向量作为多个全连接层的输入,拟合高阶的非线性关系,最后通过Sigmoid等手段将输出值归一到0~1,表示点击概率。相比于传统的LR、GBDT、FM等模型,这类DNN的模型能减少大量的人工构造特征过程,并且能学习特征之间的非线性关系。
但是,上述DNN模型也存在一定的问题,利用固定维度的embedding向量表示用户的兴趣多样性是有限制的。为了增加模型的多样性学习能力,往往会扩充embedding向量的维度。而广告场景的样本比例往往是不平衡的,在训练样本有限的情况下,扩充特征维度将容易导致过拟合,并且增加了模型训练的负担。
此外,针对某一条广告,没必要将用户的所有兴趣都同等对待,往往决定用户点击的只有一部分兴趣。传统基于DNN的CTR预估模型对用户的历史行为是同等对待的,一般离当前时间越近的行为,越能反应用户目前的兴趣。因此,DIN利用attention机制对用户历史行为进行了不同的加权处理,针对不同的广告,用户历史行为的权重不一致。
Deep Interest NetWork有以下三点创新:
- 利用attention机制实现Local Activation,从用户历史行为中动态学习用户兴趣的embedding向量;
- CTR中特征稀疏而且维度高,通常利用L1、L2、Dropout等手段防止过拟合。由于传统L2正则计算的是全部参数,CTR预估场景的模型参数往往数以亿计。DIN提出了一种正则化方法,在每次小批量迭代中,给与不同频次的特征不同的正则权重;
- 由于传统的激活函数,如Relu在输入小于0时输出为0,将导致许多网络节点的迭代速度变慢。PRelu虽然加快了迭代速度,但是其分割点默认为0,实际上分割点应该由数据决定。因此,DIN提出了一种数据动态自适应激活函数Dice。

数据特征
DIN构建的特征分为四类:分别是用户特征、用户行为特征、广告特征、上下文特征。特征均被变换为one-hot或者multi-hot形式的数据。然后,通过DNN学习数据之间的交叉特征。
模型结构
首先,介绍一般的DNN模型结构,大致分为以下几个部分:
- Embedding Layer: 原始数据是高维且稀疏的0-1矩阵,emdedding层用于将原始高维数据压缩成低维矩阵;
- Pooling Layer : 由于不同的用户有不同个数的行为数据,导致embedding矩阵的向量大小不一致,而全连接层只能处理固定维度的数据,因此,利用Pooling Layer得到一个固定长度的向量。
![]()
- Concat Layer: 经过embedding layer和pooling layer后,原始稀疏特征被转换成多个固定长度的用户兴趣的抽象表示向量,然后利用concat layer聚合抽象表示向量,输出该用户兴趣的唯一抽象表示向量;
- MLP:将concat layer输出的抽象表示向量作为MLP的输入,自动学习数据之间的交叉特征;
- Loss:损失函数一般采用Loglos



传统DNN模型在Embedding Layer -> Pooling Layer得到用户兴趣表示的时候,没有考虑用户与广告之间的关系,即不同广告之间的权重是一致的。之前也分析过,这样是有问题的。因此,DIN利用attention机制,在得到用户兴趣表示时赋予不同的历史行为不同的权重,即通过Embedding Layer -> Pooling Layer+attention实现局部激活。从最终反向训练的角度来看,就是根据当前的候选广告,来反向的激活用户历史的兴趣爱好,赋予不同历史行为不同的权重。

DIN认为用户的兴趣不是一个点,而是一个多峰的函数。一个峰就表示一个兴趣,峰值的大小表示兴趣强度。那么针对不同的候选广告,用户的兴趣强度是不同的,也就是说随着候选广告的变化,用户的兴趣强度不断在变化。
attention的公式如下:

其中,ei表示用户U历史行为embedding向量,wj表示ej的权重,Vu表示用户所有行为embedding向量的加权和,表示用户的兴趣。候选广告影响着每个behavior id的权重,也就是Local Activation。权重表示的是:每一个behavior id针对当前的候选广告Va,对总的用户兴趣表示的Embedding Vector的贡献大小。在实际实现中,权重用激活函数Dice的输出来表示,输入是Vi和Va。
自适应激活函数Dice
DIN提出了一种数据动态自适应激活函数Dice,认为分割点不是固定为0的,而是随着数据不同而动态变化的。 Dice公式如下:
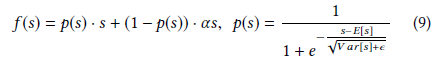
ps的计算分为两步:
- 对进行正态分布归一化处理,使得数据集中在正态分布均值处;
- 利用sigmoid函数归一化,使得输出在0~1之间。
f(s)的作用可以理解为一种平滑操作,alpha是一个超参数,推荐值为0.99。
高效正则器
由于DNN模型往往十分复杂,而且参数较多。利用L1,L2等正则手段往往加重了模型过拟合,DIN提出了一种高效的正则方法:

由于数据中有些feature id出现次数较少,这在训练过程中将引入很多噪声,从而加重了过拟合风险。DIN构造的正则器会针对id出现的频率不同,动态调整其参数的正则化力度。即,出现频率较高的id,给与较小的正则化力度,反之,则加大力度。
总结
DIN通过引入attention机制,针对不同的广告构造不同的用户抽象表示,从而实现了在数据维度一定的情况下,更精准地捕捉用户当前的兴趣。此外,DIN模型也适用于其他有丰富行为数据的场景,比如,电商中的个性化推荐,以及当前比较火热的feed流推荐等。
参考文献
【1】计算广告CTR预估系列(五)--阿里Deep Interest Network理论
【2】Deep Interest Network for Click-Through Rate Prediction
【3】DIN githup开源