论文的原题目为:You Only Look Once: Unified, Real-Time Object Detection
作为一种新的目标检测算法,相比于之前的fast-RCNN,Faster-R-CNN等,其最大的区别是将检测问题转换为回归问题。之前的目标检测算法都是先通过CNN生成大量的region proposal,即可疑目标区域,然后再在这些区域中进一步进行CNN的特征提取,检测出目标。而yolo的实现则是end-to-end的思路,直接通过CNN输出class以及物体的区域,也就是bounding box。其实现过程如下图所示,就像论文标题一样,只需要一眼就能检测出图中的物体。只需要通过一个cnn网络就直接输出物体的bounding box,class,以及置信度。

在不通过Titan x进行batch processing 的情况下,处理速度已经能达到45帧每秒,其中的小版本的快速网络速度能达到150帧每秒,这意味着可以进行实时的视频处理,等待延时能降低到25ms以下。所以,总结一下,yolo相对于之前的目标检测算法,其特点是算法结构更加简单,速度更快。
原理分析
yolo网络通过CNN从整张的输入图片里提取特征,并使用这些特征来预测bounding box以及class,置信度。yolo的实现一个创新点,是通过将图片分割成s*s个的小网格,如果在图片中,待检测物体的中心落在其中的一个小网格中,那么这个物体就由这个小网格负责检测。在其他的网络中就认为没有这个物体,也就是说将物体检测任务分派到各个物体中心所在的网格中。这样做的目的是提高bounding box的IOU值。如下图

每一个网格会输出B个 bounding box(物体尺寸的缘故,有的物体偏向于竖的长方形,有的偏向于横着的长方形),每一个bounding box除了这个box中检测到物体的坐标(X,Y,W,H),(X,Y)代表物体的中心点的坐标(原点是每一个网格的左上角),W,H代表物体的宽度以及高度(相对于整张图片)。还包括一个置信度,置信度反映的是bounding box中含有物体的可能性以及预测的box和ground truth box之间的iou值。其计算过程如下:
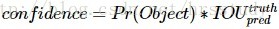
需要注意的是,在实际计算过程中,首先要判断这个网格是否有被分配到物体。如果这个并没有物体的中心落在这个网格中,那么置信度就会被计算成0。
所以加起来每个bounding box会输出5个值。
每一个网格除了会输出B个bounding box外,还会输出C个class值,也就是这个网格中物体各个类别的概率
Pr(Classi|Object)。在测试时,将每个栅格的conditional class probabilities与每个 bounding box的 confidence相乘:
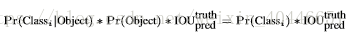
得到的类别概率不仅反映box中类别概率值的大小,还会反映每一个box中,预测的框与实际物体拟合程度的好坏。
所以总共加起来 每输入一张图片,最终的输出是S ×S ×(B ∗5 + C) 个tensor。在实际的实现过程中,yolo将每张图片分割成7*7个网格,每个网格输出2个bounding box,每个网格含有20个物体类别的概率。所以每张图片经过CNN后的最终输出是7*7*(2*5+20)个Tensor,如下图所示:
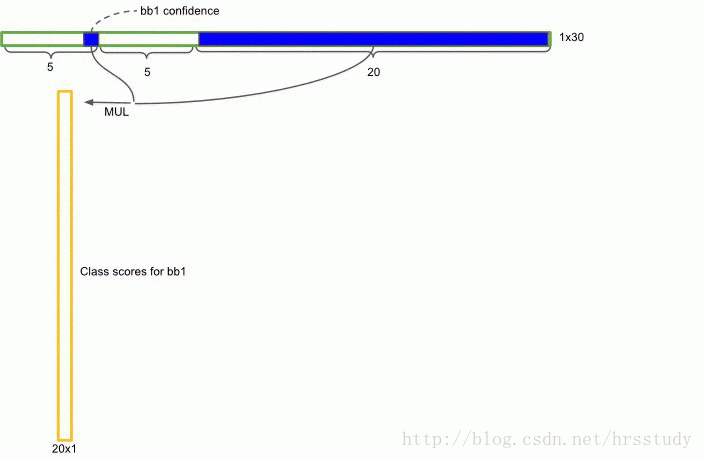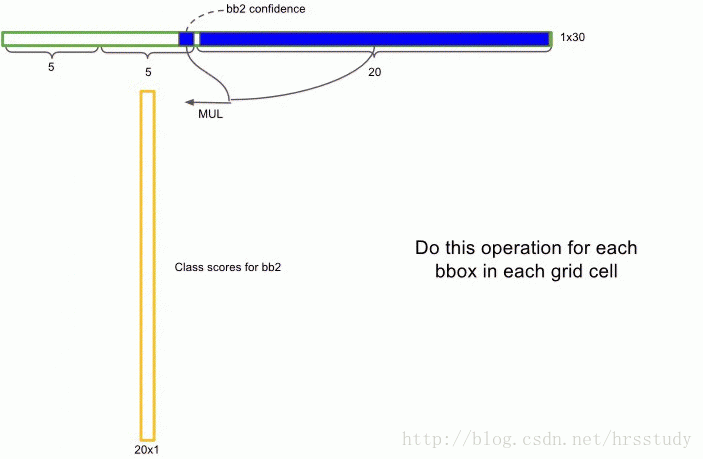
网络结构
网络结构如下图所示:

由24层的卷积层以及2层的全连接层构成,与GoogLeNet的网络结构类似。但没有使用GoogLeNet的inception modules,而是用1*1+3*3的卷积核的组合来代替。网络的最终输出时7*7*30个Tensor。
训练
yolo的训练分为两个部分,分别是物体分类识别训练和检测训练。就好像人的认知过程一样,首先要将一个物体放在眼前或者聚焦在某个物体上,先识别出这个物体的特征,能够认出这个物体。比如说,分辨水果。首先,要能够认出一个个水果的种类,比如先认出什么是苹果,什么是香蕉


在能够认出什么是苹果,什么是香蕉后,才能在果篮中找出香蕉和苹果,以及它们的位置。

yolo的训练过程也是如此,首先在ImageNet 1000-classcompetition dataset训练网络的前20层,外加一层average-pooling layer和一层fully connected layer。经过一个星期时间的训练。 在imageNet 2012上Top 5的训练精度达到88%。
完成分类网络的训练后,将训练好的模型去掉最后的 average-pooling layer和fully connected layer。然后加上原来的四层conv layer和fully connected layer。在psiacl voc2007上进行检测网络的训练,训练的图像尺寸也由224*224变为448*448。最终的输出结果包含类别概率和物体坐标信息(X,Y,W,H),对width和height进行归一化处理,使其值位于0-1之间(相对于整张图片尺寸的大小)。同时也将X和Y转换成相对于所在网格左上角的offset,这样X,Y也位于0-1之间。最后一层使用线性激活函数,其它层使用RLU激活函数:

损失函数
误差使用平方和的形式,因为这样更容易训练。但这样也存在一定的问题,首先是坐标误差和类别误差的权重不应该一样,坐标误差应更加得到重视。其次,许多网格中是不含有object物体中心的,也就是说,网格中拥有物体的置信度就是0。这样会使没有物体的网格相对于拥有物体的网格在数量上拥有压倒性的优势,这样可能会使模型不稳定,并在训练的初期的loss下降也会变慢。
为了解决这些问题,损失函数采用如下的形式:
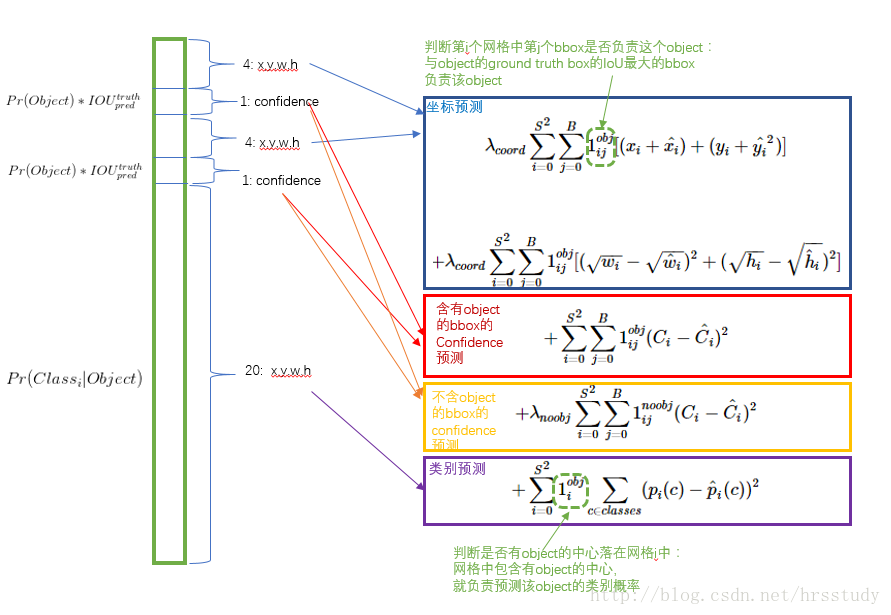
首先通过不同的权重来体系各项误差在总误差的重要性,λcoord代表坐标误差的权重,在训练过程中λcoord设置为5。同时为了削弱没有object网格的影响,将nobject的误差权重λnoobj设置为0.5。
对于不同大小的物体来说,预测的偏差对坐标误差的影响是不一样的。例如同样的预测偏差,对于大物体的影响要小于小物体。因此,在计算坐标误差的时候不是使用预测的width和height,而是使用它们的平方根,以削弱这一影响。
yolo的最终输出是一系列的bounding boxes,在训练时对于每一个物体,我们只希望有一个box来预测物体。因此我们在训练时选择用与 ground truth IOU值最高的那个box最预测。注意分类误差只在网格中有object时才有,没有object时就为0。坐标误差也只在IOU值最高的那个box里计算。同时对输出进行非极大值抑制处理,让每个object只输出IOU值最大的那一个。
在voc2007和voc2017的 training and validation data sets 总共训练了135个epochs,batch size为64。 momentum设置为 0.9 , decay 设置为0.0005
learning rate的设置如下:
第一个epoch,learing rate在0.001到0.01缓慢上升变化,如果一开始就用较大的learning rate会使梯度不稳定。接着用0.01的learning rate训练75个epochs,0.001的rate训练30个epochs,最后用0.0001训练30个epochs。
为了避免overfitting,在第一个全连接层使用了dropout,rate设置为0.5。同时还在原图像尺寸的基础上随机缩放20%的大小,在 HSV color space中调整图像的曝光度和饱和度,向量为1.5。
最后附上yolo tensorflow版实现的源码,
代码的原作者为hizhangp
代码作者提供了分类训练好的权重,我在实际训练过程中发现如果不使用代码作者提供的权重直接从头开始训练,并不能达到检测效果。就好像之前提的识别果篮中香蕉与苹果的问题,为了解决这些问题,题主也尝试了不少方法。在下一篇博文中将会提出训练的结果,以及如何解决自己训练分类权重的问题。