学习 Yolo v3 之前需要学习 v1,v2
Yolo v3 较 v1、v2 并没有太多的创新,主要是融合了其他的 trick,不过效果还可以;
主要改进有 3 点:
1. 主网络为 Darknet-53,借鉴了 resnet
2. 多尺度特征,大大提高了小物体的识别
3. softmax 多分类改为 多个二分类
Darknet-53
Darknet-53 借鉴了 resnet 的思路,网络结构也是作者自己设计,可更改

首先预训练该网络,网络采用 leaky relu 作为激活函数
多尺度特征
随着卷积层数的加深,特征越来越抽象,细粒度的特征损失更多,小物体的特征可能已经被忽略了,所以小物体的识别需要在细粒度特征上进行,也就是前面的卷积层;
Yolo v1 对于小物体的识别是非常差的,Yolo v2 采用 passthrough 保留细粒度特征,Yolo v3 采用 FPN 网络的思路输出多尺度特征,效果很好
FPN 网络
FPN 网络也叫特征金字塔,先从下往上融合特征,每层特征越来越抽象,分辨率越低,语义越强(细粒度的特征像一段话,抽象的特征就像对这段话的总结),
再从上往下,每层输出既融合了上层的强语义特征,又融合了下层的高分辨率信息;
输出多尺度特征;
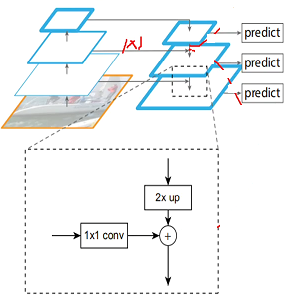
上图,从下往上可采用卷积,从上往下有个上采样的过程,可通过反卷积和插值实现;
从左往右有个 1x1 的卷积来改变 channels;
Yolo v3 网络结构
整体结构中展示了 FPN 的思想,如下图
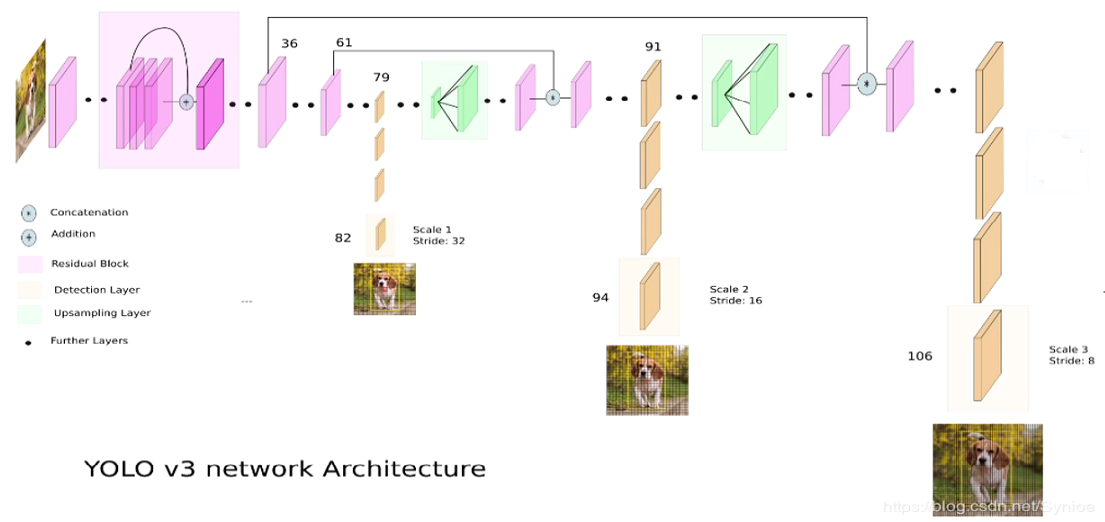
三路输出:
第一路:从 36 到 61到79层,再到 82 层,属于正常的卷积网络;
这一路输出相对于原始图像是 32 倍下采样,对于 416x416 图像来说,就是 13x13;
这一路适合检测尺寸较大的对象;
第二路:从 79 层开始做 上采样,反卷积或者插值,然后 和 61 层融合,然后做正常卷积,到 91 到 94 层;
这一路输出相对于原始图像是 16 倍下采样,对于 416x416 图像来说,就是 26x26;
这一路适合检测中等尺寸的对象;
第三路:从 91 层开始做上采样,反卷积或者插值,然后 和 36 层融合,然后做正常卷积,到 106 层;
这一路输出相对于原始图像是 8倍下采样,对于 416x416 图像来说,就是 52x52;
这一路适合检测尺寸较小的对象;
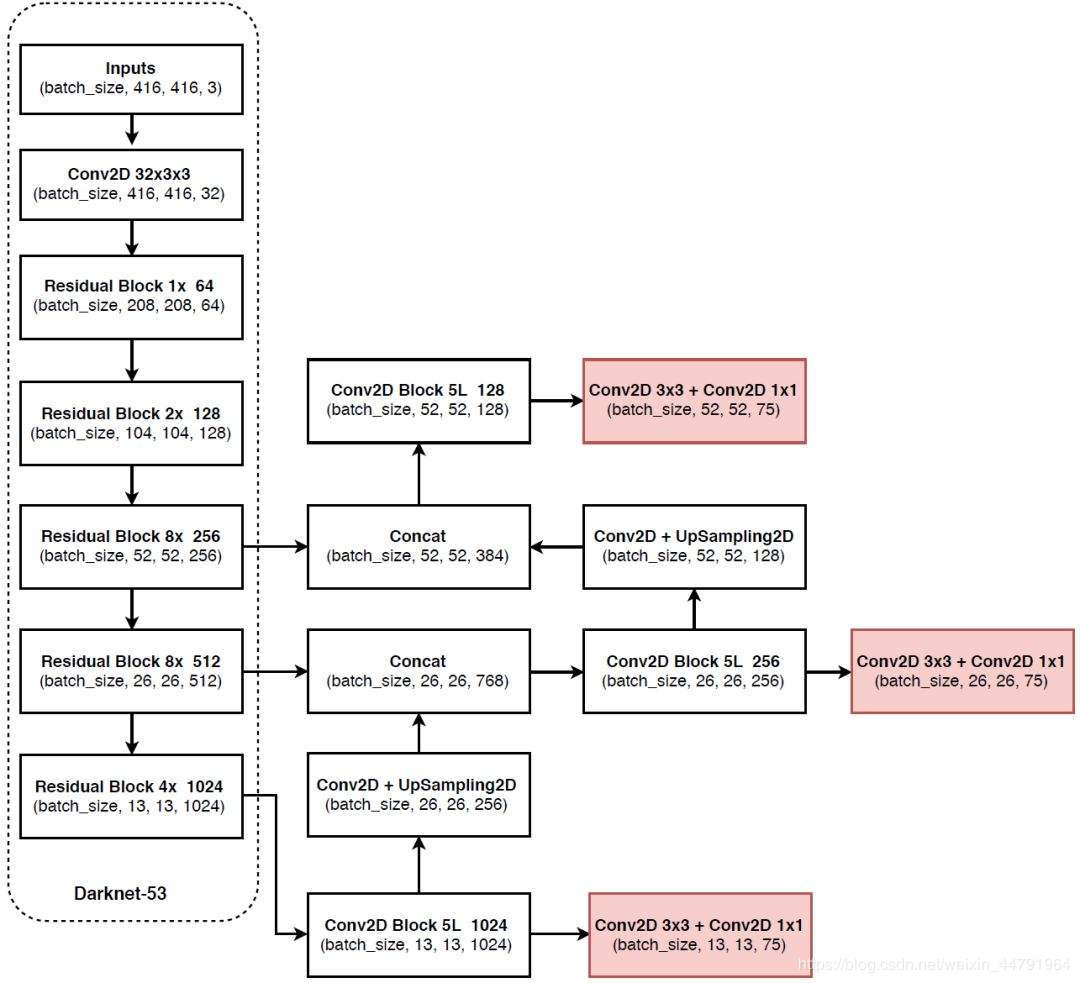
下面这张图也挺清晰的,多看几张图,有助于理解
网络输出

为什么每个 cell 3 个 anchor box,看下文;
模型输出 13x13x3 + 26x26x3 + 52x52x3 = 10647 个 先验框,比 Yolo v2 多得多,召回率更高,小物体检测效果好
每种尺度的输出对应不同的 anchor box
不同尺度的输出用于检测不同尺寸的物体,需要不同的 anchor box,
Yolo v3 采用 9 种不同尺度的 anchor box,每种输出对应 3 种,anchor box 尺寸的设定仍然采用 v2 中 kmeans 方法;
以 COCO 数据集为例,9 种 box 尺寸如下 9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)

特征图越小,anchor box 尺寸越大,检测目标也越大;
感受一下 每种尺度输出的 不同尺寸的 anchor box

Logistics 分类
对于目标检测来说,softmax 的问题在于一个物体只能有一个 label,但是实际上一个物体可能有多个标签,比如一个人可能有 Human 和 Man 两个标签,logistics 可以解决这个问题
模型效果
网上有各种比较,总之效果又快又好

参考资料:
https://zhuanlan.zhihu.com/p/49556105