PointNet [1] 是 3D 感知领域的开创性论文,将深度学习应用于点云进行对象分类和部分/场景语义分割。 原始论文已使用 TensorFlow 2.0 重现,可在https://github.com/luis-gonzales/pointnet_own上找到。
目录
数据输入

图 1:点云可视化
PointNet 将原始点云数据作为输入,这些数据通常是从激光雷达或雷达传感器收集的。 与 2D 像素阵列(图像)或 3D 体素阵列不同,点云具有非结构化表示,因为数据只是在激光雷达或雷达传感器扫描期间捕获的点的集合(更具体地说,一组)。 为了利用(2D 和 3D)卷积构建的现有技术,许多研究人员和从业人员经常通过将多视图投影到 2D 空间或将其量化为 3D 体素来离散点云。 鉴于原始数据被处理,这些方法都会产生负面影响。
结构
鉴于 PointNet 使用原始点云数据,因此有必要开发一种符合点集独特属性的架构。 其中,作者强调:
- 排列(顺序)不变性:鉴于点云数据的非结构化性质,由 N 个点组成的扫描有
个排列。后续的数据处理必须对不同的表示保持不变。
- 变换不变性:如果对象经历了某些变换,包括旋转和平移,则分类和分割输出应该保持不变。
- 点交互:相邻点之间通常带有有用的信息(即不应孤立地对待单个点)。 分类只需要利用全局特征,分割必须能够利用局部点特征和全局点特征。

图 2:PointNet 分类和分割网络 来源
该架构非常简单且非常直观。 分类网络使用共享的多层感知器 (MLP) 将 n 个点中的每一个从三个维度 (x, y, z) 映射到 64 个维度。 重要的是要注意,n 个点中的每一个都共享一个多层感知器(即,映射在 n 个点上是相同且独立的)。 重复此过程以将 n 个点从 64 维映射到 1024 维。 对于更高维嵌入空间中的点,最大池化用于在ℝ¹⁰²⁴中创建全局特征向量。 最后,使用三层全连接网络将全局特征向量映射到 k 个输出分类分数。 “输入变换”和“特征变换”的详细信息在下面的“变换不变性”部分进行了介绍。
对于分割网络,n 个输入点中的每一个都需要分配到 m 个分割类之一。 因为分割依赖于局部和全局特征,64 维嵌入空间中的点(局部点特征)与全局特征向量(全局点特征)连接,从而在ℝ¹⁰⁸⁸ 中产生每个点的向量。 与分类网络中使用的多层感知器类似,在 n 个点上使用 MLP(相同且独立地)将维数从 1088 降低到 128 再降低到 m,从而产生 n x m 的数组。
以下部分将详细说明最大池化和转换网络的动机/使用。
置换不变性
如前所述,点云本质上是非结构化数据,并表示为数值集。 具体来说,给定 N 个数据点,有 排列。
为了使 PointNet 对输入排列不变,作者采用对称函数,这些函数给定 n 个参数的值相同,而不管参数的顺序 [2]。 对于二元运算符,这也称为交换属性。 常见的例子包括:
- sum(a, b) = sum(b, a)
- average(a, b) = average(b, a)
- max(a, b) = max(b, a)
具体来说,一旦将 n 个输入点映射到更高维空间,作者就会使用对称函数,如下所示。 结果是一个全局特征向量,旨在捕获 n 个输入点的聚合标签。 自然地,全局特征向量的表现力与其维数有关(因此也与输入到对称函数的点的维数有关)。 全局特征向量直接用于分类,并与局部点特征一起用于分割。

图 3:最大池的使用,一个对称函数
PointNet 使用最大池化实现对称函数。 作者凭经验测试了其他方案,包括求和和求平均值,但发现它们较差,如下所示。

图 4:对称函数的实证检验
变换不变性
对象的分类(和分割)应该对某些几何变换(例如旋转)保持不变。 受空间变换器网络 (STN) [3] 的启发,“输入变换”和“特征变换”是模块化子网络,旨在为给定输入提供姿态归一化。
为了理解在 PointNet 中采用 STN,让我们尝试对它们的工作方式有一个更高层次的了解。 图 5 所示的是空间变换器 (ST) 的各种输入和相应的输出。 可以看出,ST 为其他旋转的输入提供姿势归一化。 在数字分类器中使用这种类型的姿势归一化将放宽下游算法的约束并减少需要数据增强的程度。 姿势归一化在点云的情况下也是有益的,因为对象可以类似地呈现无限数量的姿势。

图 5:空间变换器的各种输入和相应的输出
进一步看,图 6 显示了空间转换器的组件。 基于输入 U,一个小的回归网络,定位网络,输出变换参数 θ。 为了构造给定 U 和 θ 的输出 V,使用了网格生成器和采样器。 为了进一步激励网格生成器和采样器,假设定位网络的输出对应于将手写的“7”旋转一个角度 θ; 为了创建具有适当旋转的新图像,原始图像需要进行适当的采样。 请注意,ST 不限于输入空间,可以在任何下游特征/嵌入空间上运行。
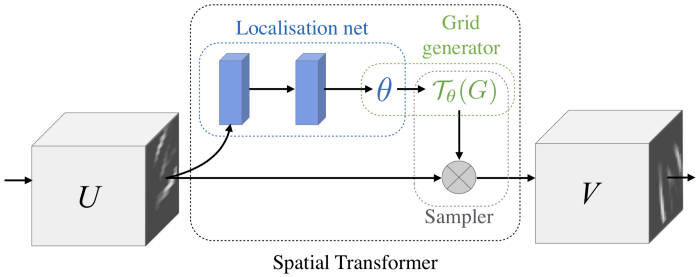
图 6:空间转换器的组件
回到 PointNet,可以采用类似的方法:对于给定的输入点云,应用适当的刚性或仿射变换来实现姿势归一化。 因为 n 个输入点中的每一个都表示为一个向量并独立地映射到嵌入空间,所以应用几何变换简单地相当于将每个点与变换矩阵相乘。 与基于图像的空间变换器应用不同,不需要采样。 图 7 显示了输入变换的快照。 与 ST 中的定位网络类似,T-Net 是一个回归网络,其任务是预测依赖于输入的 3×3 变换矩阵,然后将矩阵与 n×3 输入相乘。
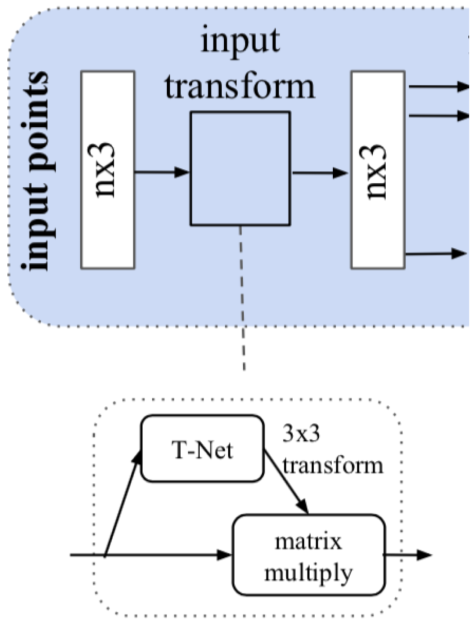
图 7:输入变换
包含 T-Net 的操作是由 PointNet 的更高级别架构驱动的。 MLP(或全连接层)用于将输入点独立且相同地映射到更高维空间; 最大池化用于对全局特征向量进行编码,然后使用 FC 层将其维度减少到ℝ²⁵⁶。 然后将最终 FC 层的输入相关特征与全局可训练的权重和偏差相结合,产生一个 3×3 的变换矩阵。
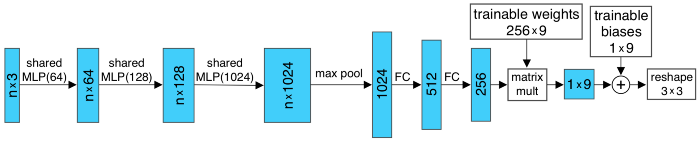
图 8:3x3 T-Net 的架构
姿态归一化的概念扩展到 64 维嵌入空间(图 2 中的“特征变换”)。 相应的 T-Net 与图 8 几乎相同,除了可训练权重和偏差的维度,它们分别变为 256×4096 和 4096,产生一个 64×64 的变换矩阵。 可训练参数数量的增加导致训练过程中可能出现过拟合和不稳定,因此在损失函数中添加了正则化项。 正则化项如下所示,并鼓励生成的 64×64 变换矩阵(在下面表示为 A)来近似正交变换。

分析和可视化
可以从全局特征向量中得出相当多的信息。 首先,如前所述,向量的维度(作者称为瓶颈维度bottleneck dimension并以 K 表示)与模型的表达能力直接相关。 自然地,较大的 K 值会导致模型更复杂——而且很可能是准确的——反之亦然。 作为参考,PointNet 设计为 K=1024。 图 9 显示了构成输入点云的 K 个点和多个点的 PointNet 精度。
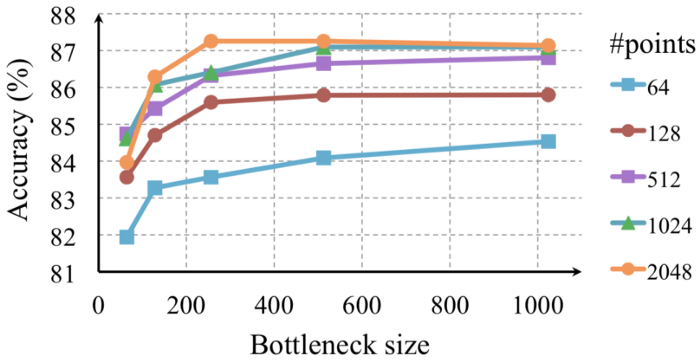
图 9:bottleneck size的准确度
另外,回想一下特征向量是经过深思熟虑应用的对称函数的结果(对于置换不变性)。 特别是,PointNet 使用了最大池化。 类似于使用 max 运算符将多个实值输入压缩为单个值,max pooling 的输出将输入点云的 n 个点压缩为点的子集。 事实上,至多 K 个点可以对全局特征向量做出贡献。 确实有助于并定义全局特征向量的点被称为关键点集,并使用一组稀疏的关键点对输入进行编码。

图 10:关键点集和上界形状的可视化
类似于 max 算子的输出如何被小于真实最大值的输入改变,输入点存在一个不会影响全局特征向量的界限。 这个界限由上面的上界形状表示。 请注意,超出上限形状的噪声会改变全局特征向量,但不一定会导致错误分类。 总之,对于临界点集和上界形状之间的点,全局特征向量是不变的,从而产生了相当大的鲁棒性。
最后,上述稳健性可以以更量化的方式可视化,如下所示。 缺失数据是指从输入点云中删除点,而异常值是指插入随机/噪声点。

图 11:PointNet 鲁棒性测试
参考
[1] C. Qi et al, “PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation”, 2017
[2] Symmetric function, Wikipedia
[3] M. Jaderberg et al, “Spatial Transformer Networks”, 2015