今天要聊的论文是斯坦福大学Charles等人在CVPR2017上发表的论文,提出了一种直接处理点云的深度学习网络——PointNet。这篇论文具有里程碑意义,标志着点云处理进入一个新的阶段。为什么会给这么高的评价呢?
因为在PointNet之前,点云没办法直接处理,因为点云是三维的、无序的,别说深度神经网络了,就是普通算法很多都不能奏效。于是人们想出来各种办法,比如把点云拍扁成图片(MVCNN),比如把点云划分成体素(类似游戏“我的世界”里的场景),再比如把点云划分成节点然后按顺序拉直(O-CNN)等等。总之,点云先要被处理成“非点云”。
这些想法怎么样呢?其实也挺不错的,也能取得不错的结果。比如MVCNN的有些指标就不输PointNet。
这时候我们就会觉得,冥冥中一定会有一种网络出现,摆脱上面这些操作。于是,PointNet出现了,从此点云处理领域分成“前PointNet时代”和“后PointNet时代”。接着,各种直接处理点云的网络也纷纷出现,如PointCNN、SO-Net,效果也是越来越好。
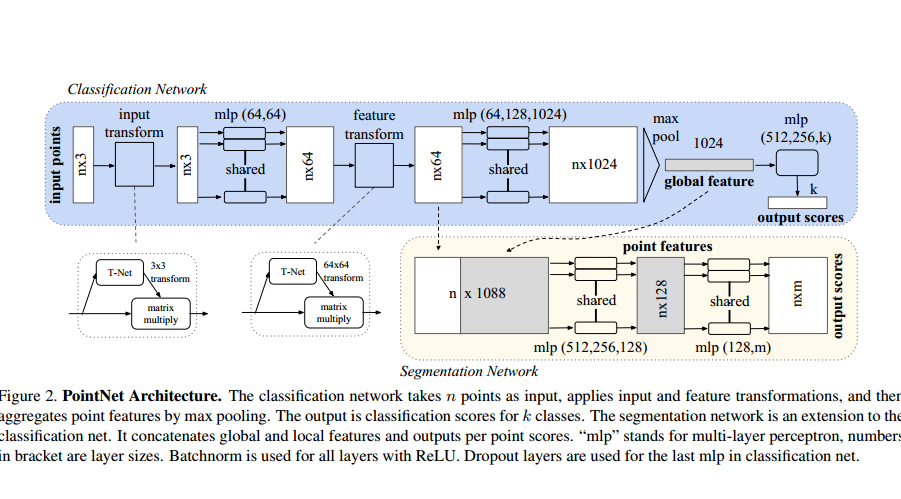
下面进入正题,看看PointNet有哪些创新点。
1、针对点云无序性——采用Maxpooling作为对称函数。最大池化操作就是对所有成员进行比较,把最大的留下来,其余舍弃掉,所以,不管顺序如何变化,最大值是不会改变的。
对称函数是什么意思?例如加法就是对称函数,1+2+3+4=10,换个顺序,2+4+3+1=10,不管顺序如何变化,对结果不会产生影响。
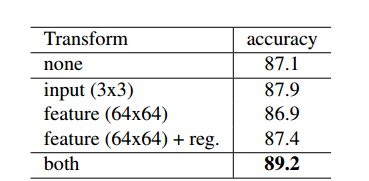
2、针对刚体变化——对齐网络T-net。T-net对性能的提升作用也还是有的,两个T-net加上regularization 贡献了2.1个百分点,但奇怪的是在PointNet++的代码中,已经看不到T-net了(这一点论文没有提及,github上也有人提问,但是作者没有回复)。
3、特征提取阶段采用MLP(多层感知机,说白了就是全连接层),这种结构用到的运算只有乘法和加法,都是对称函数,所以不会受到排序影响。
实验效果
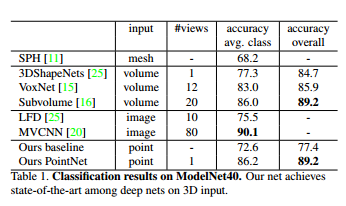
1、分类
数据集是ModelNet40,包含40类物体的CAD,通过采样获得点云。这里作者没有把MVCNN列出来,因为精度没有比过它,不过后来的改进版已经超过了。
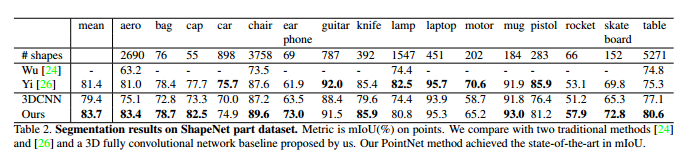
2、物体分割:
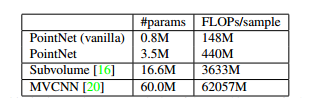
3、参数量与MVCNN的对比:明显占优。
PointNet与PointCNN从文章到代码都有很多相似之处,两者对比看待,或许更有助于我们理解。
众所周知,PointNet中使用了maxpooling和T-net,作者文章中起到关键作用的是maxpooling,而T-net对性能的提升作用也还是有的(两个T-net加上regularization 贡献了2.1个百分点),但奇怪的是在PointNet++的代码中,已经看不到T-net了(这一点论文没有提及,github上也有人提问,但是作者没有回复)。
但是,与之相似的PointCNN中有个X变换矩阵,但X变换对于PointCNN的作用可就非常重要了,因为它连maxpooling都没有用。下面我们就对两者进行比较。
首先是PointNet中的T-net代码:
- def feature_transform_net(inputs, is_training, bn_decay=None, K=64):
- """ Feature Transform Net, input is BxNx1xK
- Return:
- Transformation matrix of size KxK """
- batch_size = inputs.get_shape()[0].value
- num_point = inputs.get_shape()[1].value
- net = tf_util.conv2d(inputs, 64, [1,1],
- padding='VALID', stride=[1,1],
- bn=True, is_training=is_training,
- scope='tconv1', bn_decay=bn_decay)
- net = tf_util.conv2d(net, 128, [1,1],
- padding='VALID', stride=[1,1],
- bn=True, is_training=is_training,
- scope='tconv2', bn_decay=bn_decay)
- net = tf_util.conv2d(net, 1024, [1,1],
- padding='VALID', stride=[1,1],
- bn=True, is_training=is_training,
- scope='tconv3', bn_decay=bn_decay)
- net = tf_util.max_pool2d(net, [num_point,1],#池化窗口是[num_point,1]
- padding='VALID', scope='tmaxpool')
- net = tf.reshape(net, [batch_size, -1])#变成两维
- net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
- scope='tfc1', bn_decay=bn_decay)
- net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
- scope='tfc2', bn_decay=bn_decay)
- with tf.variable_scope('transform_feat') as sc:
- weights = tf.get_variable('weights', [256, K*K],
- initializer=tf.constant_initializer(0.0),
- dtype=tf.float32)
- biases = tf.get_variable('biases', [K*K],
- initializer=tf.constant_initializer(0.0),
- dtype=tf.float32)
- biases += tf.constant(np.eye(K).flatten(), dtype=tf.float32)
- transform = tf.matmul(net, weights)
- transform = tf.nn.bias_add(transform, biases)
- transform = tf.reshape(transform, [batch_size, K, K])
- return transform
接下来看PointCNN的X变换:
- ######################## X-transformation #########################
- X_0 = pf.conv2d(nn_pts_local_bn, K * K, tag + 'X_0', is_training, (1, K), with_bn=False)
- #kernal size(1, K, 3), kernal num=K*K, so the output size is (N, P, 1, K*K). so this operator is in the neighbor point dimentional.
- X_1 = pf.dense(X_0, K * K, tag + 'X_1', is_training, with_bn=False)#in the center point dimensional ,P decrease to 1.
- X_2 = pf.dense(X_1, K * K, tag + 'X_2', is_training, with_bn=False, activation=None)#(N, P, 1, K*K)
- X = tf.reshape(X_2, (N, P, K, K), name=tag + 'X')
- fts_X = tf.matmul(X, nn_fts_input, name=tag + 'fts_X')
- ###################################################################
从体量和复杂程度上来看,后者胜出。
从作用效果来看,不太好评价。因为PointCNN是有局部特征的,这点和pointnet++思想一致。所以即便PointCNN性能超过了PointNet,也不能直接证明X-transporm就一定优于T-net了。
代码方面,其实T-net的前四层和X变换的第一层做的事情差不多,都是为了把多个点的特征融合到一组特征,为训练变换矩阵提供素材。但接下来就不同了,T-net只有一组K*K的weights权值,而PointCNN后面跟了两个dense层,维度都是K*K的,参数更多,因此猜测PointCNN训练变换矩阵应该会更加充分。后期可以通过实验验证以下。
最后歪个楼,我在测试PointNet++的代码时,ModelNet40的分类结果一直徘徊在90.1左右,达不到论文里提的90.7,跟作者邮件联系也没有得到很好的答案。所以我再想是不是作者本来的PointNet++代码里是有T-net的,但是放到github里的版本没加上。但这只是猜测,有待验证。
附上相关代码的链接:
PointNet2:https://github.com/charlesq34/pointnet2