PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation(点云分割)
有其他博主提到:
目前看,在KITTI三维目标检测中,F-PointNet排名第一。
这篇文章是2017年CVPR上的,讲的是根据点云信息直接进行三维的分类与分割。
从效果上看,居然比陈晓智的MV3D还要好,真的不可思议。
pointnet 官方使用了 tensorflow 实现,代码写的相当工整易读,而这个方法在代码中实现起来也比论文中看起来更简单。其主要分成以下三部分:数据处理 TF图谱构建 开始学习
转载自:https://www.meteorshub.com/machine-learning/2017/12/188/
结构
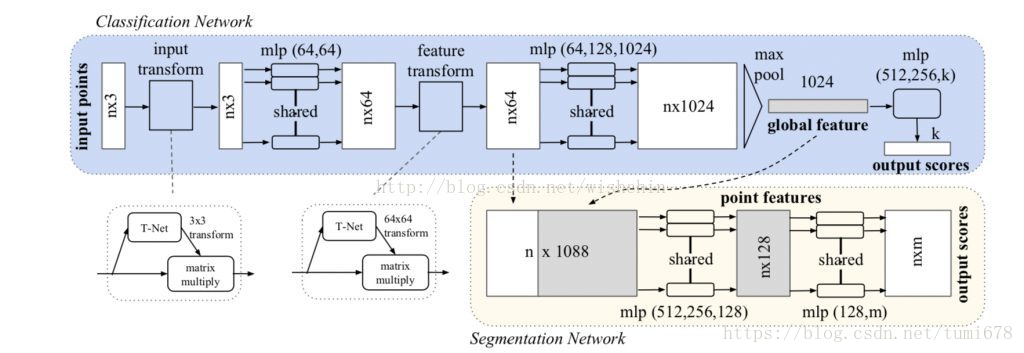
网络输入n*3的数据,n就是采样点的个数,3表示三维坐标。经过几步mlp(多层感知器)获得n*1024维的采样点特征,然后使用max pooling进行对称操作得到1024维的整体特征(global feature)。其中在分类模型(Classification)中直接经过几层降维输出softmax分类概率,而分割模型(Segmentation)中要将整体特征串接到采样点特征之后再进行多层网络输出。
在网络中间有两个T-net网络,用于对模型进行旋转不变性处理,T-net生成3*3的旋转矩阵对模型进行操作。分别用于旋转模型坐标和模型中间特征
介绍
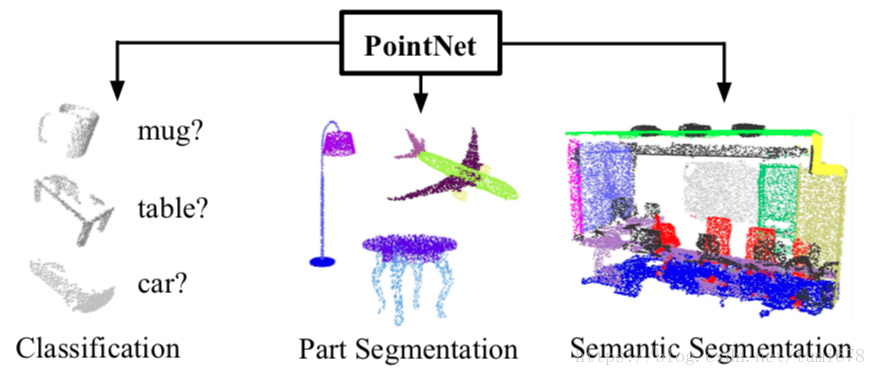
PointNet 是斯垣福大学在2016年提出的一种点云分类/分割深度学习框架。众所周知,点云在分类或分割时存在空间关系不规则的特点,因此不能直接将已有的图像分类分割框架套用到点云上,也因此在点云领域产生了许多基于将点云体素化(格网化)的深度学习框架,取得了很好的效果。但是将点云体素化势必会改变点云数据的原始特征,造成不必要的数据损失,并且额外增加了工作量,而 PointNet 采用了原始点云的输入方式,最大限度地保留了点云的空间特征,并在最终的测试中取得了很好的效果。
这篇论文已经被CVPR2017收录。PointNet就是针对点云数据格式的三维网络,点云数据就是摄像机采到物体表面的一些采样点并获取到其三维坐标。不难理解,现实中的立体相机很多都是无法将全部的三维点采集起来的,只能得到一些采样点的信息,Apple的iphone X也是使用了深度相机,发射一些红外射线来提取面部的点云信息。因此点云数据的应用领域很广。
点云数据具有一些显著的特点——数据点无序性、数据点数量可变性等,无序就表示网络必须能够在改变数据点顺序的情况下输出相同的结果,数量可变就表示网络必须能够处理不同采样点的三维模型。
文章中pointnet主要应用于两种问题——分类(classification)问题和分割(segmentation)问题。分类问题就是判断三维模型属于哪一类,如汽车、桌子、书等。分割问题就是判断每一个采样点属于物体的那一部分或属于哪一个物体,例如一个人的四肢和躯干,或者路上的人还是车。
对称设计
文中提到该网络是通过使用MaxPooling作为对称函数设计来处理点云模型的无序性的,也就是说无论输入的顺序是怎样的,maxpooling都会输出相同的结果。对称函数就是类似自然数加法那样的操作,调换输入顺序输出不变。
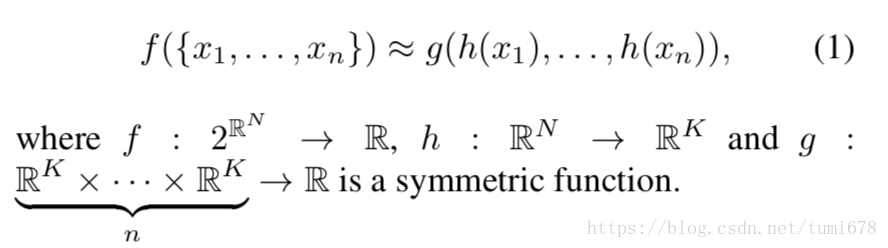
卷积神经网络已经在图像领域取得了惊人的成果,经过了AlexNet、VGG、GoogleNet/Inception各个版本、ResNet的演进,性能越来越强,并且出现了MobileNet、ShuffleNet等一些应用于特定场景的“定制化”网络和类似空洞卷积、DepthWise卷积等巧妙的结构。可以说图像领域,卷积神经网络可以说是“近乎圆满”了。
但是推广到三维领域,卷积网络似乎发挥得没那么完美了。不难理解,在多了一个维度后,网络的体积成倍增长,如果直接将卷积核变成三维不论是计算量还是存储量都不是现有GPU能够承受的。虽然现阶段三维领域都是用一些tricky的方法提取特征,但总有一天硬件性能足够强大时直接对三维物体提取三维特征,就像平面卷积神经网络一样。
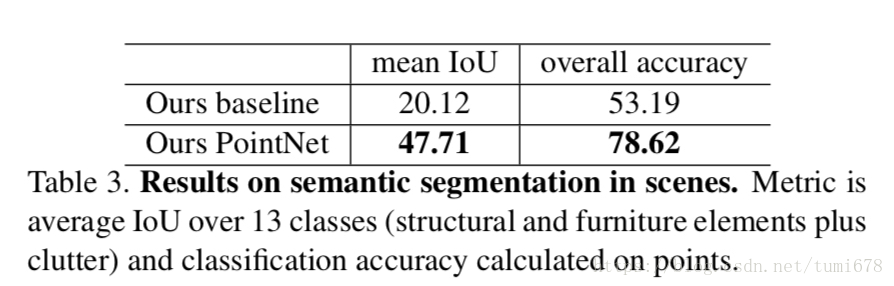
结果
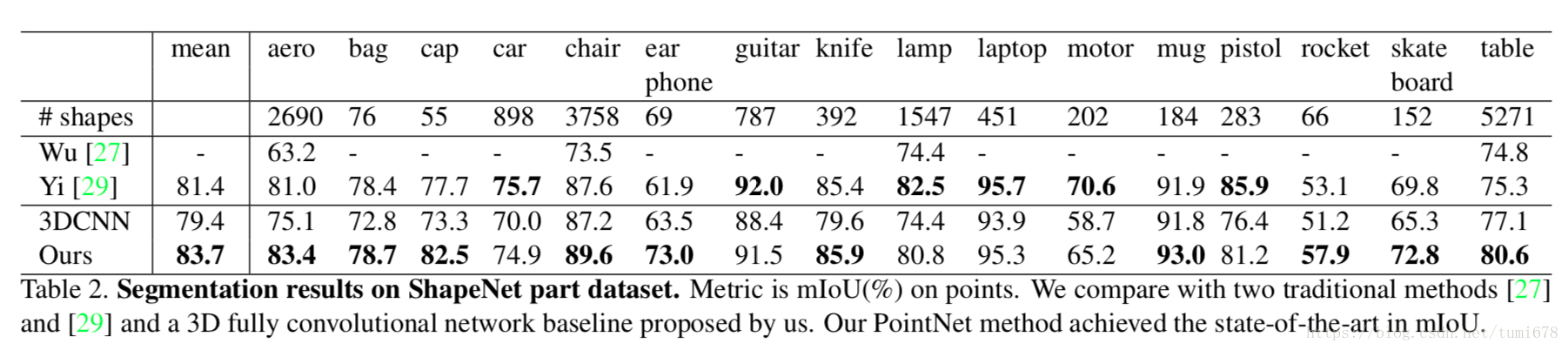
简单的想法,结果很优秀
不足
很容易想到的一点就是Pointnet的大部分或说几乎全部的处理都是针对单个采样点的,无论提多么精细的feature都是针对某一个采样点的,而整合所有采样点特征的网络只有那个maxpooling,没错,甚至连可训练的变量都没有,只有一个maxpool。因此,网络对模型局部信息的提取能力远不如卷积神经网络来的那么solid。
作者也提出了改进版本Pointnet++,就针对局部信息缺失的问题作了改进,而且思想跟卷积神经网络类似,非常值得一读。