目前二维深度学习取得了很大的进步并且应用范围越来越广,随着三维设备的发展,三维深度学习得到了很大的关注。
最近接触了三维深度学习方面的研究,从pointnet入手,对此有了一点点了解希望记录下来并分享,若有误希望指正~持续更新
以下所有的解读基于点云分类。
一、三维深度学习简介
二、点云存在的问题
三、pointnet网络结构详解
四、pointnet代码详解
一、三维深度学习简介
- 多视角(multi-view):通过多视角二维图片组合为三维物体,此方法将传统CNN应用于多张二维视角的图片,特征被view pooling procedure聚合起来形成三维物体;
- 体素(volumetric):通过将物体表现为空间中的体素进行类似于二维的三维卷积(例如,卷积核大小为5x5x5),是规律化的并且易于类比二维的,但同时因为多了一个维度出来,时间和空间复杂度都非常高,目前已经不是主流的方法了;
- 点云(point clouds):直接将三维点云抛入网络进行训练,数据量小。主要任务有分类、分割以及大场景下语义分割;
- 非欧式(manifold,graph):在流形或图的结构上进行卷积,三维点云可以表现为mesh结构,可以通过点对之间临接关系表现为图的结构。流形表达比较抽象,用到拉普拉斯特征什么的,我也不太懂……

二、点云存在的问题
- 无序性:点云本质上是一长串点(nx3矩阵,其中n是点数)。在几何上,点的顺序不影响它在空间中对整体形状的表示,例如,相同的点云可以由两个完全不同的矩阵表示。 如下图左边所示:
我们希望得到的效果如下图右边:N代表点云个数,D代表每个点的特征维度。不论点云顺序怎样,希望得到相同的特征提取结果。


我们知道,网络的一般结构是:提特征-特征映射-特征图压缩(降维)-全连接。
下图中x代表点云中某个点,h代表特征提取层,g叫做对称方法,r代表更高维特征提取,最后接一个softmax分类。g可以是maxpooling或sumpooling,也就是说,最后的D维特征对每一维都选取N个点中对应的最大特征值或特征值总和,这样就可以通过g来解决无序性问题。pointnet采用了max-pooling策略。

2.旋转性:相同的点云在空间中经过一定的刚性变化(旋转或平移),坐标发生变化,如下图所示:
我们希望不论点云在怎样的坐标系下呈现,网络都能正确的识别出。这个问题可以通过STN(spacial transform netw)来解决。二维的变换方法可以参考这里,三维不太一样的是点云是一个不规则的结构(无序,无网格),不需要重采样的过程。pointnet通过学习一个矩阵来达到对目标最有效的变换。

三、pointnet网络结构详解
先来看网络的两个亮点:
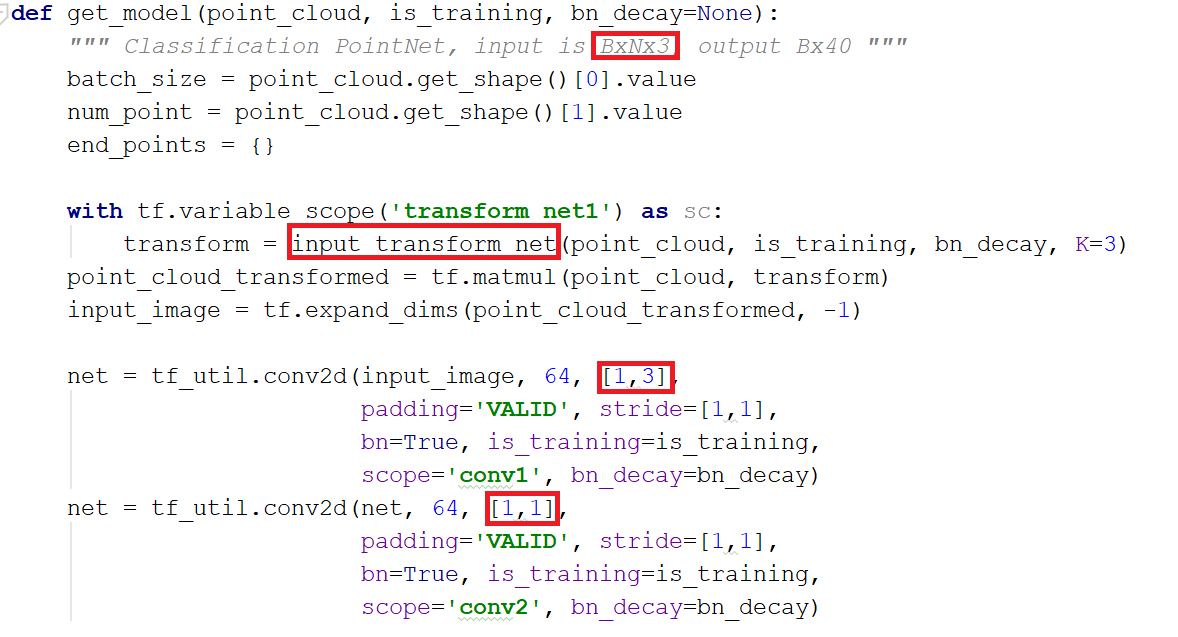
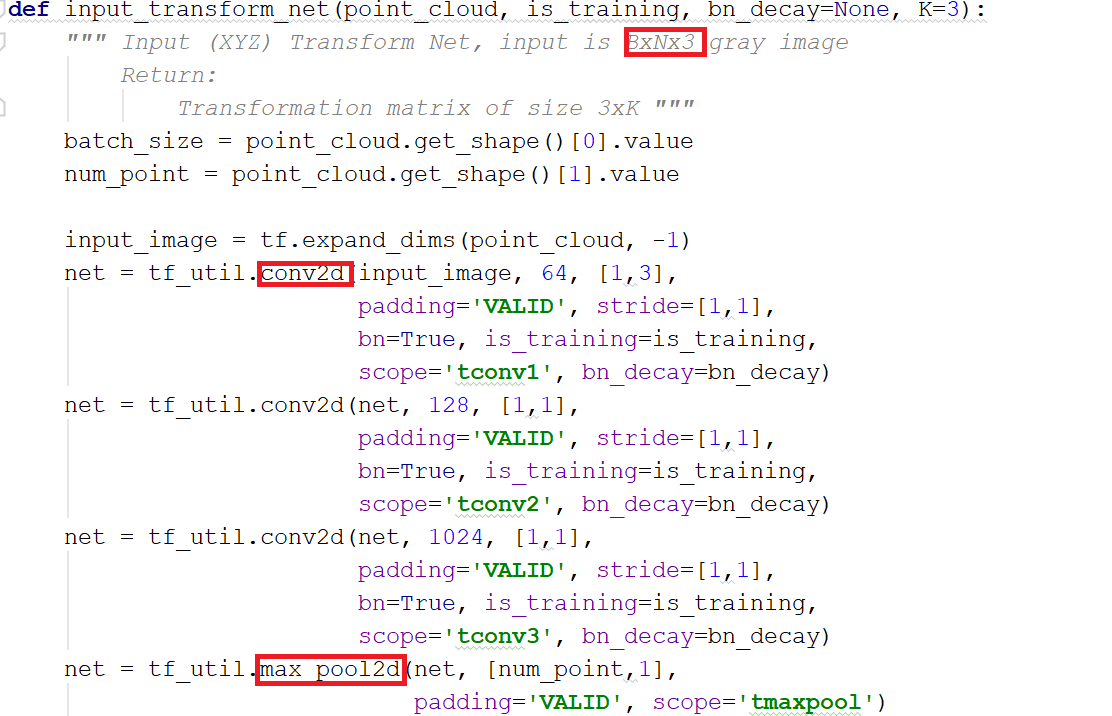
- 空间变换网络解决旋转问题:三维的STN可以通过学习点云本身的位姿信息学习到一个最有利于网络进行分类或分割的DxD旋转矩阵(D代表特征维度,pointnet中D采用3和64)。至于其中的原理,我的理解是,通过控制最后的loss来对变换矩阵进行调整,pointnet并不关心最后真正做了什么变换,只要有利于最后的结果都可以。pointnet采用了两次STN,第一次input transform是对空间中点云进行调整,直观上理解是旋转出一个更有利于分类或分割的角度,比如把物体转到正面;第二次feature transform是对提取出的64维特征进行对齐,即在特征层面对点云进行变换。
- maxpooling解决无序性问题:网络对每个点进行了一定程度的特征提取之后,maxpooling可以对点云的整体提取出global feature。
再来看网络结构:
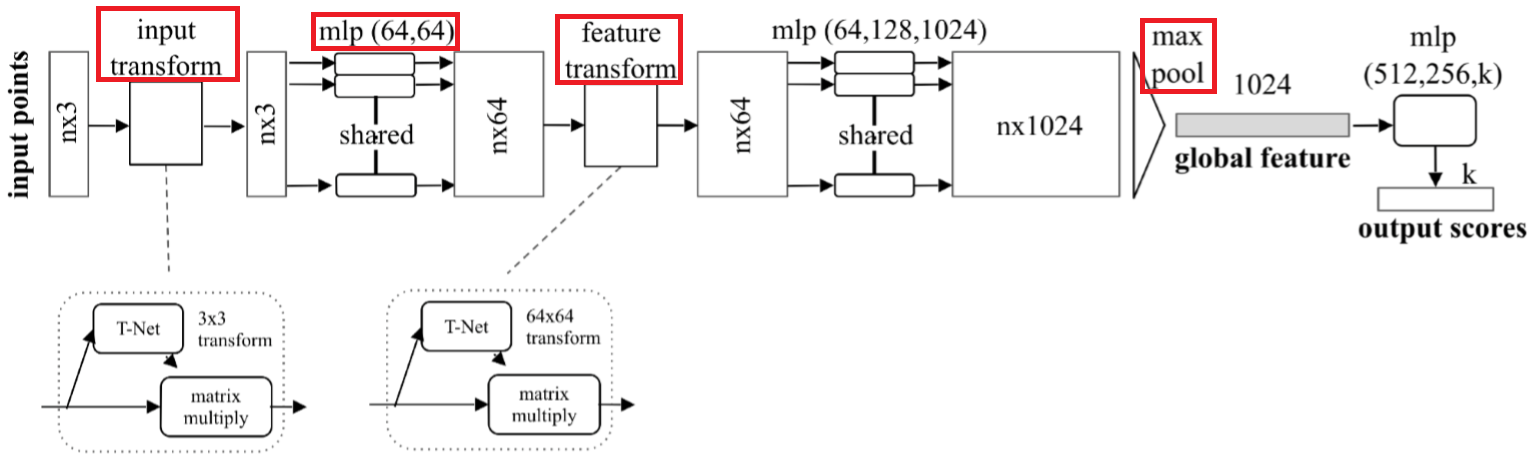
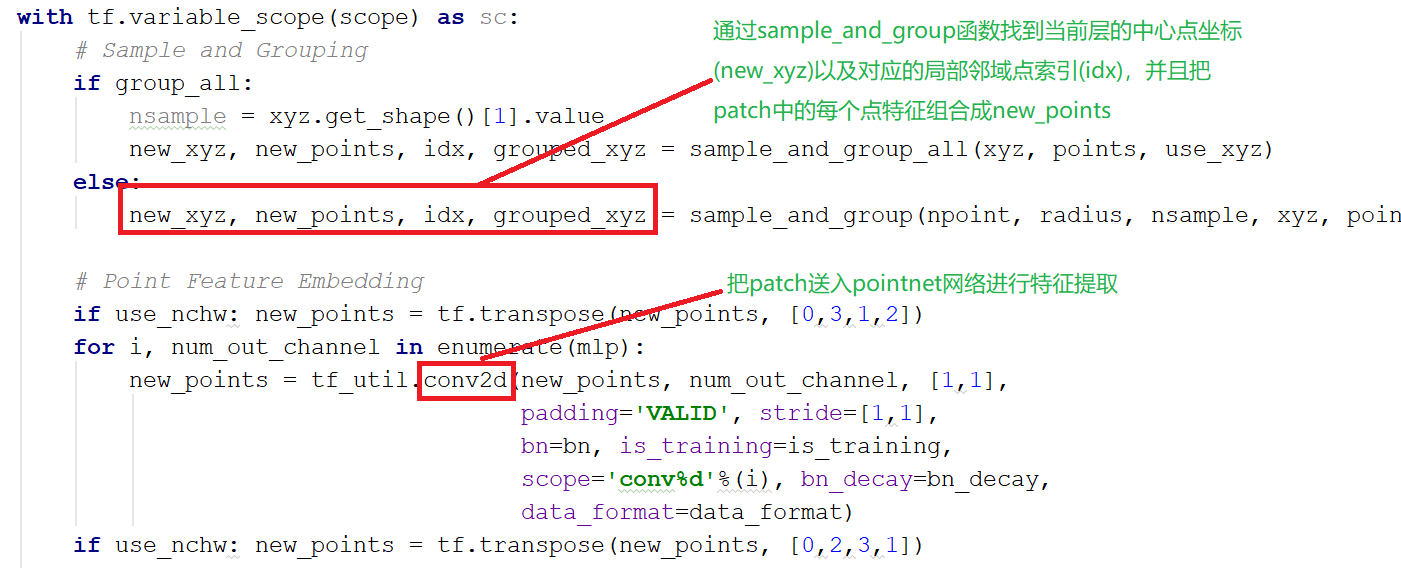
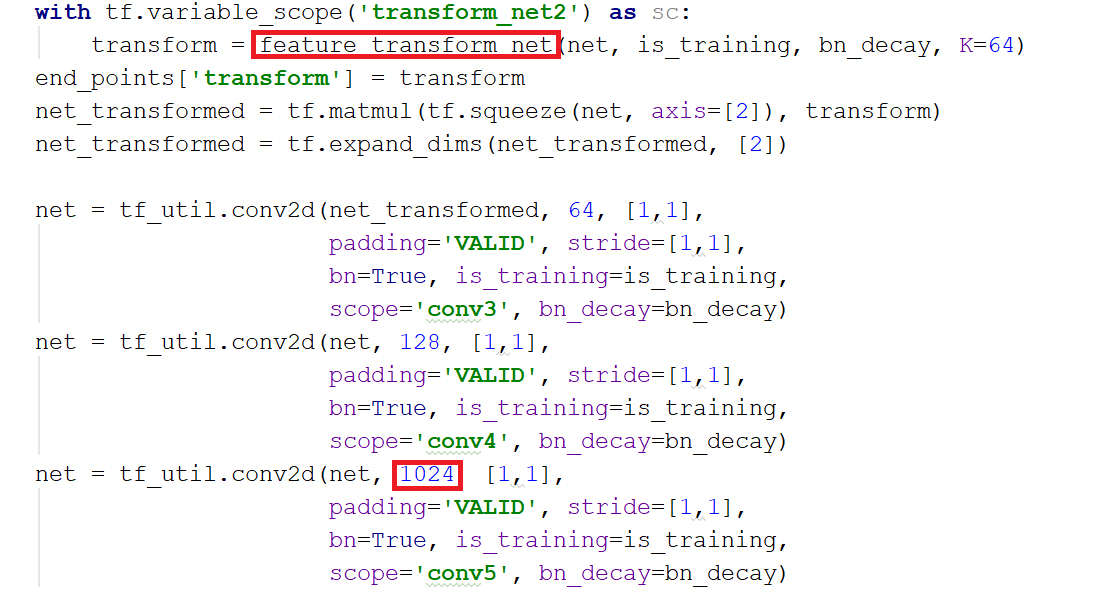
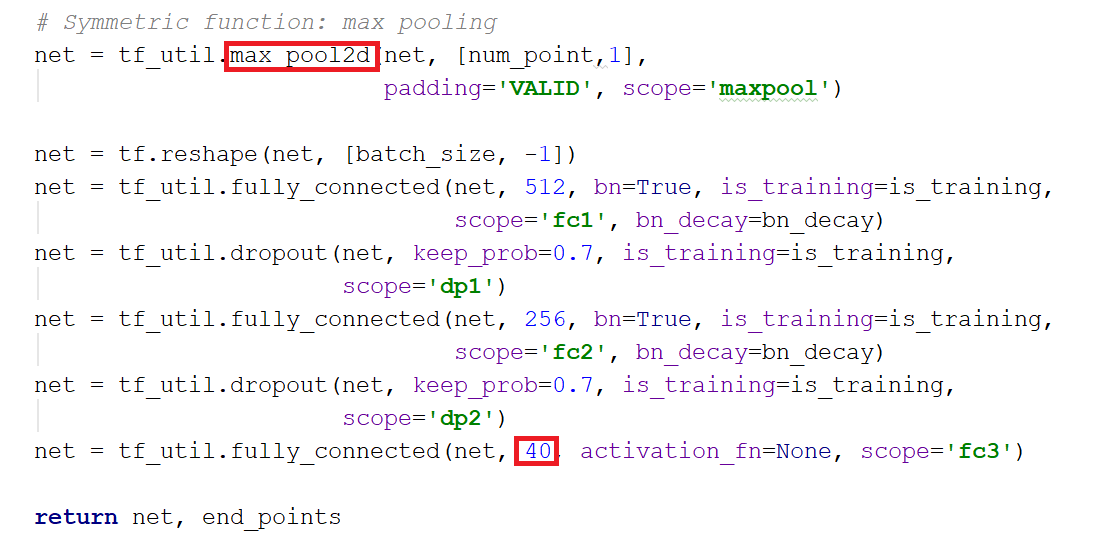
其中,mlp是通过共享权重的卷积实现的,第一层卷积核大小是1x3(因为每个点的维度是xyz),之后的每一层卷积核大小都是1x1。即特征提取层只是把每个点连接起来而已。经过两个空间变换网络和两个mlp之后,对每一个点提取1024维特征,经过maxpool变成1x1024的全局特征。再经过一个mlp(代码中运用全连接)得到k个score。分类网络最后接的loss是softmax。
四、pointnet代码详解
好像也没有特别需要讲的……重点我都框出来了
网络模型部分
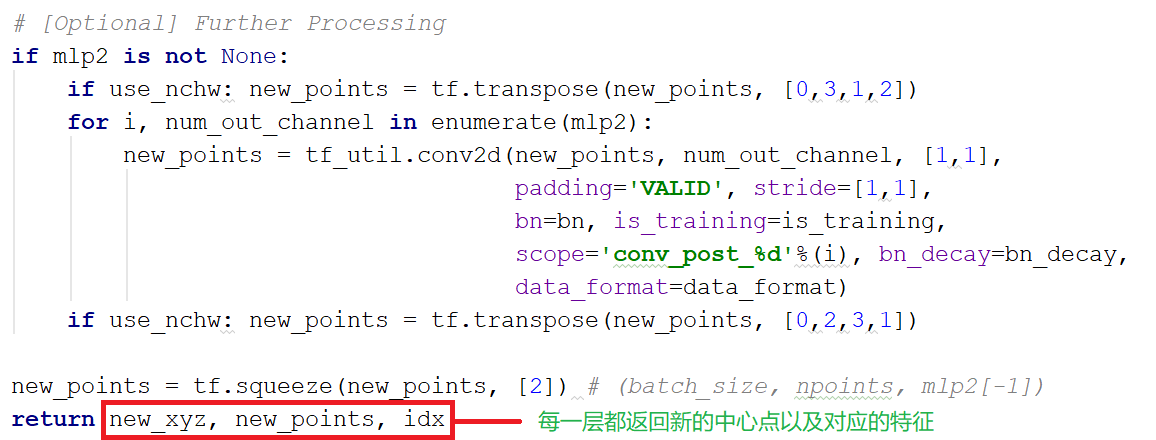
变换矩阵部分,以第一个STN为例

上一篇(pointnet网络)主要引入了三维深度学习相关的一些背景知识,并介绍了pointnet整体思想和框架,那这一篇来介绍出自同一团队的基于pointnet改进的pointnet++。同样,以下所有的解读基于点云分类。
一、pointnet存在的问题
二、pointnet++网络结构详解
三、pointnet++代码详解
一、pointnet存在的问题
pointnet只是简单的将所有点连接起来,只考虑了全局特征,但丢失了每个点的局部信息,如下图(以点云分割为例):

所以继pointnet之后,很多人的着重点都在提取局部区域特征方面。为了解决这个问题,pointnet++的整体思想就是:首先选取一些比较重要的点作为每一个局部区域的中心点,然后在这些中心点的周围选取k个近邻点(欧式距离的近邻)。再将k个近邻点作为一个局部点云采用pointnet网络来提取特征。
二、pointnet++网络结构详解
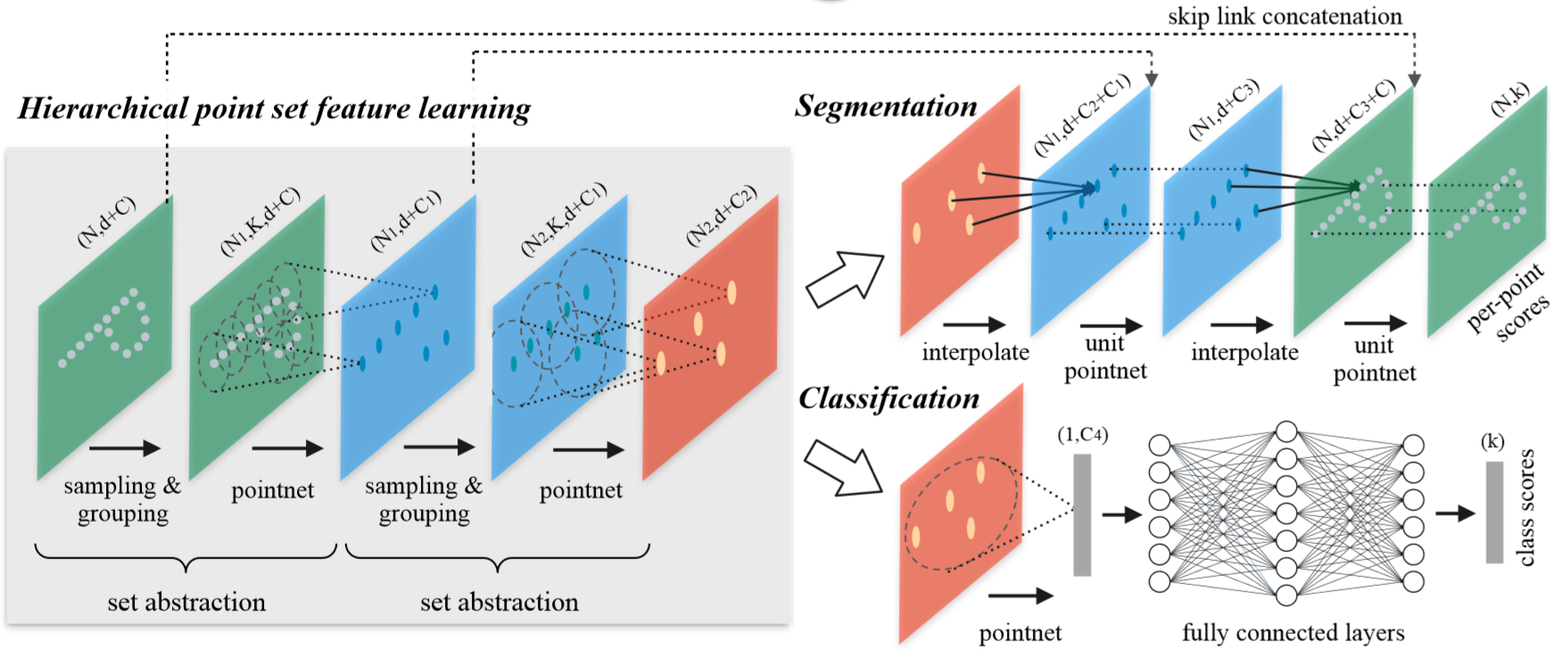
网络的两个亮点:
1.改进特征提取方法:pointnet++使用了分层抽取特征的思想,把每一次叫做set abstraction。分为三部分:采样层、分组层、特征提取层。首先来看采样层,为了从稠密的点云中抽取出一些相对较为重要的中心点,采用FPS(farthest point sampling)最远点采样法,这些点并不一定具有语义信息。当然也可以随机采样;然后是分组层,在上一层提取出的中心点的某个范围内寻找最近个k近邻点组成patch;特征提取层是将这k个点通过小型pointnet网络进行卷积和pooling得到的特征作为此中心点的特征,再送入下一个分层继续。这样每一层得到的中心点都是上一层中心点的子集,并且随着层数加深,中心点的个数越来越少,但是每一个中心点包含的信息越来越多。
2.解决点云密度不同问题:由于采集时会出现采样密度不均的问题,所以通过固定范围选取的固定个数的近邻点是不合适的。pointnet++提出了两个解决方案。
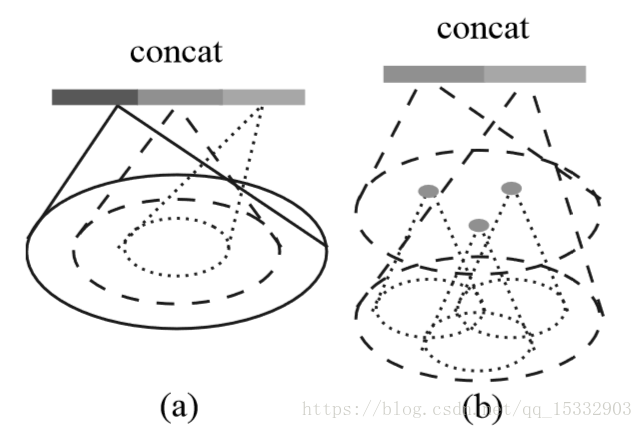
方案一:多尺度分组
如上图左所示,比较直观的思想是,在每一个分组层都通过多个尺度来确定每一个中心点的邻域范围,并经过pointnet提取特征之后将多个特征联合起来,得到一个多尺度的新特征。
方案二:多分辨率分组
很明显,通过上述做法,对于每一个中心点都需要多个patch的选取与卷积,计算开销很大,所以pointnet++提出了多分辨率分组法解决这个问题。如上图右所示,类似的,新特征通过两部分连接起来。左边特征向量是通过一个set abstraction后得到的,右边特征向量是直接对当前patch中所有点进行pointnet卷积得到。并且,当点云密度不均时,可以通过判断当前patch的密度对左右两个特征向量给予不同权重。例如,当patch中密度很小,左边向量得到的信息就没有对所有patch中点提取的特征可信度更高,于是将右特征向量的权重提高。以此达到减少计算量的同时解决密度问题。
三、pointnet++代码详解
整体网络结构:
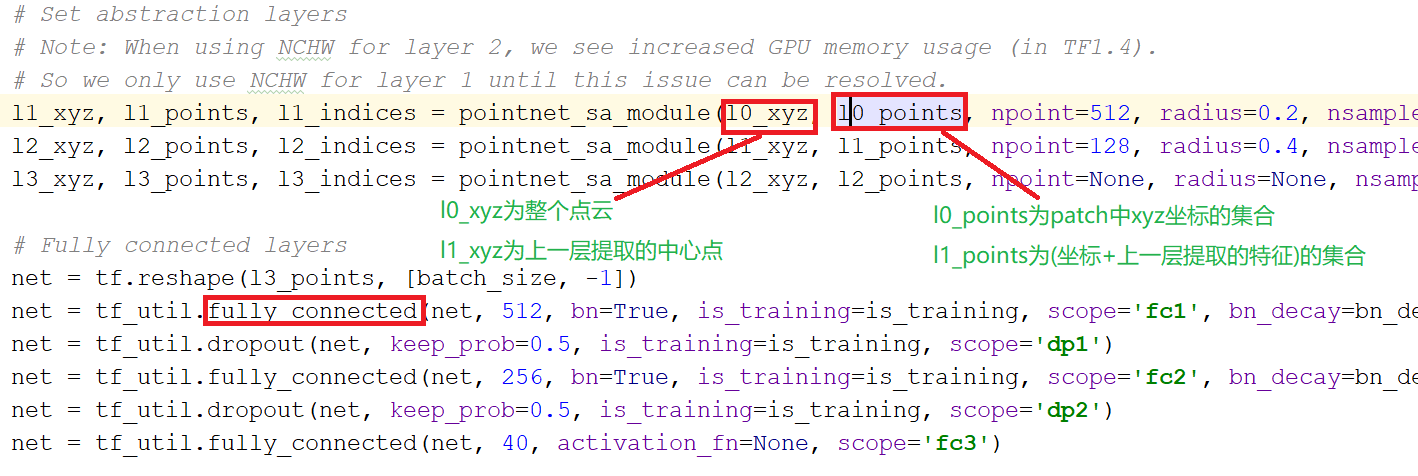
特征提取pointnet_sa_module: