PointNet++

《PointNet++:Deep Hierarchical Feature Learning on Point Sets in a Metric Space》
PointNet++是继PointNet之后的又一篇Point-base的点云数据分割、分类网络。
1引文
点云是由一组无序的点组成的数据形式,其在空间中点的位置是确定的,空间中每一个点之间会进行交互,在其局部邻域内构成物体信息。PointNet作为Point-base方法的开山之作,直接对无序的点云输入进行处理,基本思想是通过网络学习每个店的空间编码,通过对称函数将所有单独的点的特征汇集到一个全局的特征空间。PointNet的方法足够简单也足够高效,但仍然存在一些问题。比如,PointNet并没有对点云做一个多尺度的特征处理,缺少了局部和全局的信息互补。从CNN 2D分割的发展来看,从FCN到UNET还是fast-RCNN到MaskRCNN,多分辨率的层次结构能够提升模型感受野,提升对大物体和小物体的分割效果。
有了这个问题,PointNet++提出了新的解决方法,在PointNet的基础上,引入分层的网络结构,以分层的方式处理空间中采样的点。
PointNet++的总体思路很简单。
- 首先通过底层空间的距离度量将点集划分为重叠的局部区域;
- 与CNN类似,先从小的邻域中提取捕捉精细几何结构的局部特征;
- 这种局部特征被进一步分组为更大的单元并被处理以产生更高层次的特征;
- 这个过程不断重复,直到得到整个点集的特征。
从上述思路中,我们可以发现两个需要解决的问题:
- 如何来划分区域,或者说根据什么方法来划分这种区域?
- 如何从划分好的区域中提取特征?
首先,由于PointNet的方法已经被证明具有很好的特征提取能力,且能够适应点云数据的无序性,因此,可以使用PointNet来提取局部点云特征。
如何生成这些重叠的点集区域是需要解决的问题。在PointNet++中,作者选择了最远点采样(FPS)算法来解决这个问题。不同于CNN中通过固定步幅对图像进行卷积采样,在点云数据中需要考虑不同点云位置点云密度存在变化,需要采样算法能够适应这种密度变化。
1.1 FPS算法
FPS算法流程:
- 随机选择一个初始点 P 0 P_0 P0(可以随机选择,也可以选择距离点云重心的最远点),作为初始点集P={ P 0 P_0 P0}
- 选取合适的距离度量(如欧氏距离),计算所有点 P i P_i Pi到点 P 0 P_0 P0的距离,距离数组为D={ d 01 , d 02 . . . , d 0 i d_{01},d_{02}...,d_{0i} d01,d02...,d0i},选取离 P 0 P_0 P0点最远距离的点 P 1 P_1 P1。构成点集P={ P 0 P_0 P0, P 1 P_1 P1}。
- 再计算所有点到 P 1 P_1 P1的距离,如果点 P i P_i Pi到 P 1 P_1 P1距离 d 1 i ′ d^{'}_{1i} d1i′小于 d 0 i d_{0i} d0i,则距离数组中 d 0 i d_{0i} d0i更新为 d 1 i ′ d^{'}_{1i} d1i′。
- 选取距离数组D中的最大值对应的点作为 P 2 P_2 P2,更新点集P={ P 0 P_0 P0, P 1 P_1 P1, P 2 P_2 P2}。
- 重复2-4步,直到采样N个点为止。
第1、2步很好理解,就是采样两个距离最远的点。第3步,通过计算未采样点到点集P中的距离,选择最小距离存储,也就是距离数组D中存储的是离各个采样点的最近距离。接着第4步从D中选择最远的点,相当于确保了这个点离所有采样点“平均意义上”最远。
2 PointNet++

2.1 层次化点集特征学习
PointNet++构建了一个分层的网络结构,用于从点集中抽象出不同层次大小的点集特征。一个set abstraction由3部分组成,分别为采样(sampling)、分组(grouping)、特征提取(PointNet)。sampling层从输入点集中提取一组点,而grouping层则是根据这组点来寻找邻近的点构成局部区域点集,将这组点集输入到PointNet中进行特征提取。相当于从大的输入点集中获取迷你点集,再使用PointNet来特征提取。
sampling层:选择的算法为FPS算法。与随机采样相比,FPS对点集的覆盖更加全面,能够获得更好的感受野,同时这种算法还和数据的分布相关,采样更加科学。
Grouping层:输入为(N, d+C),即N个点,d+C个特征(比如XYZRGB 6个特征,这里d表示XYZ坐标信息),在这组点中,经过sampling获取一组点的坐标(N’, d)作为形心。grouping层在每一个形心点周围取K个近邻点,形成一个点集,那么N’个点即可形成N’个点集,总的点集即为(N’, K, d+C)。
这里,K的取值并不是固定的。可以使用k近邻(KNN)搜索来查询固定数量的邻接点,也可以查询每个点的在某个半径范围内的所有点,也可以称为球查询。这里作者使用球查询来确定点集,球查询可以保证区域内尺度不变,使局部区域特征在整个空间中更具有通用性,对语义分割的task更为友好。
PointNet层:输入为N’个局部点集构成的点集(N’, K, d+C),PointNet负责将每一个局部点集抽象成一个点的特征,即 ( N ′ , K , d + C ) → ( N ′ , d + C ′ ) (N', K, d+C)→(N', d+C') (N′,K,d+C)→(N′,d+C′)。
这里有一个细节是,对于每一个局部点集,其坐标都会事先进行转换,转换为相对点集形心的相对坐标。 x i ( j ) = x i ( j ) − x ˉ ( j ) x_i^{(j)}=x_i^{(j)} - \bar{x}^{(j)} xi(j)=xi(j)−xˉ(j),这里 x ˉ \bar{x} xˉ为这个局部点集的形心。使用这种相对坐标的形式可以捕获局部点集中点与点之间的对应关系。
2.2 Multi-scale grouping (MSG)
由于点云的数据在不同位置可能会有不同的点密度,这种不规范的输入形式要求模型拥有足够强的鲁棒性,来适应不同密度点集的输入。尤其是,当输入的是稀疏点云时,模型需要识别细粒度的局部结构。
最理想的情况下,如果模型能够对点云中的每一个点都进行特征处理,记录点的信息,捕获每一个细节部位的信息,那模型就能适应任何密度的点云输入。但是,受限于现实条件理想情况并不可能存在。
那我们就需要一种能够适应不同密度的模型,当输入的采用密度变化时,模型需要能够组合来自不同尺度区域的特征。这就是Grouping层需要完成的任务,也就是多尺度的特征汇聚。
这里Grouping的算法同样有两种,一种为 Multi-scale grouping (MSG),另一种则是Multi-resolution grouping (MRG)

获取多尺度特征的一个简单方法就是使用具有不同尺度的分组层,来提取每一个尺度的特征,最后将这些特征连接起来,图(a)。换个思路,只要我们生成不同尺度的点集,使用grouping层去提取特征,那么特征自然就是不同尺度的。在这里,作者通过random input dropout的方法来随机删去输入点集中的一些点,来模型不同密度的点集输入。这些输入再通过grouping层即可获得不同尺度的特征。
2.3 Multi-resolution grouping (MRG)
由于MSG方法需要对每一个点集进行random input dropout,时间复杂度较高。这里作者提出了MRG的方法,图(b),对比MSG效率更高。
MRG很好理解,先从输入点集中进行set abstraction,获得一些抽象点和点的特征,再从这些点中进行特征提取,获得高层次的点集特征。同时,还需要对输入点集进行特征提取,提取低层次的点云特征。再将两者合并起来,相当于同时提取了多个尺度的特征。
这里,不同层次获得的特征具有不同的特性。当局部密度较低时,低层次的特征明显比高层次特征更为可靠,因为计算高层次特征时,点经过采用后,点集更为稀疏,易受缺陷点的影响。而在局部密度较高的时候,效果则相反。
2.4 segmentation path
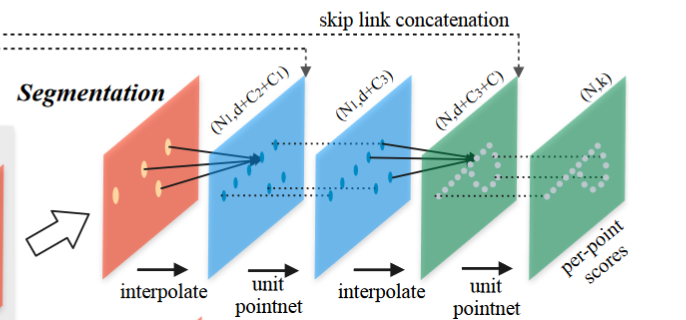
点云分割需要获得每个点的原始特征,这里作者同过插值(interpolate)和跳跃连接(skip link concatenation)来完成(类似2D分割中的Unet)。
对于插值算法,作者使用基于k最近邻的反距离加权平均值。然后将 N 1 N_1 N1 点上的插值特征与跳跃链接点特征连接起来。再通过unit pointnet来对特征进行处理和传递,更新点的特征向量。
3 总结
PointNet++在PointNet的基础上更新了多尺度的特征处理操作。提出了两种set abstraction策略,能够根据不同点云密度智能地聚合多尺度特征,对点云密度的输入具有更强的鲁棒性。