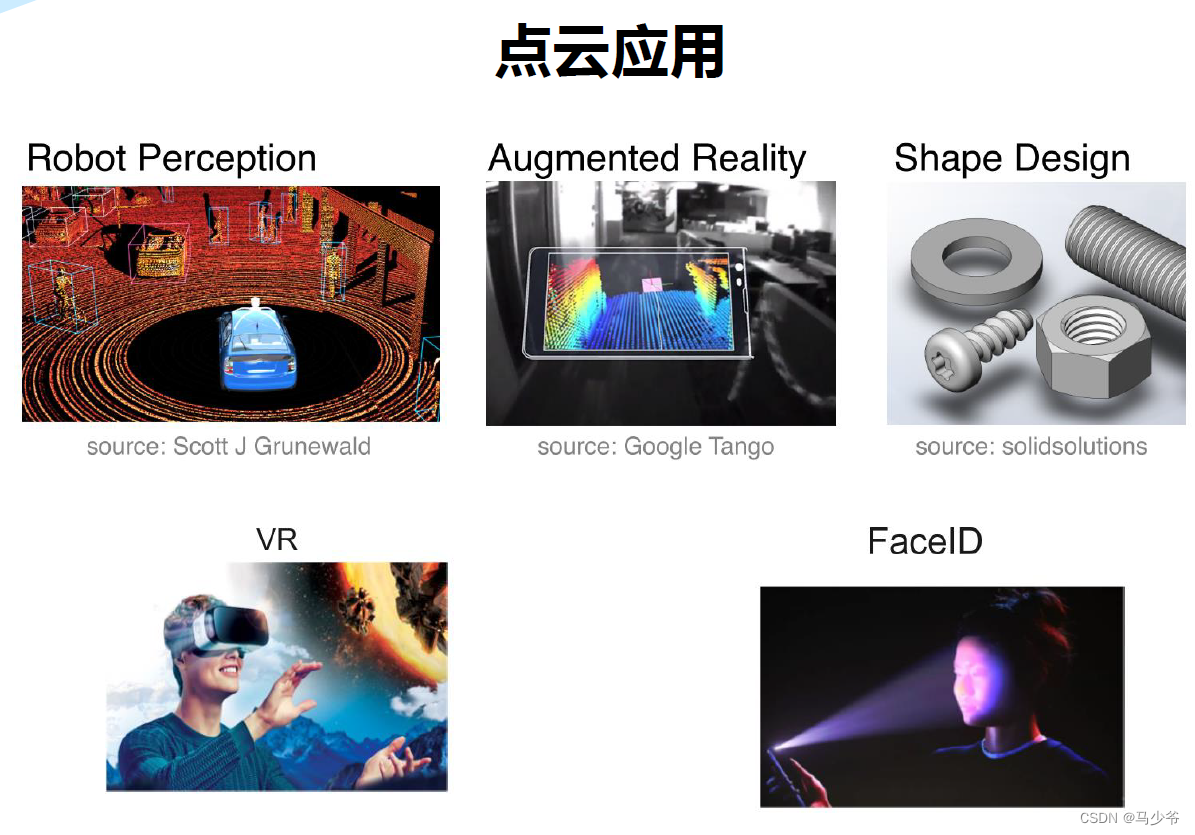
一、点云的应用



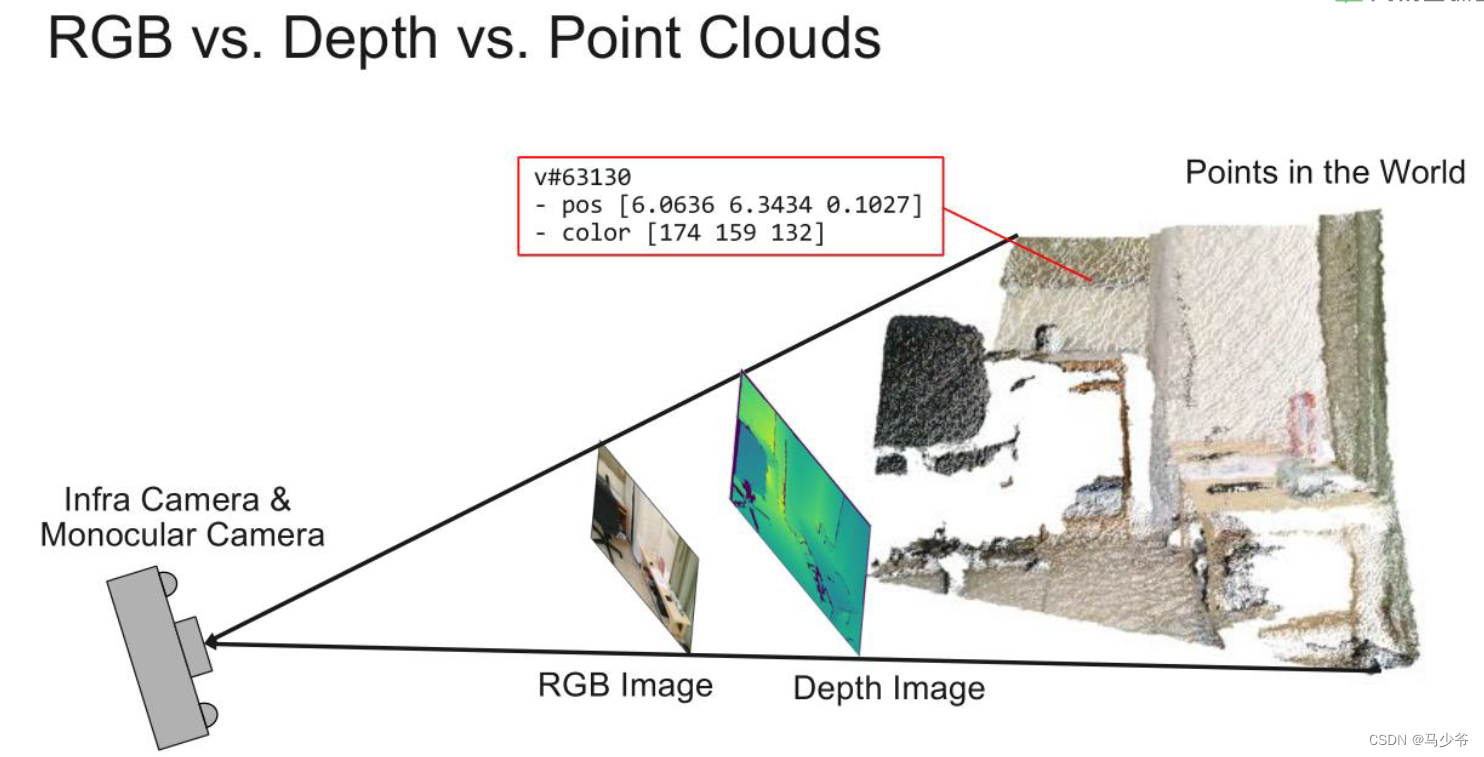
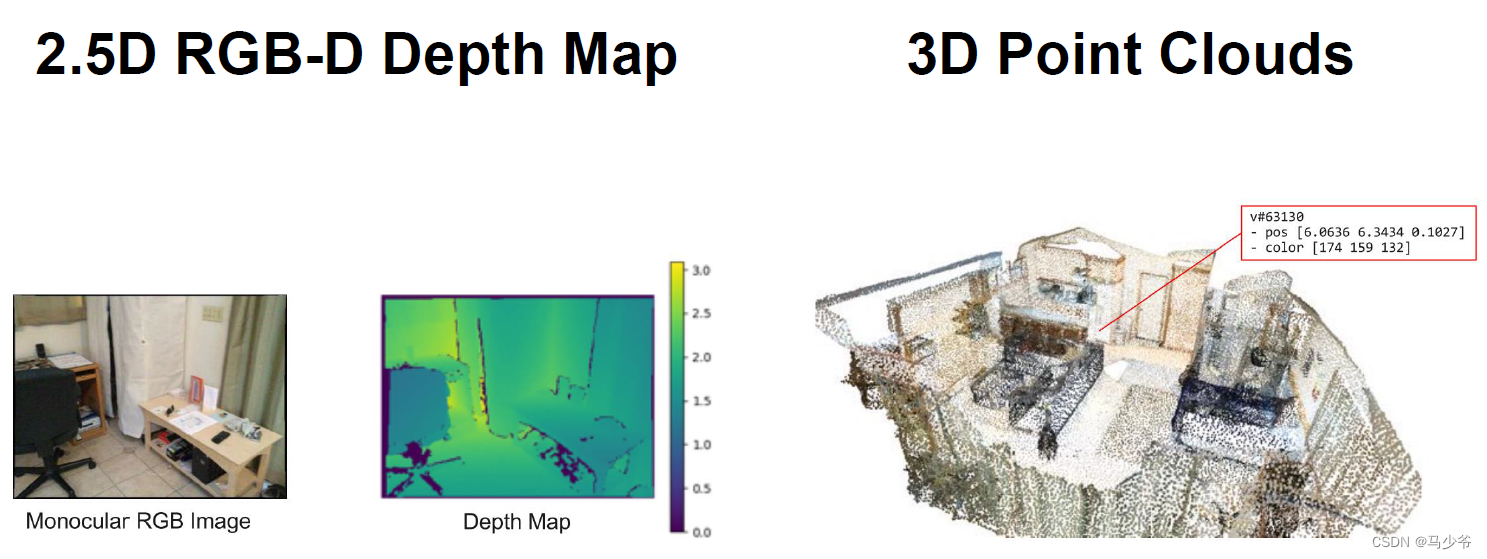
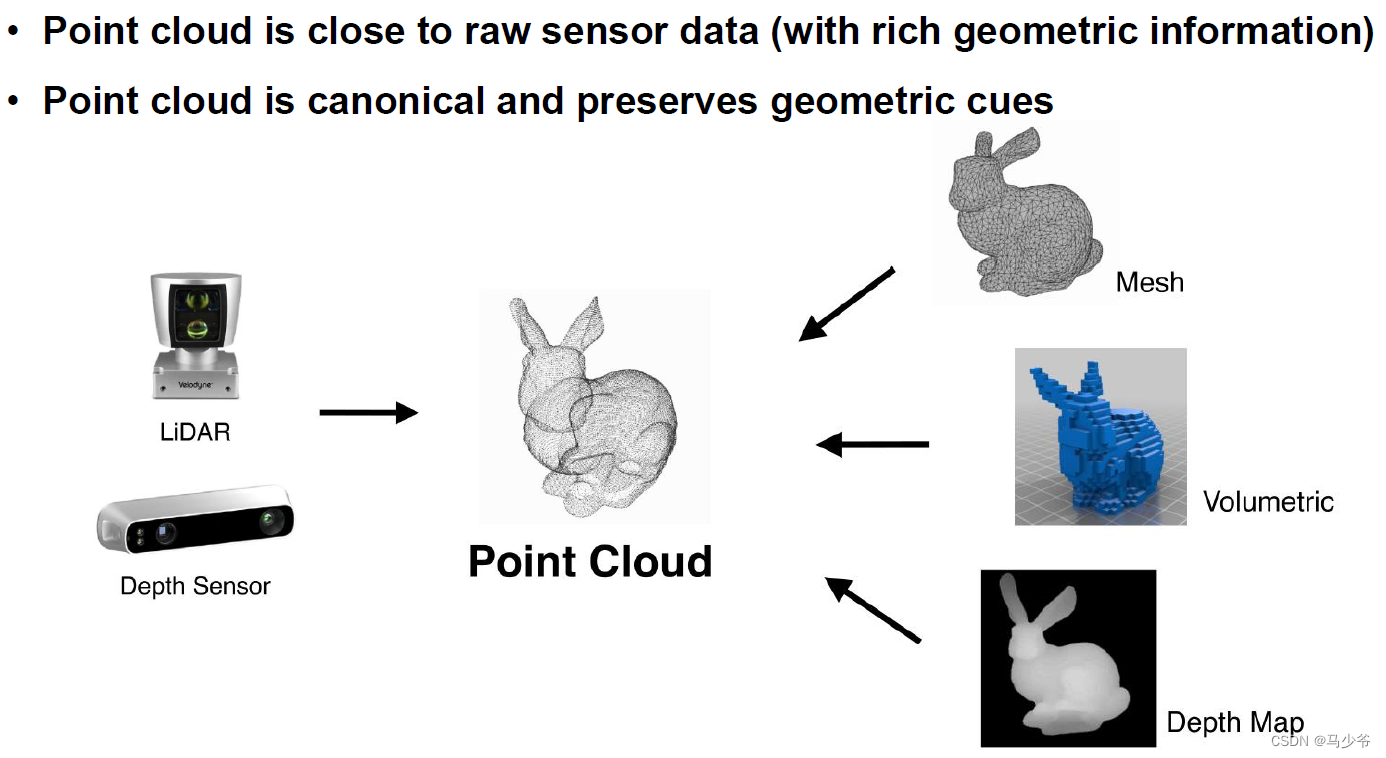
二、点云的表述




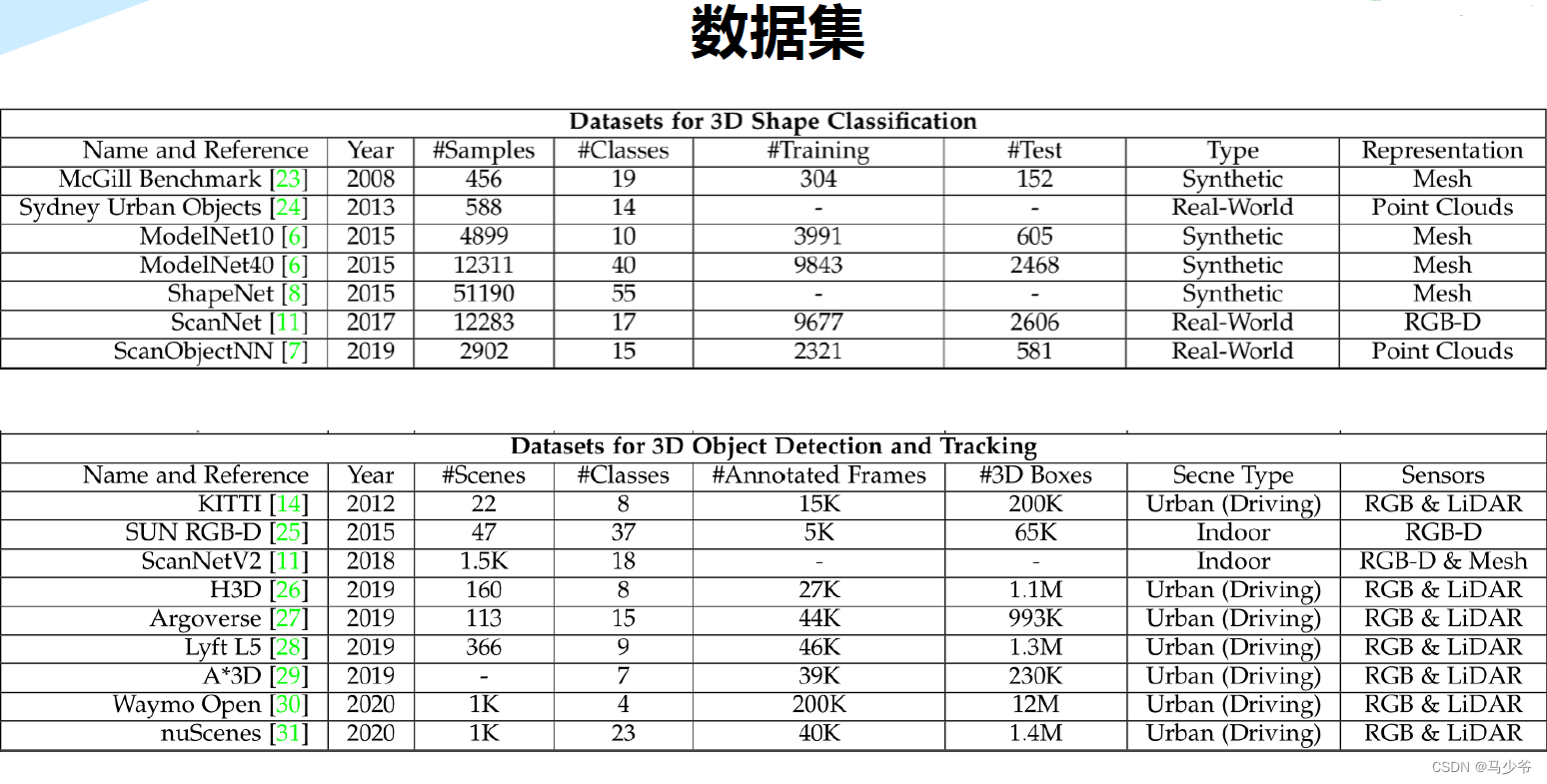
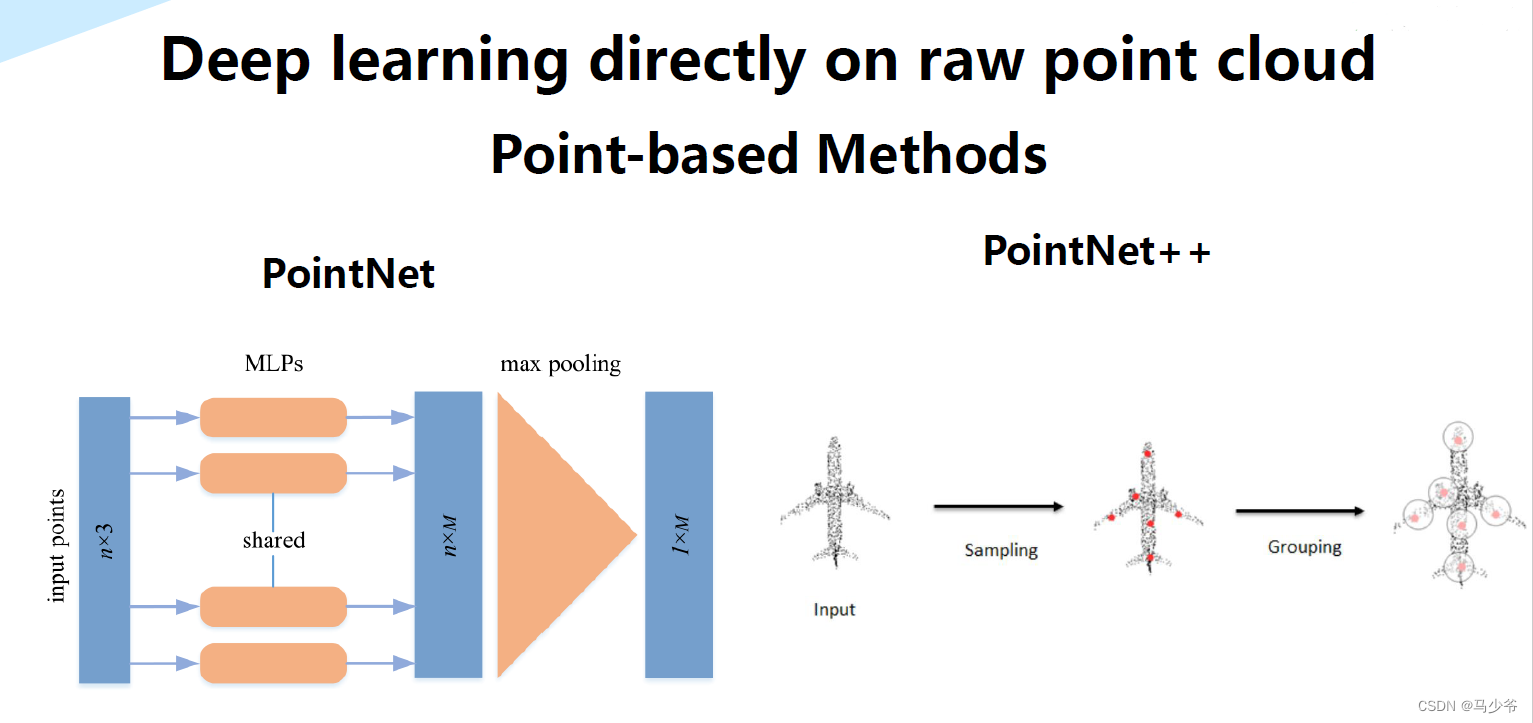
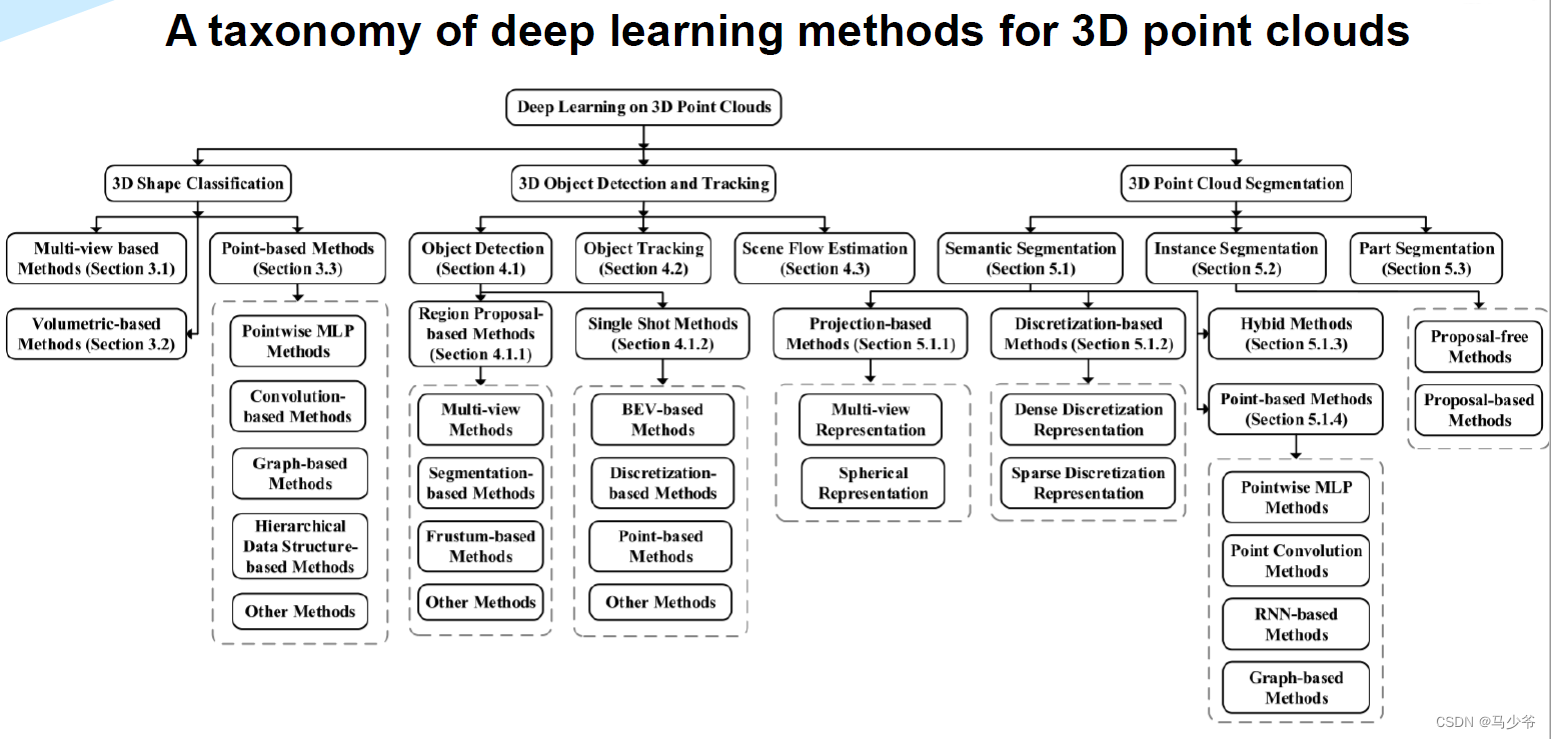
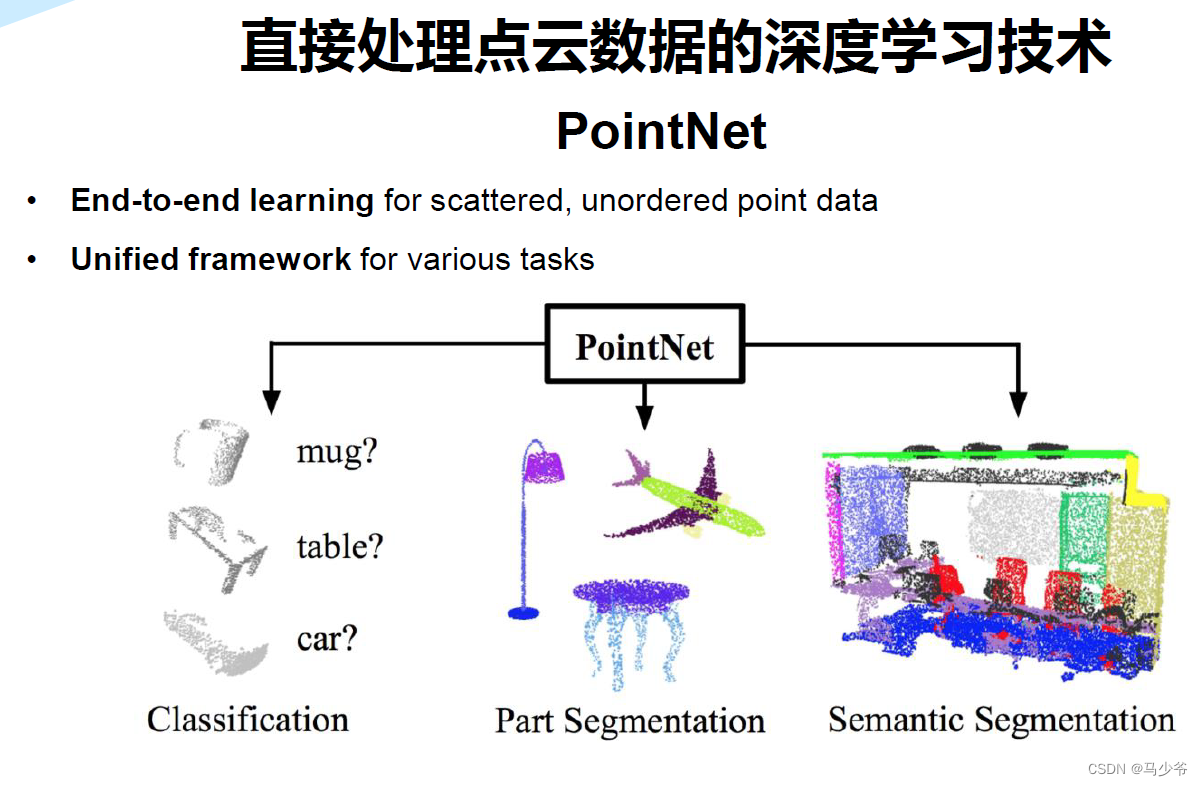
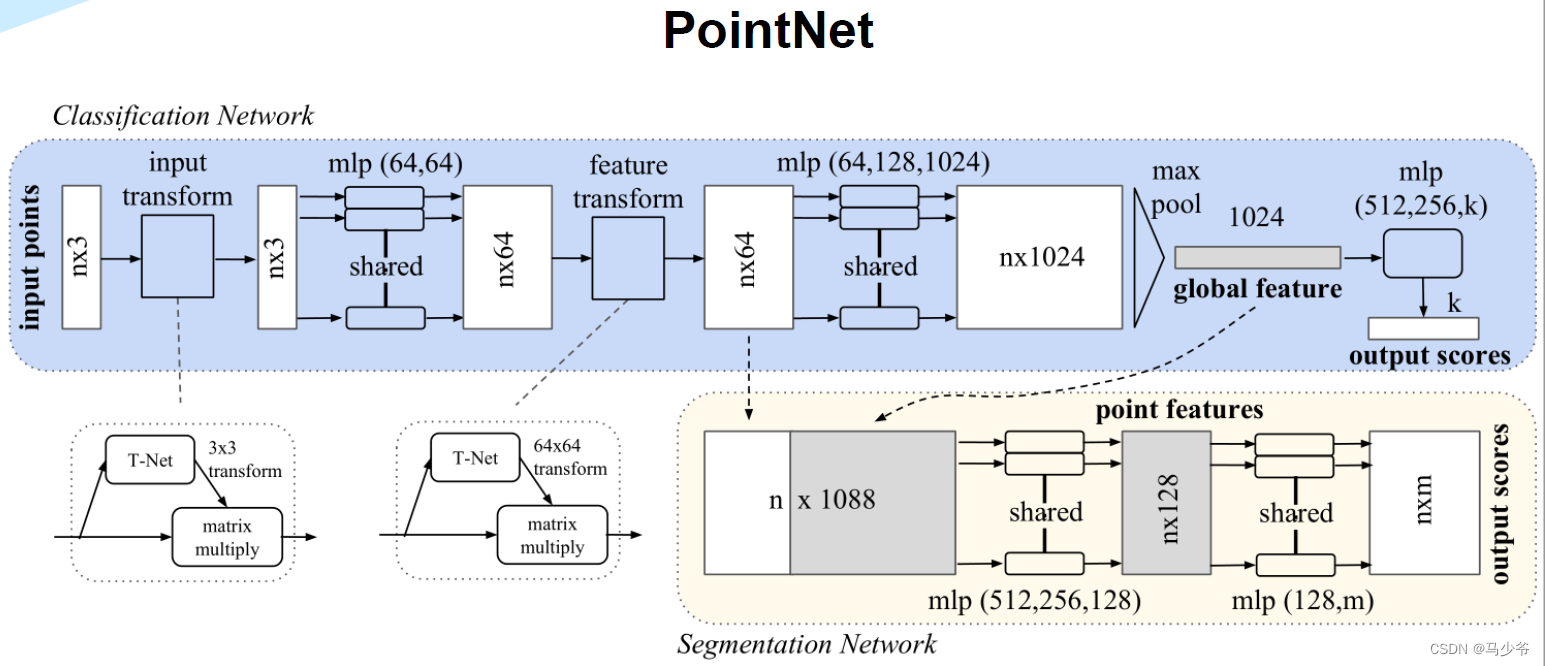
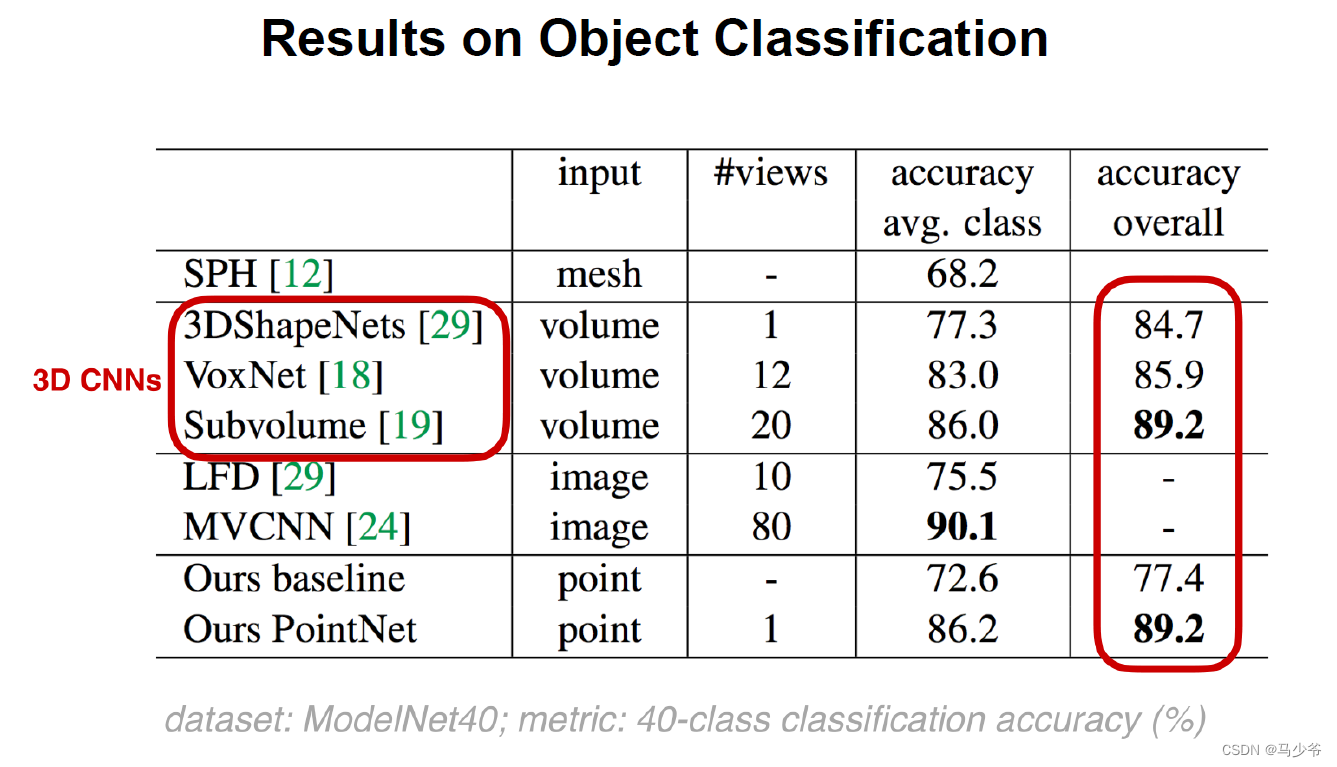
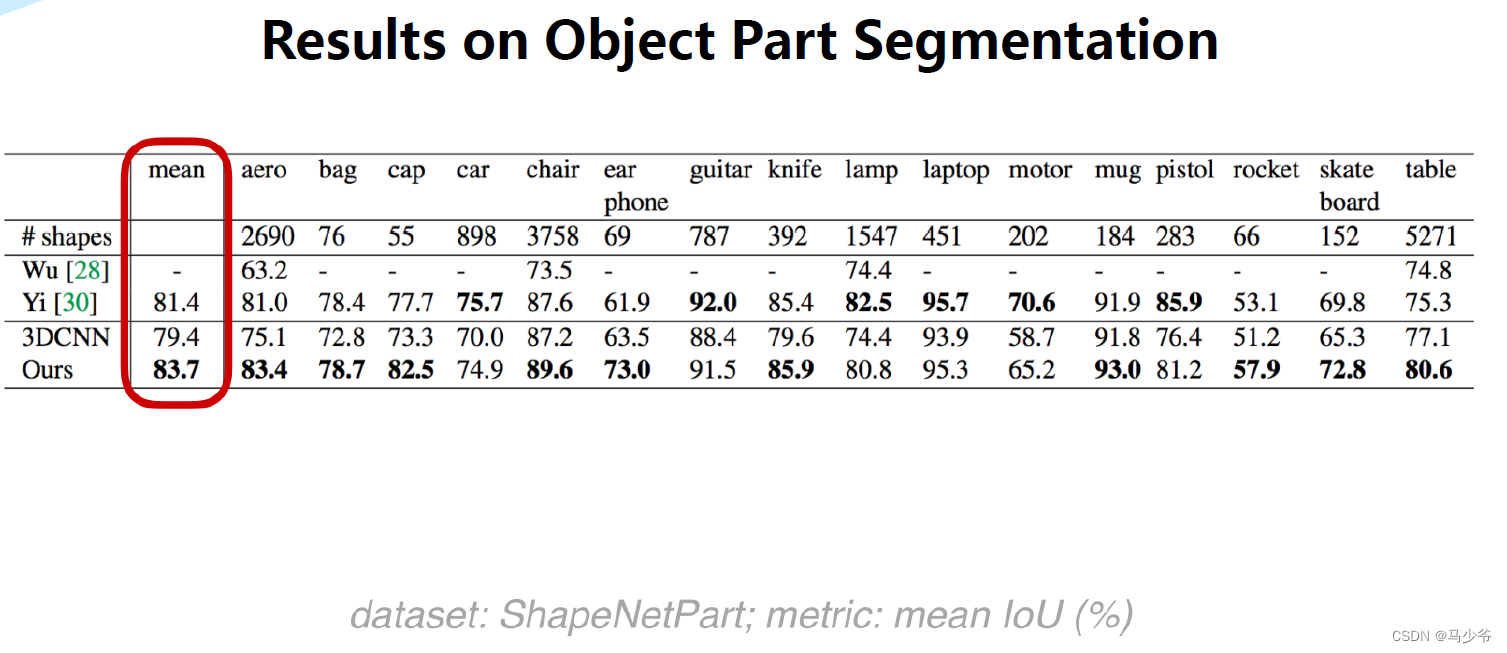
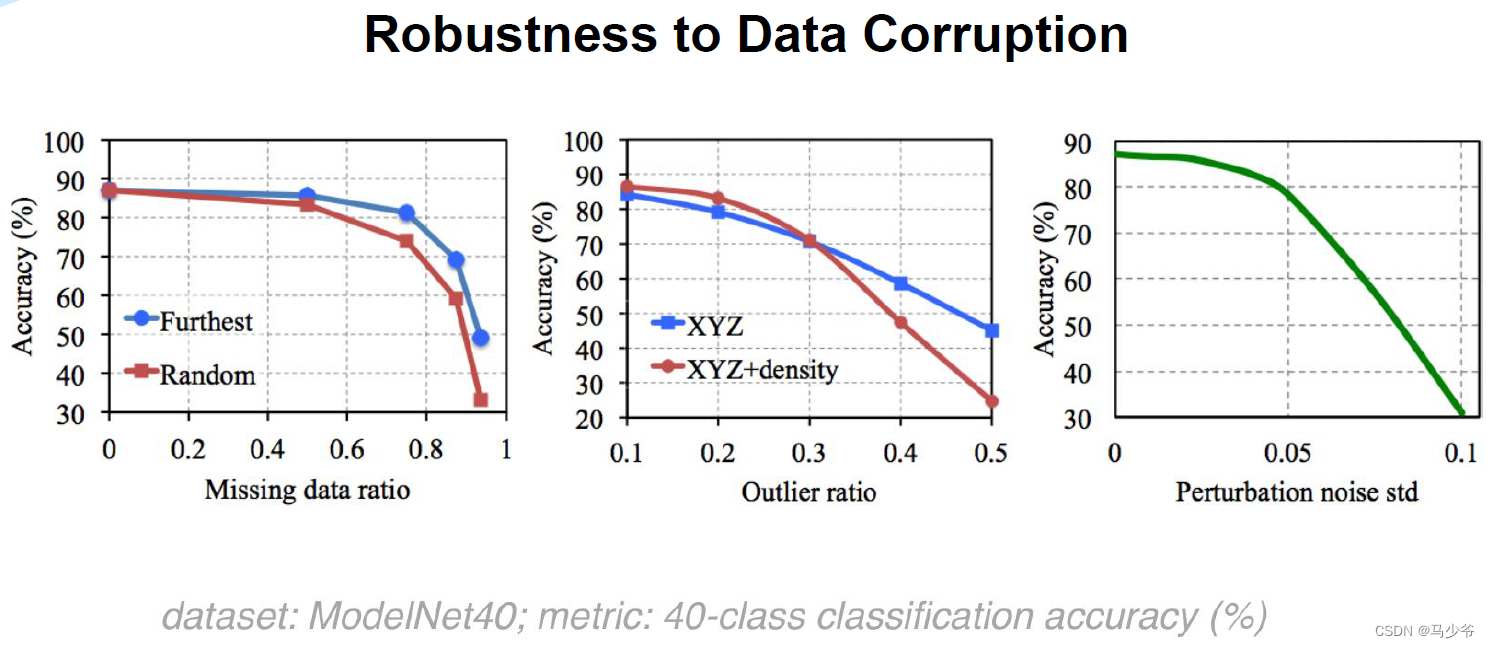
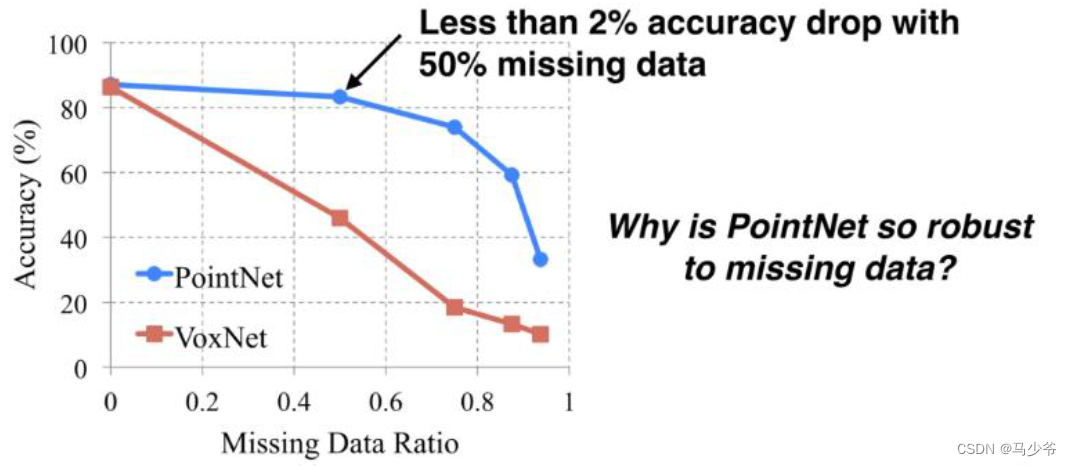
三、Pointnet






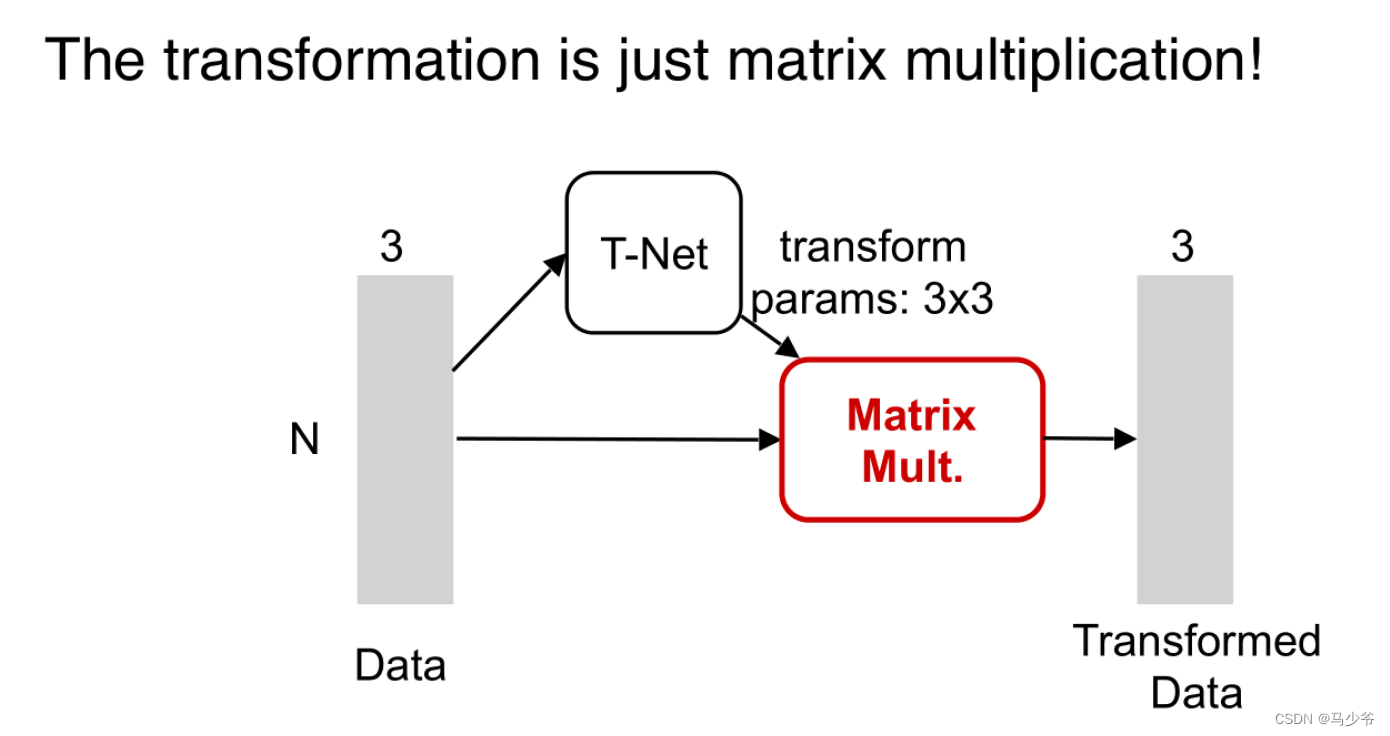
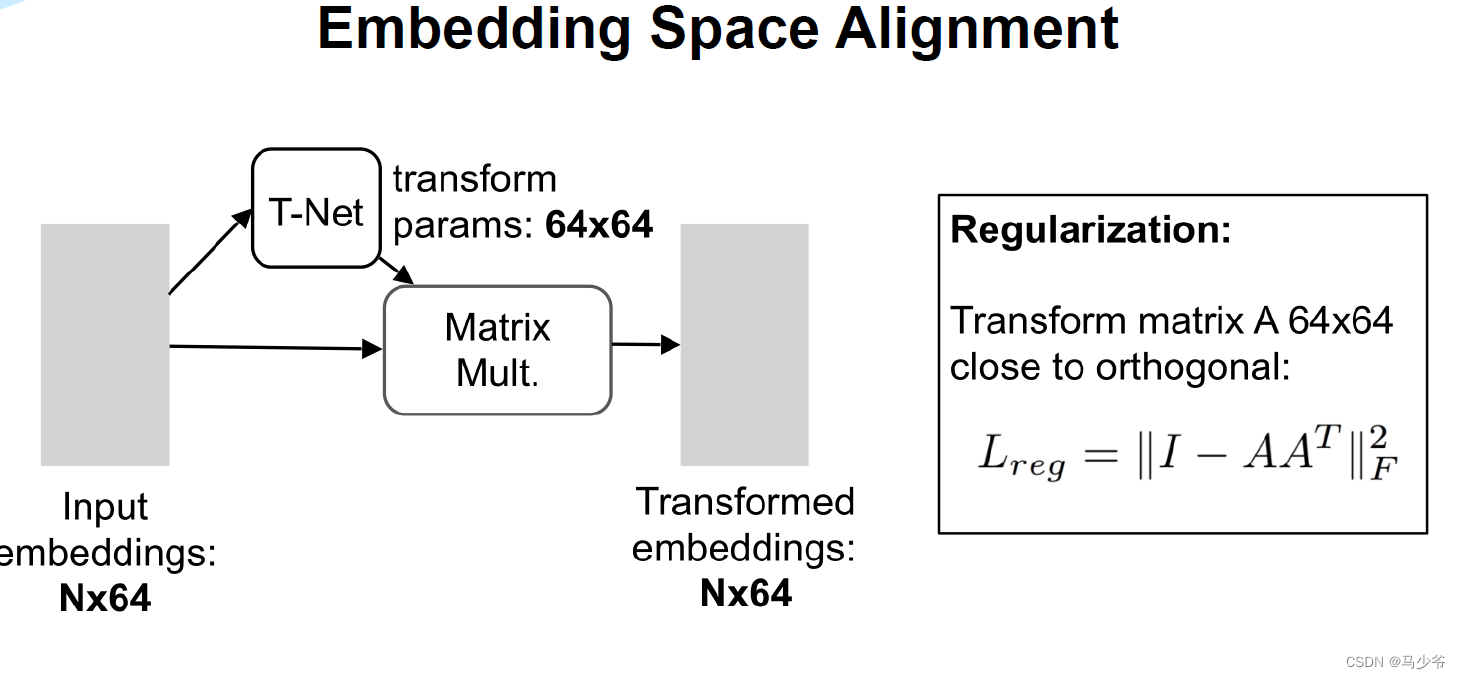
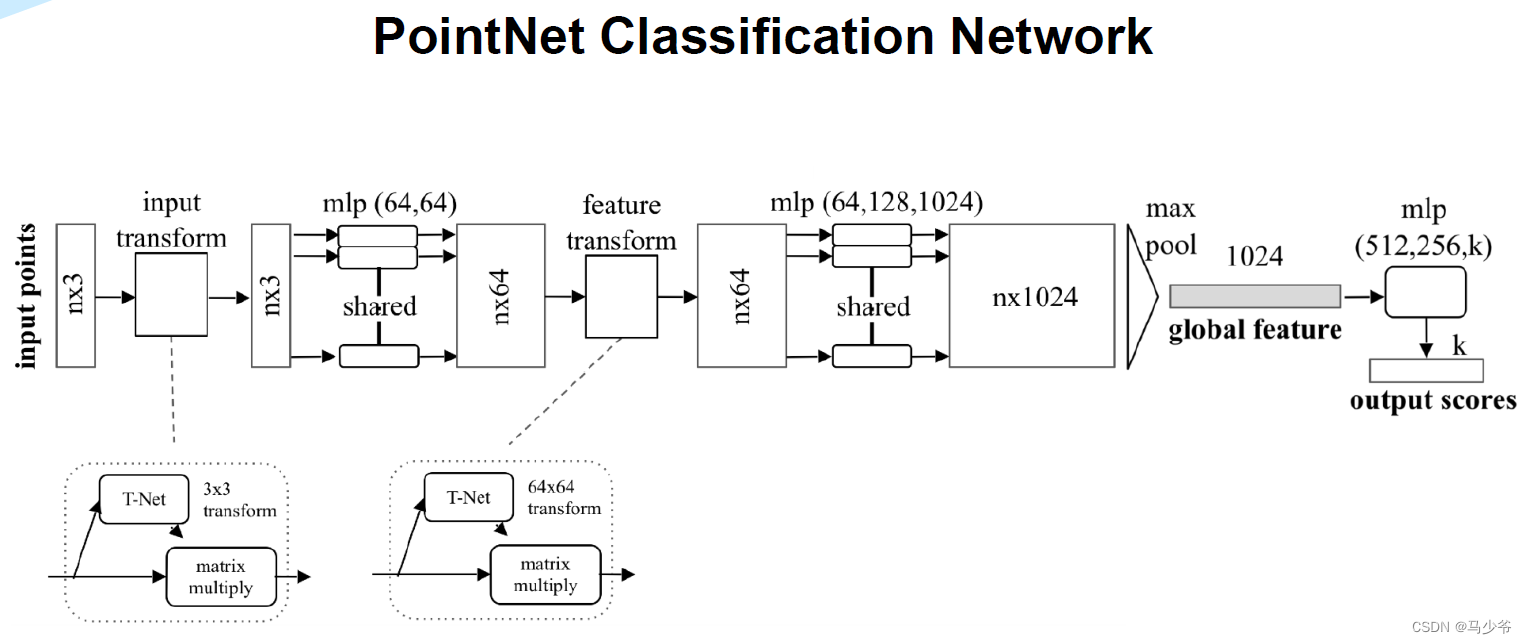
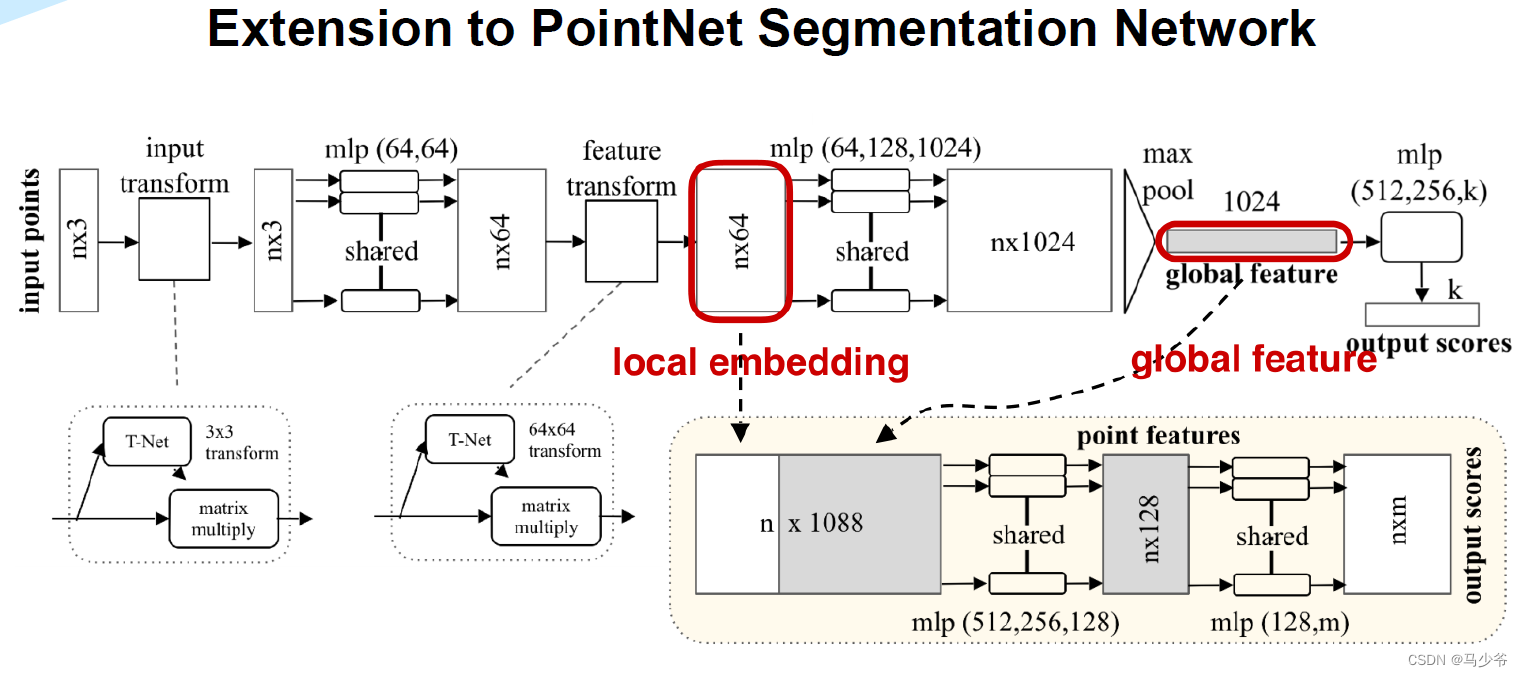


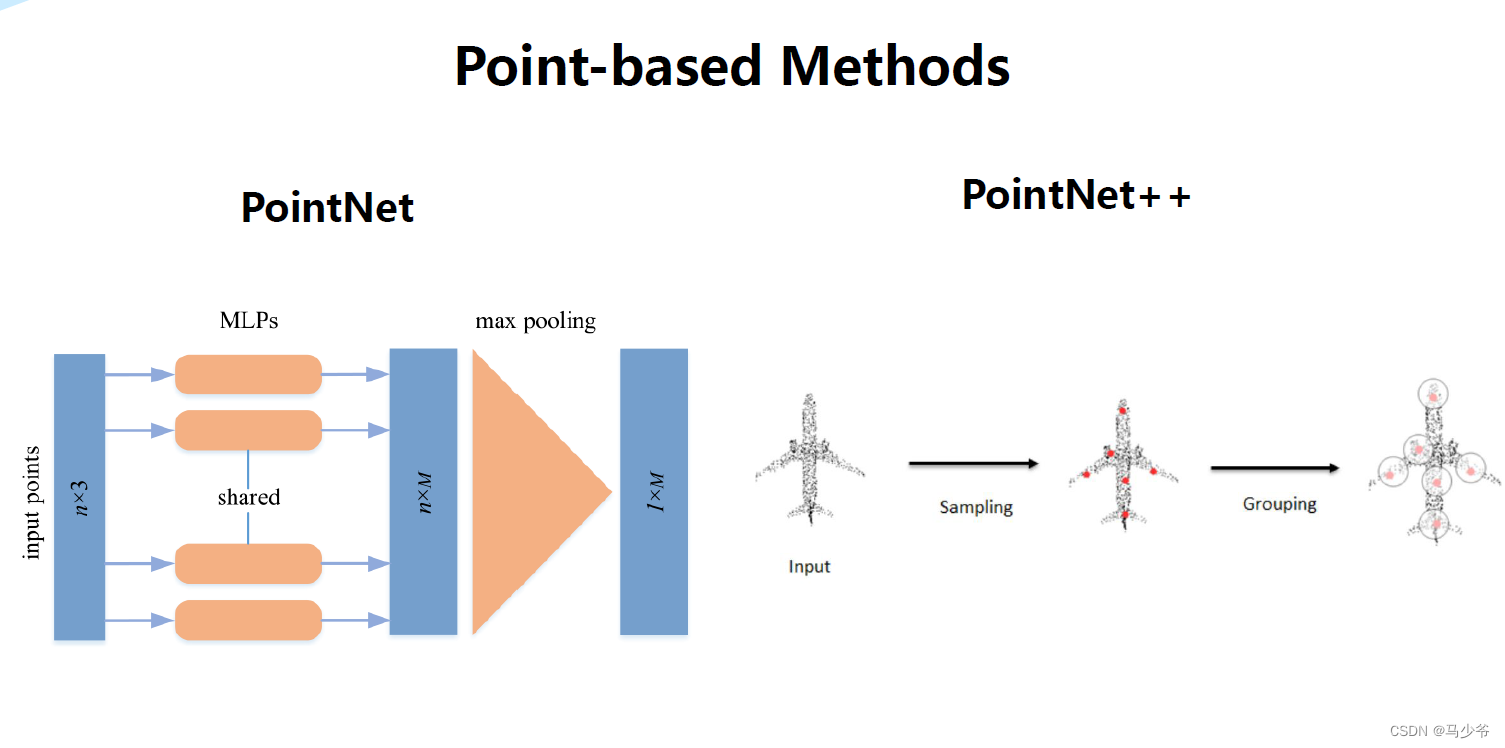
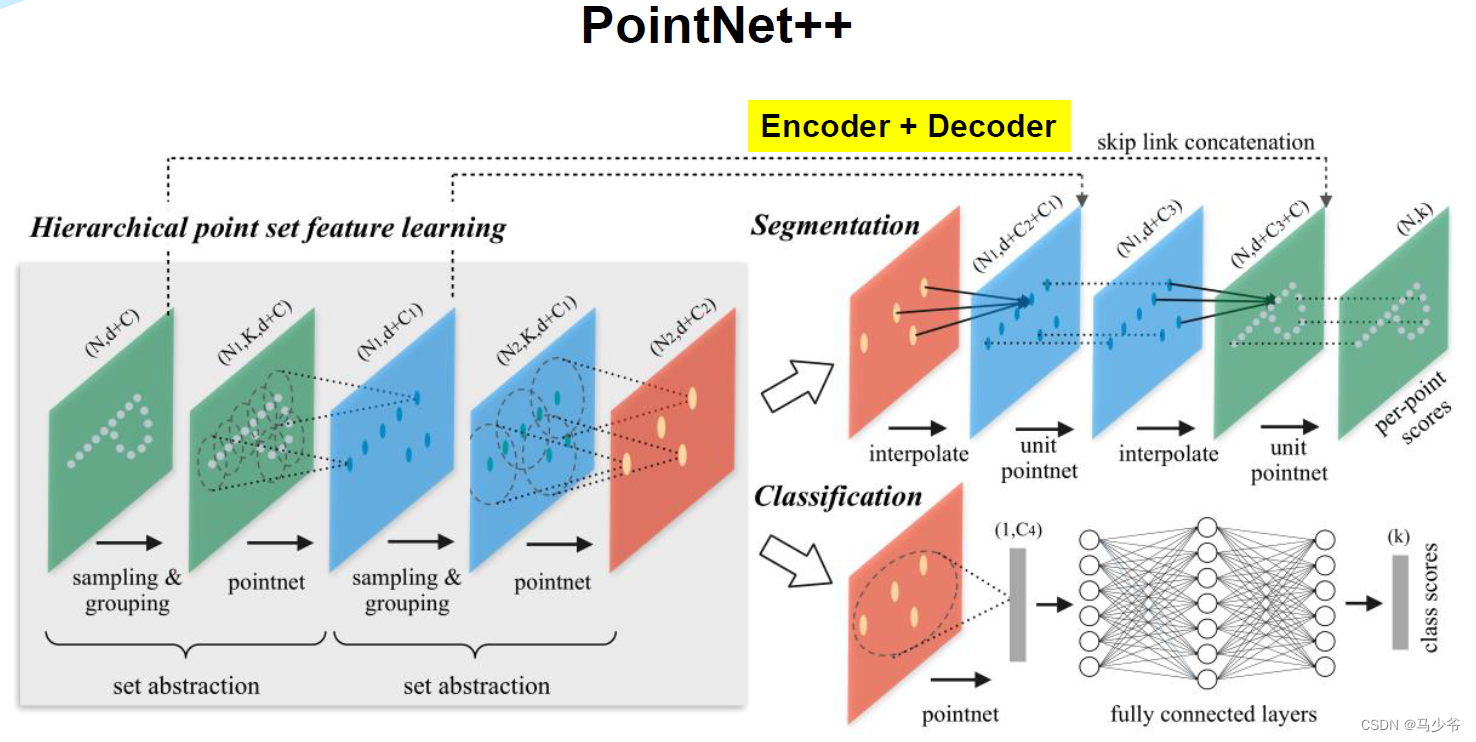
四、Pointnet++

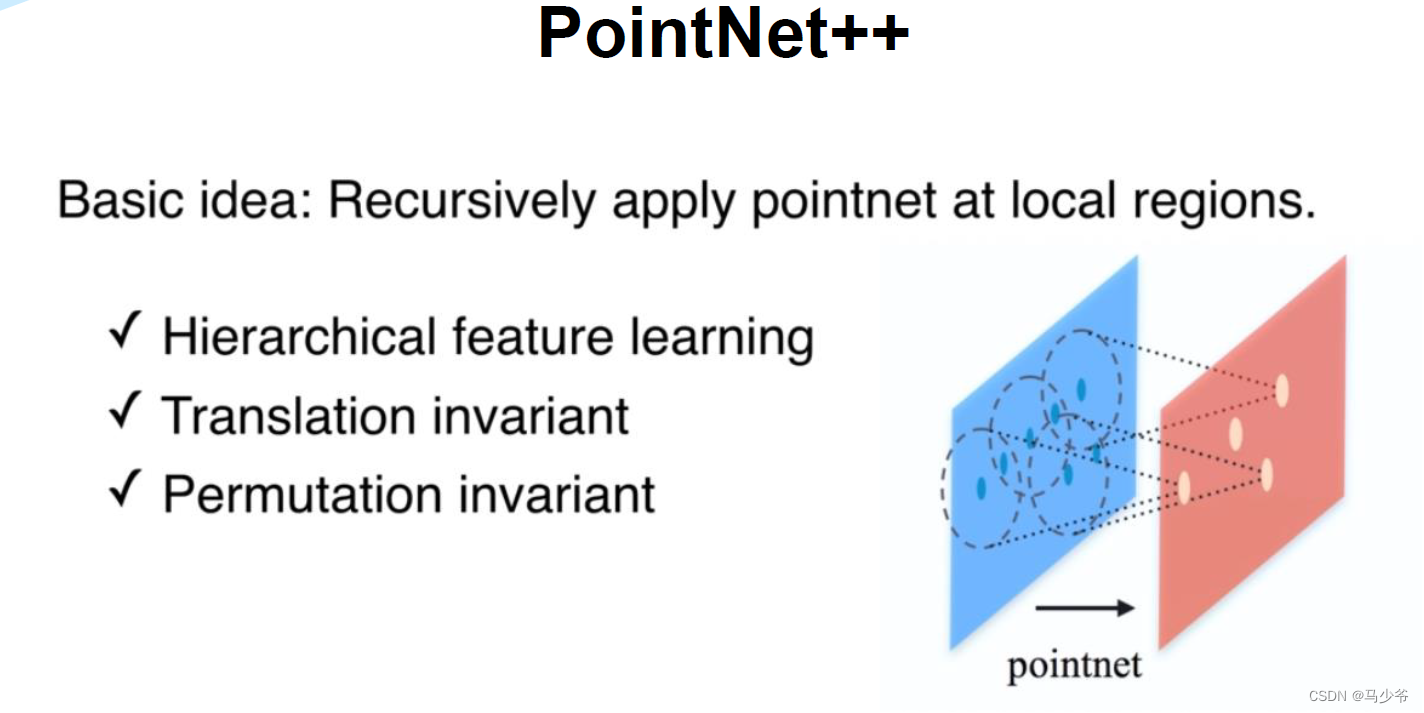





Pointnet++概述
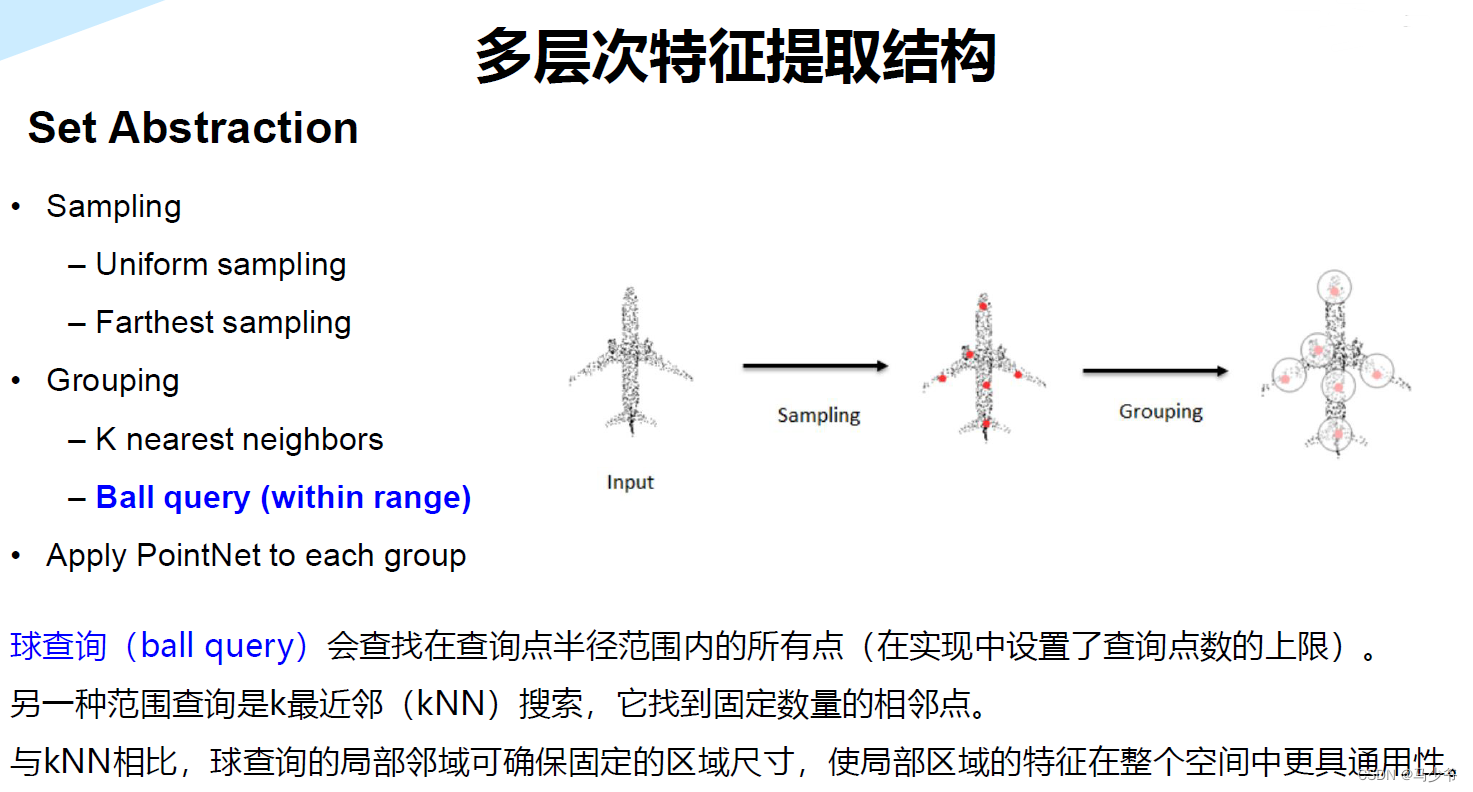
虽然这篇文章叫PointNet++,但和PointNet相比还是有很大的改进。文章非常核心的一点就是提出了多层次特征提取结构。具体来说就是先在输入点集中选择一些点作为中心点,然后围绕每个中心点选择周围的点组成一个区域,之后每个区域作为PointNet的一个输入样本,得到一组特征,这个特征就是这个区域的特征。之后中心点不变,扩大区域,把上一步得到的那些特征作为输入送入PointNet,以此类推,这个过程就是不断的提取局部特征,然后扩大局部范围,最后得到一组全局的特征,然后进行分类。文章中还提出了多尺度的方法解决样本不均匀的问题,这些方法对于分类的精度没有贡献,但在样本很稀疏的时候的确能让模型更有鲁棒性。
1. Abstract
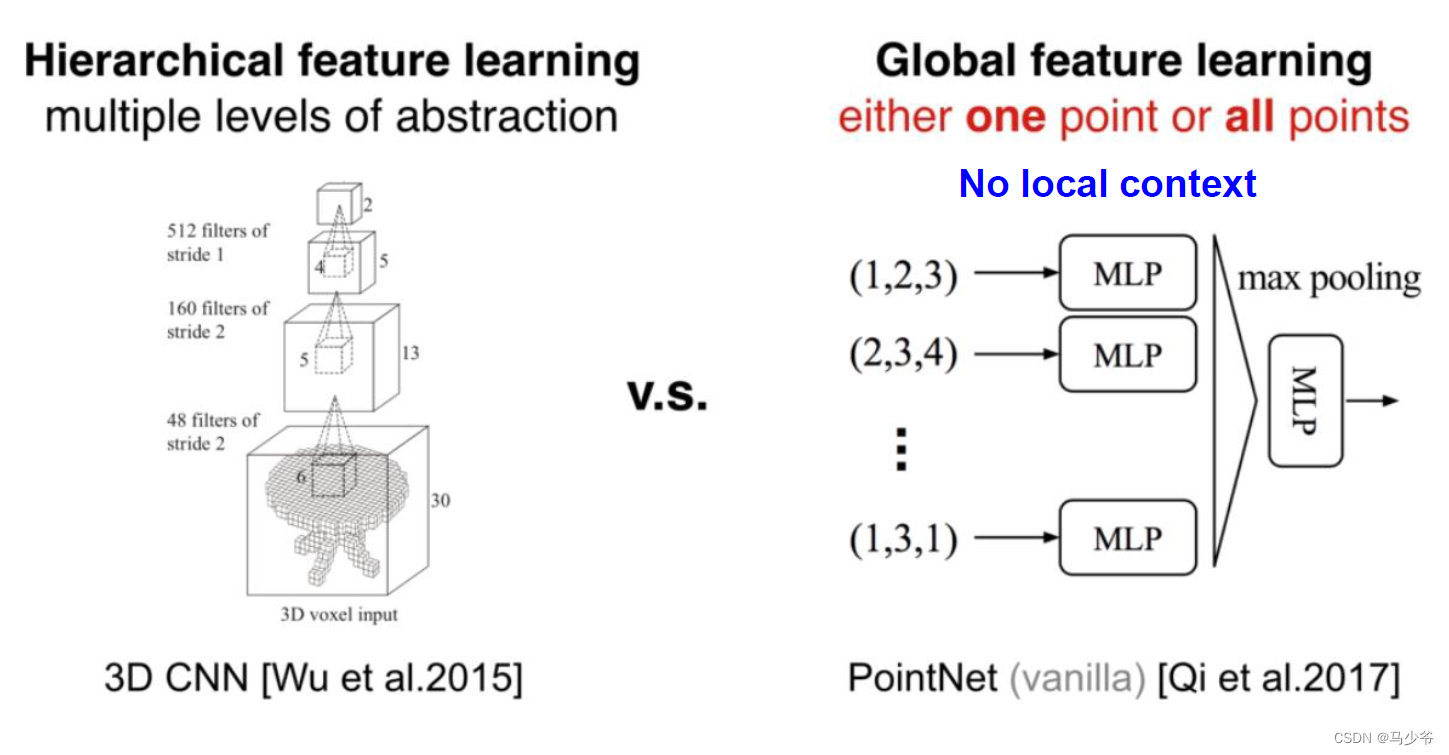
PointNet存在的一个缺点是无法获得局部特征,这使得它很难对复杂场景进行分析。在PointNet++中,作者通过两个主要的方法来进行改进,使得网络能更好的提取局部特征。第一,利用空间距离(metric space distances),使用PointNet对点集局部区域进行特征迭代提取,使其能够学到局部尺度越来越大的特征。第二,由于点集分布很多时候是不均匀的,如果默认是均匀的,会使得网络性能变差,所以作者提出了一种自适应密度的特征提取方法。通过以上两种方法,能够更高效的学习特征,也更有鲁棒性。
2. Introduction
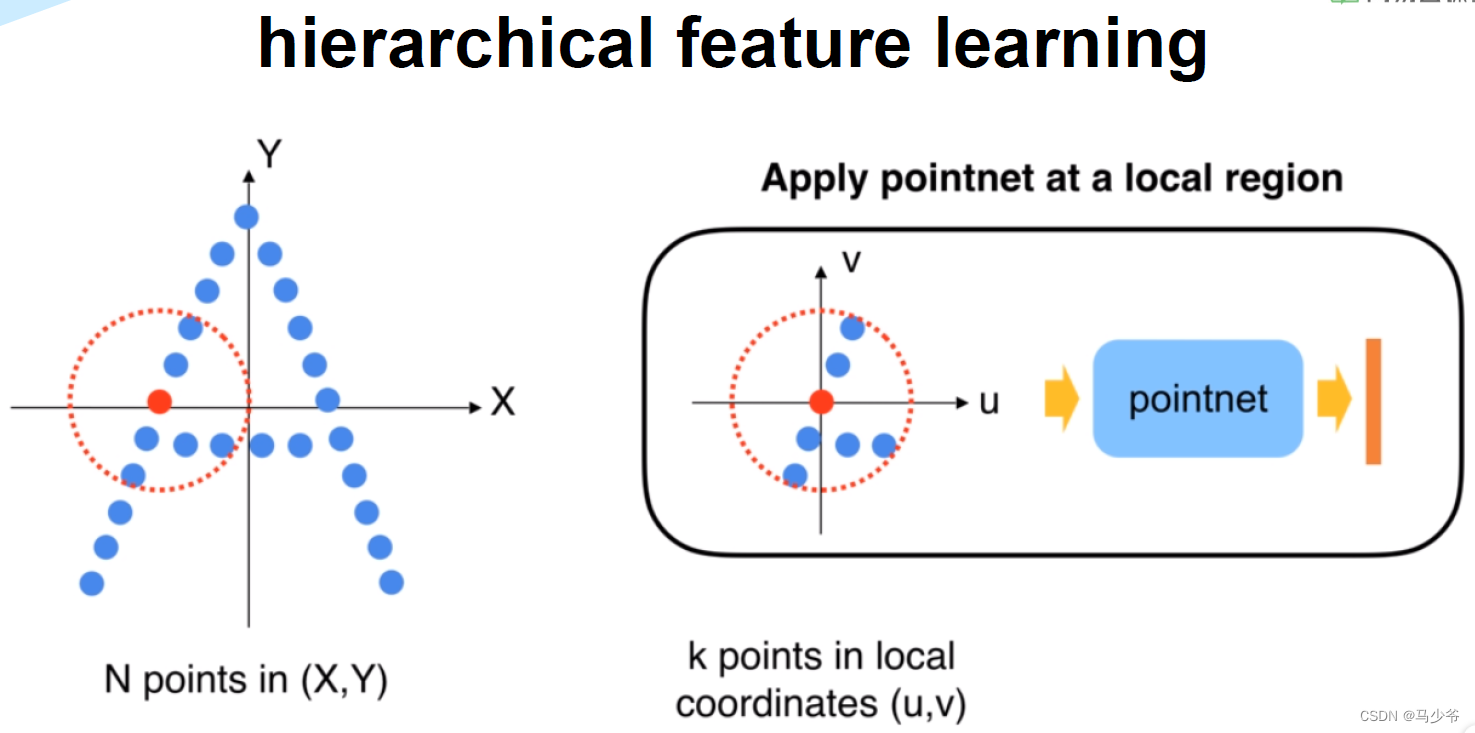
在PointNet++中,作者利用所在空间的距离度量将点集划分(partition)为有重叠的局部区域(可以理解为patch)。在此基础上,首先在小范围中从几何结构中提取局部特征(浅层特征),然后扩大范围,在这些局部特征的基础上提取更高层次的特征,知道提取到整个点集的全局特征。可以发现,这个过程和CNN网络的特征提取过程类似,首先提取低级别的特征,随着感受野的增大,提取的特征level越来越高。
PointNet++需要解决两个关键的问题:第一,如何将点集划分为不同的区域;第二,如何利用特征提取器获取不同区域的局部特征。这两个问题实际上是相关的,要想通过特征提取器来对不同的区域进行特征提取,需要每个分区具有相同的结构。这里同样可以类比CNN来理解,在CNN中,卷积块作为基本的特征提取器,对应的区域都是n*n的像素区域。而在3D点集当中,同样需要找到结构相同的子区域,和对应的区域特征提取器。
在本文中,作者使用了PointNet作为特征提取器,另外一个问题就是如何来划分点集从而产生结构相同的区域。作者使用邻域球球来定义分区,或者也可以叫做patch,每个区域可以通过中心坐标和半径来确定。中心坐标的选取,作者使用了快速采样算法来完成(farthest point sampling (FPS) algorithm)。区域半径的选择是一个比较有挑战性的事情,因为输入点集是不均匀的,同时区域特征会存在重叠或被遗忘的情况。尽管在VGG当中提到,CNN使用小的卷积核效果比较好,但这是由于图像是网格化的,每个区域是非常规整的,如果再PointNet++使用小的半径,网络性能反而很差。这里可以从直观上想象一下,邻域球过小,可能意味着可能看不到足够完整的局部特征。这个过程也可是使用KNN实现。
3. 网络结构
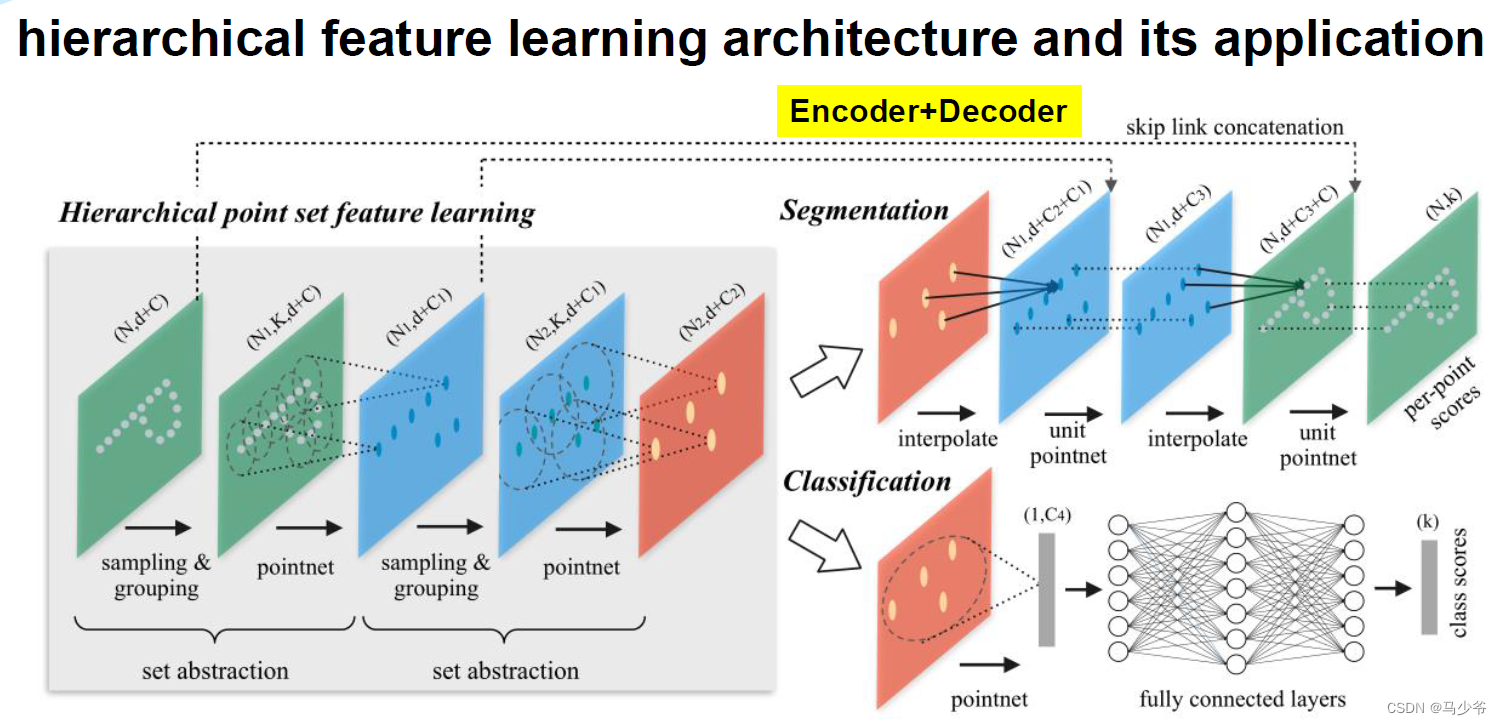
PointNet++是PointNet的延伸,在PointNet的基础上加入了多层次结构(hierarchical structure),使得网络能够在越来越大的区域上提供更高级别的特征。
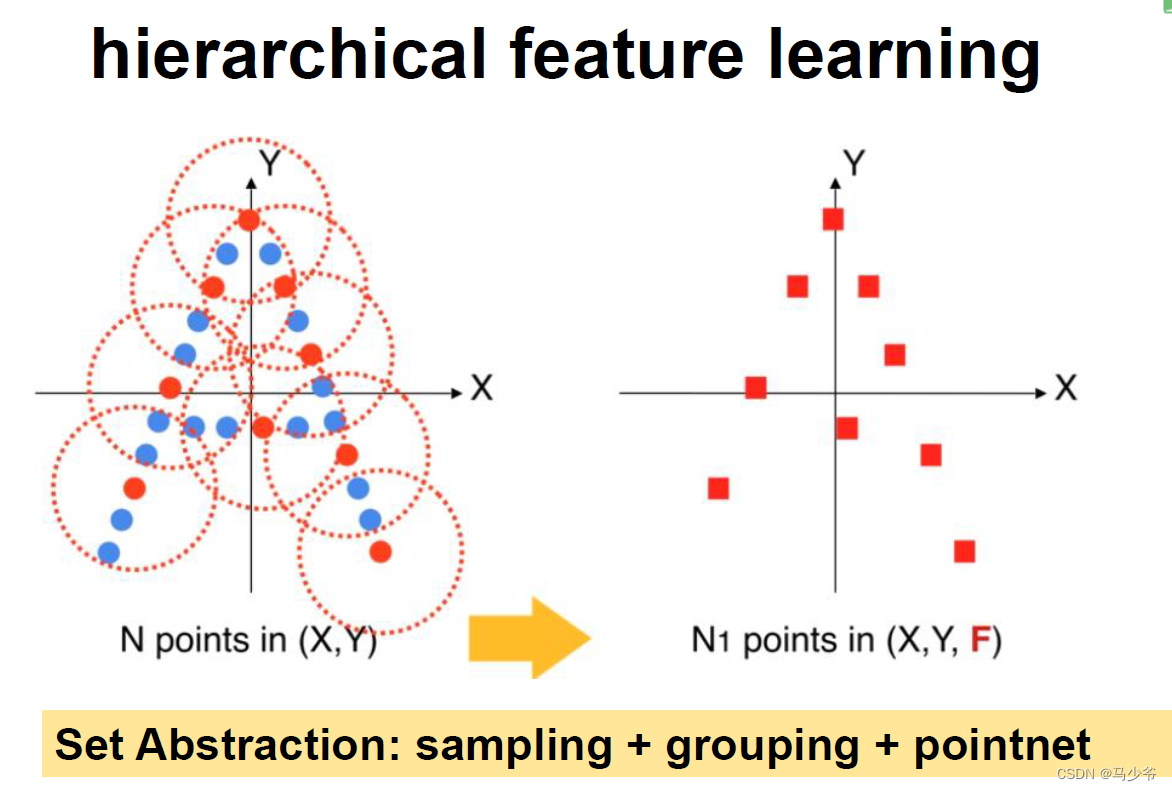
网络的每一组set abstraction layers主要包括3个部分:Sampling layer, Grouping layer and PointNet layer。
- ·Sample layer:主要是对输入点进行采样,在这些点中选出若干个中心点(问题:怎么选,选多少个点?)
- Grouping layer:是利用上一步得到的中心点将点集划分成若干个区域;
- PointNet layer:是对上述得到的每个区域进行编码,变成特征向量。
每一组提取层的输入是N*(d + C),其中N是输入点的数量,d是坐标维度,C是特征维度。输出是N’*(d + C’),其中N’是输出点的数量,d是坐标维度不变,C’是新的特征维度。下面详细介绍每一层的作用及实现过程。
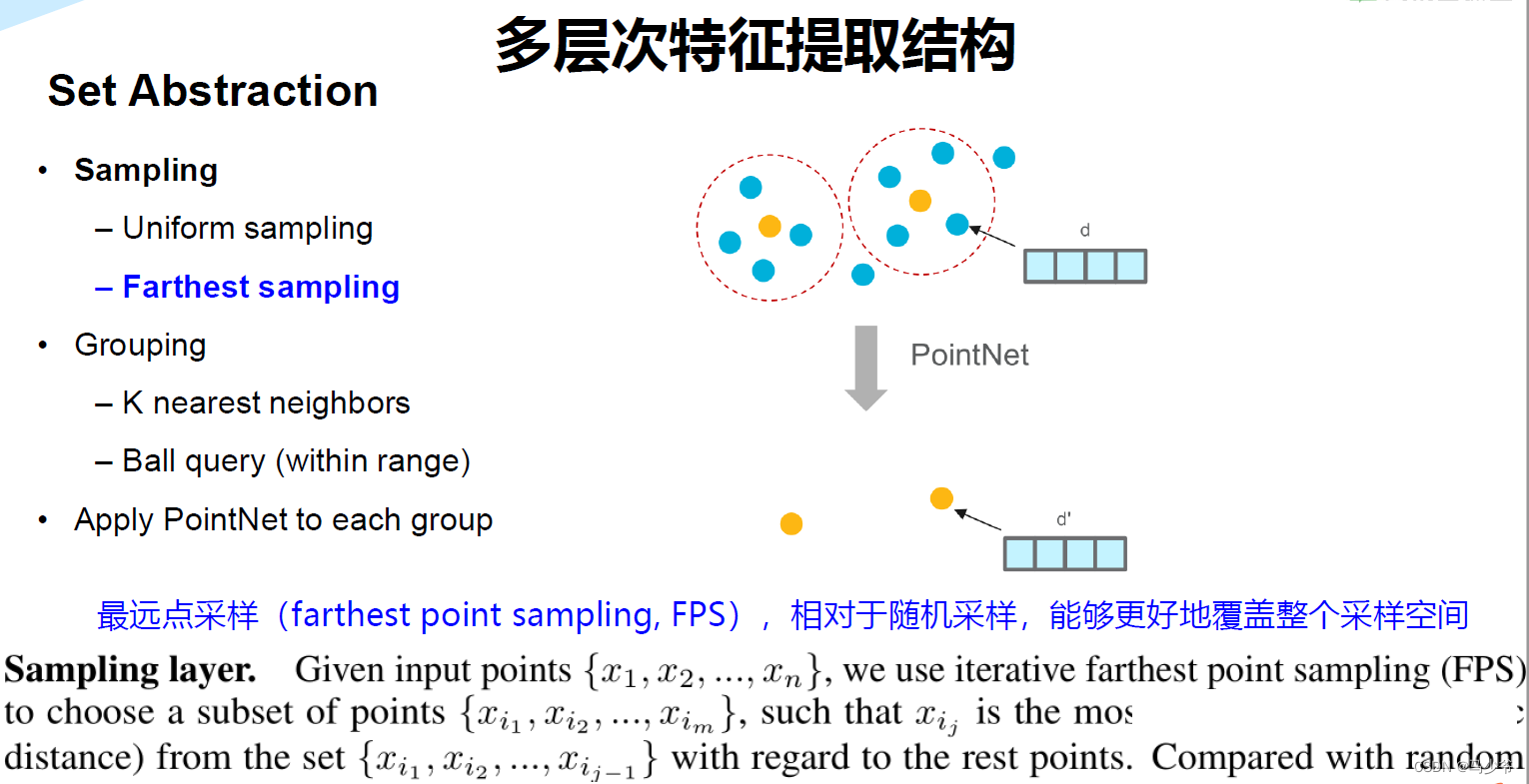
1). Sample layer
使用farthest point sampling选择N’个点,至于为什么选择使用这种方法选择点,文中提到相比于随机采样,这种方法能更好的的覆盖整个点集。具体选择多少个中心点,数量怎么确定,是由人来指定的。
2). Grouping layer
这一层使用Ball query方法生成N’个局部区域,根据论文中的意思,这里有两个变量 ,一个是每个区域中点的数量K,另一个是球的半径。这里半径应该是占主导的,会在某个半径的球内找点,上限是K。球的半径和每个区域中点的数量都是人指定的。这一步也可以使用KNN来进行,而且两者的对于结果的影响并不大。

3). PointNet layer
这一层是PointNet,接受N’×K×(d+C)的输入。输出是N’×(d+C)。需要注意的是,在输入到网络之前,会把该区域中的点变成围绕中心点的相对坐标。作者提到,这样做能够获取点与点之间的关系(对这一点存疑,但感觉有限像Batch Norm?)。
4). 对于非均匀点云的处理方法
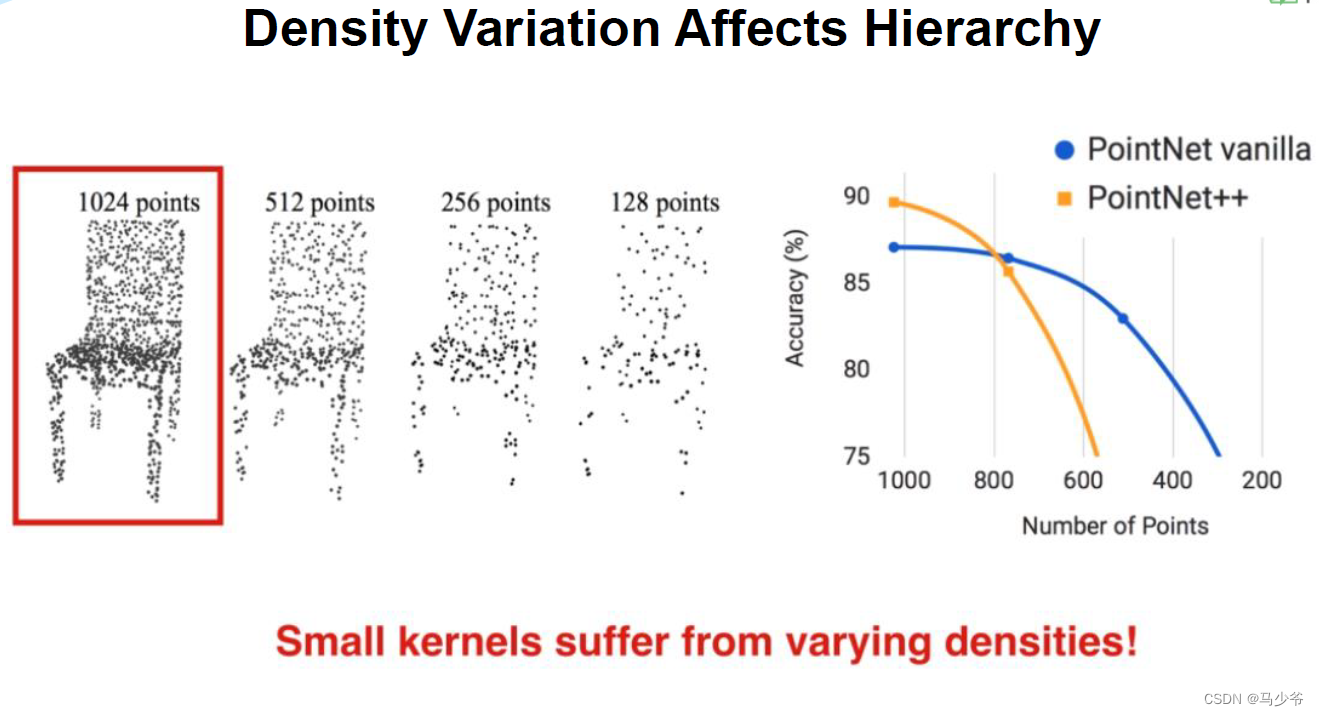
点云不均匀时,每个子区域中如果在分区的时候使用相同的球半径,会导致有些稀疏区域采样点过小。这个地方插一点自己的想法,从一个角度来看,点云的疏密程度是不是可以看做样本属性的一部分?从这个意义上来讲这就不是一个需要克服的缺点。如果担心某些区域采样点过小,是否可以加一个阈值下限。
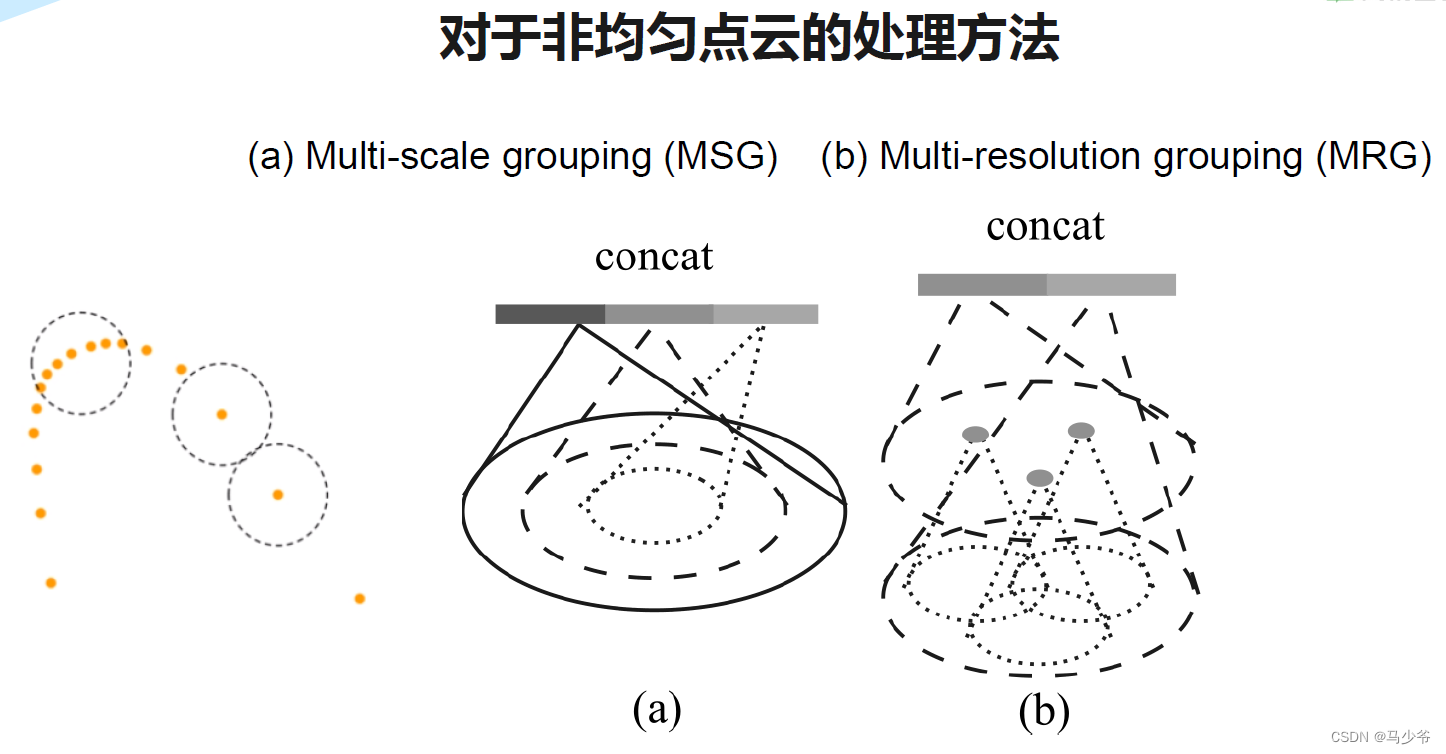
作者提到这个问题需要解决,并且提出了两个方法:Multi-scale grouping (MSG) and Multi-resolution grouping (MRG)。下面是论文当中的示意图。
下面分别介绍一下这两种方法。第一种多尺度分组(MSG),对于同一个中心点,如果使用3个不同尺度的话,就分别找围绕每个中心点画3个区域,每个区域的半径及里面的点的个数不同。对于同一个中心点来说,不同尺度的区域送入不同的PointNet进行特征提取,之后concat,作为这个中心点的特征。也就是说MSG实际上相当于并联了多个hierarchical structure,每个结构中心点数量一样,但是区域范围不同(可以理解成感受野?),PointNet的输入和输出尺寸也不同,然后几个不同尺度的结构在PointNet有一个Concat。
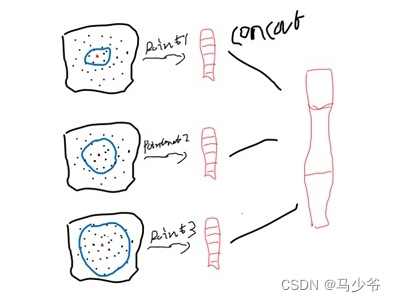
另一种是多分辨率分组(MRG)。MSG很明显会影响降低运算速度,所以提出了MRG,这种方法应该是对不同level的grouping做了一个concat,但是由于尺度不同,对于low level的先放入一个pointnet进行处理再和high level的进行concat。感觉和ResNet中的跳连接有点类似。
在这部分,作者还提到了一种random input dropout(DP)的方法,就是在输入到点云之前,对点集进行随机的Dropout,比例使用了95%,也就是说进行95%的重新采样。某种程度有点像数据增强,也是提高模型的robustness。那这些方法效果怎么样呢,我们一起来看一下。
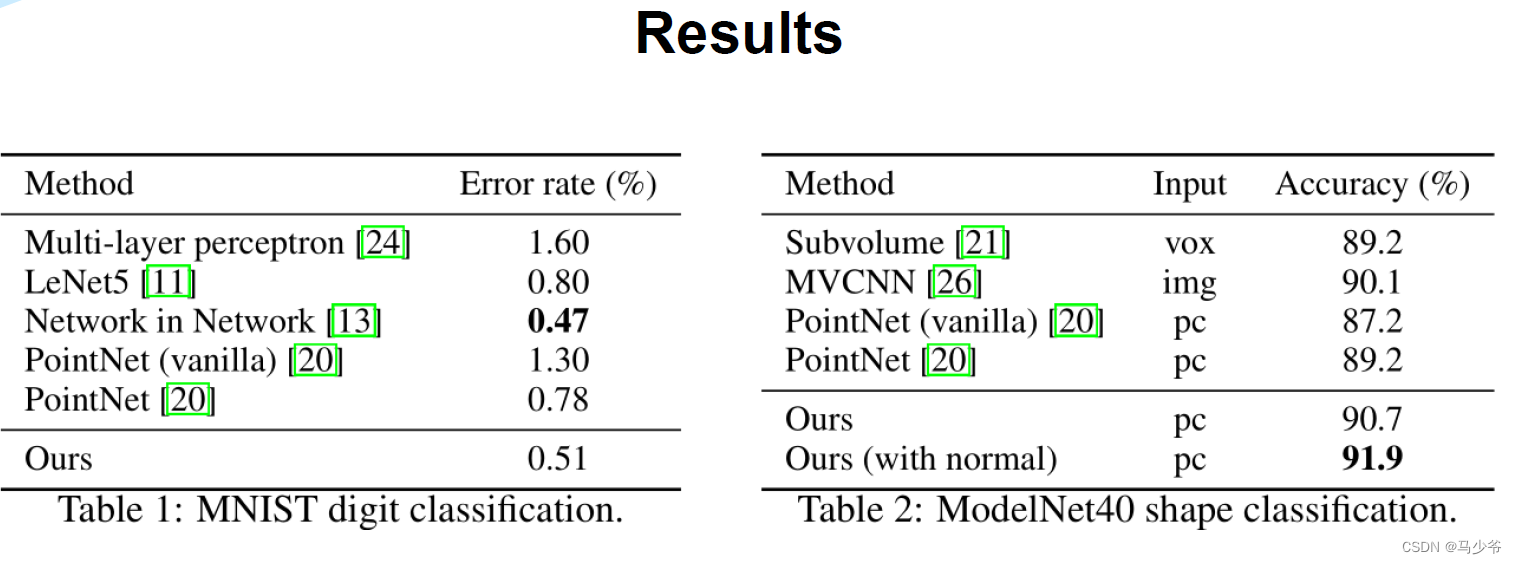
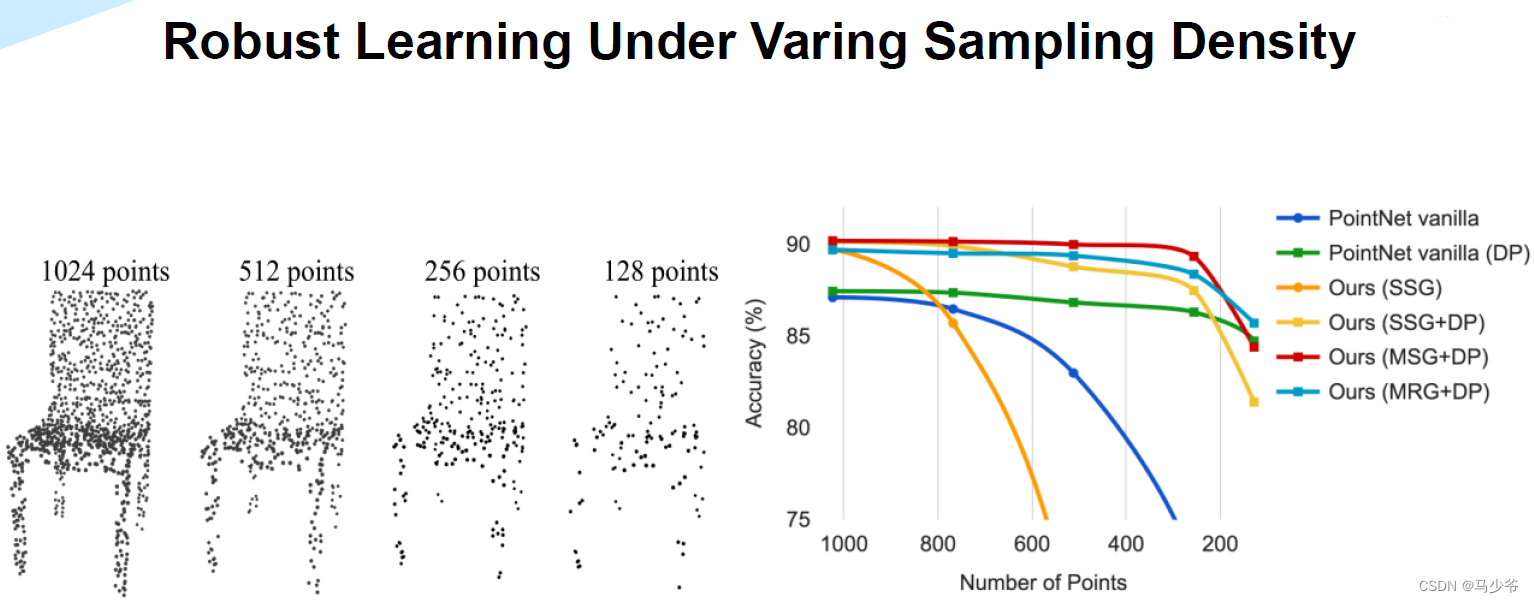
从论文中的这幅分类实验结果图可以看出来,多尺度(MSG,MRG)和单一尺度相比(SSG)对分类的准确率没有什么提升,有一个好处是如果点云很稀疏的话,使用MSG可以保持很好的robustness。对于robustness效果random input dropout(DP)其实贡献更大。
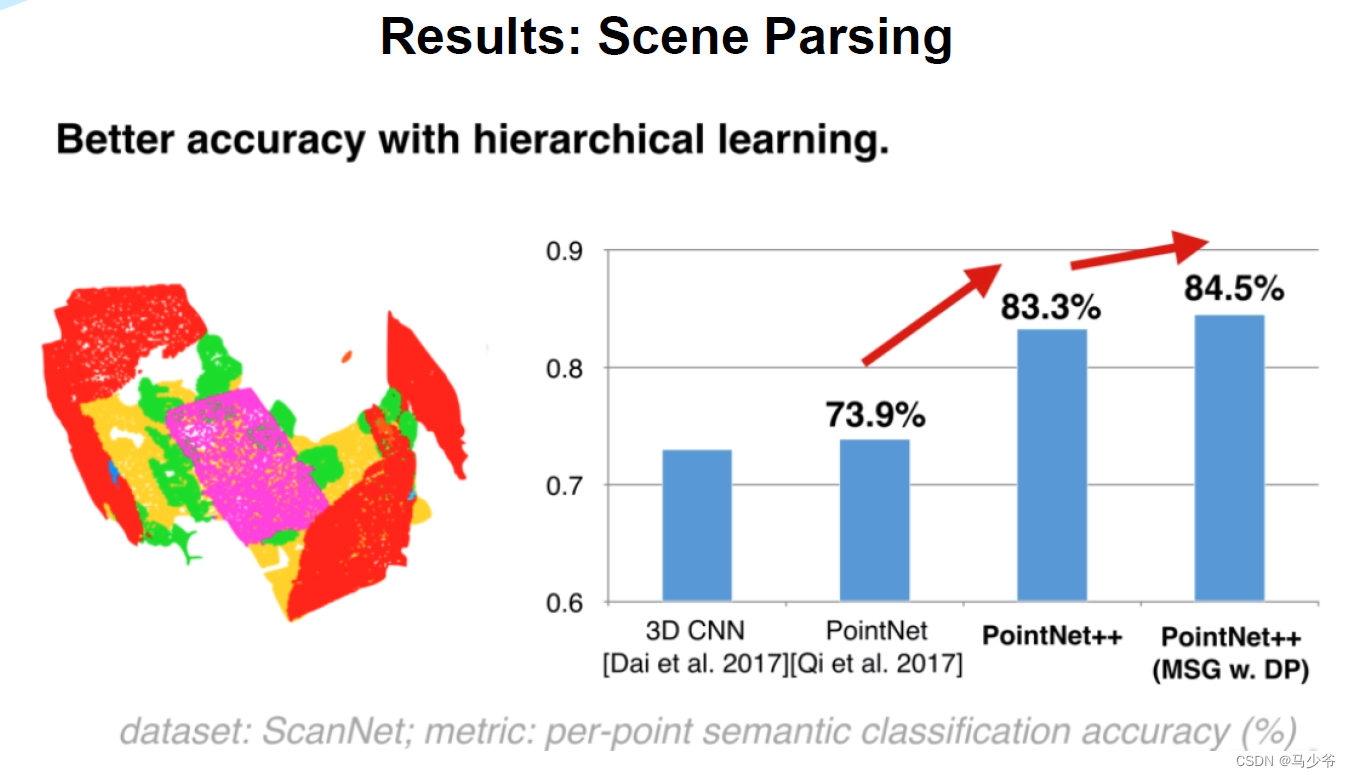
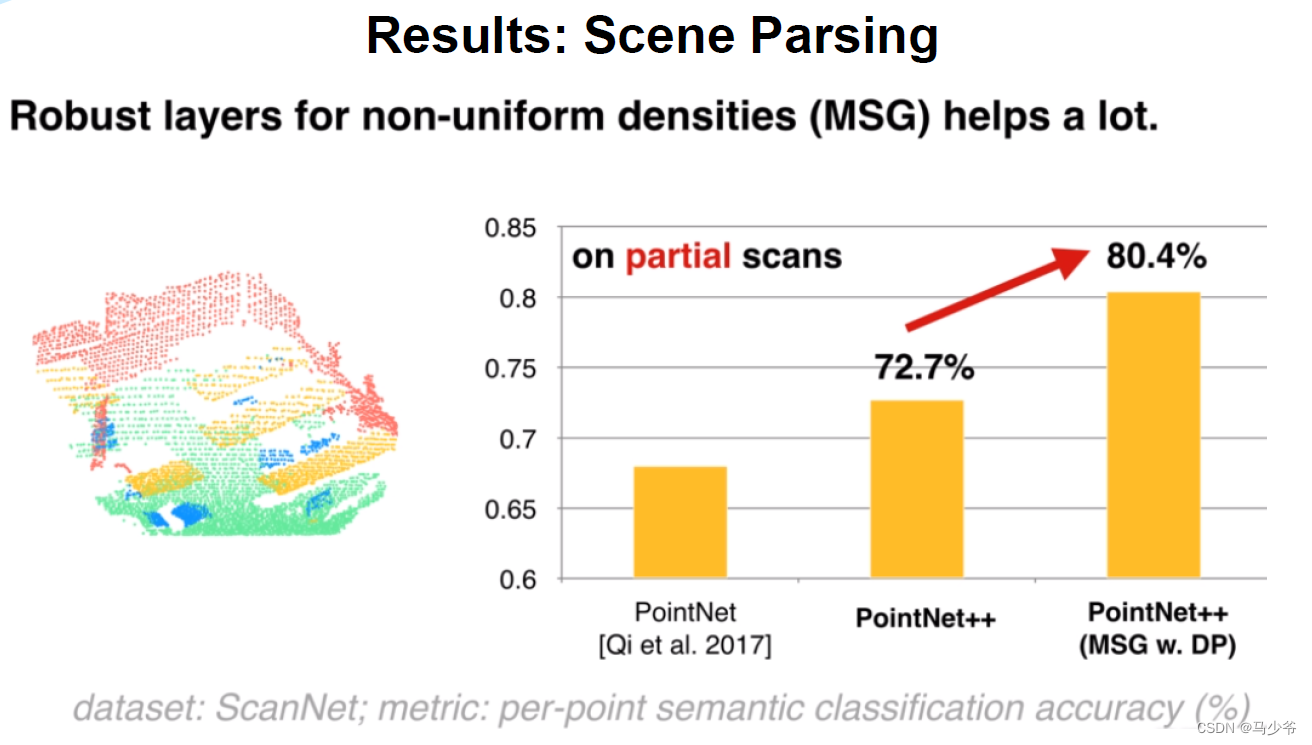
从论文中的分割实验结果看,使用(MSG+DP)之后的确是比SSG结果提升了,在非均匀点云上差距会大一点,但是作者并没有给出MSG和DP对于效果提升单独的贡献对比,所以我们很难确定到底是MSG还是DP在这其中起作用了。
4. 通过代码理解核心结构
通过核心代码来理解一下PointNet++中的hierarchical structure(也叫set abstraction layers)到底是这怎工作的,上图是3层set abstraction layers(以SSG(单一尺度)为例)。
我们以第一层set abstraction layers为例解释一下,对应line9代码(PointNet Set Abstraction (SA) Module)。假设输入点云数据是(16,1024,3),也就是一个样本1024个点,只有xyz坐标。把它送入到第一层set abstraction layers。设置的参数:
- l0_xyz: <只包含坐标的点> l0_points: <不仅包含坐标,还包含了每个点经过之前层后提取的特征,所以第一层没有>
- npoint = 512: <Sample layer找512个点作为中心点,这个手工选择的,靠经验或者说靠实验>
- radius=0.2: <Grouping layer中ball quary的球半径是0.2,注意这是坐标归一化后的尺度>
- nsample=32: <围绕每个中心点在指定半径球内进行采样,上限是32个;半径占主导> mlp=[64,64,128]:<PointNet layer有3层,特征维度变化分别是64,64,128> #还有别的参数,不太要紧,这里去掉不说
进一步看一下每一层是怎么实现的,重点看数据的传递形式。
SA(512,0.2,[64,64,128]) -> SA(128,0.4,[128,128,256]) -> SA([256,512,1024]) ->
FC1 -> FC2 -> FC(K)
数据首先进行sampling 和 grouping,对应下面代码,看一下这个函数如何实现。
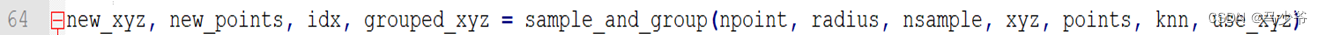
这个函数输入就是上面传进来的,解释一下输出。
- new_xyz: 经过sampling后,得到的512个中心点的坐标 idx:是每个区域内点的索引
- grouped_xyz:分组后的点集,是一个四维向量(batch_size, 512个区域,每个区域的32个点,每个点3个坐标)
- new_points:也是就是分组后的点集,不过里面存的是特征,如果是第一次,就等于grouped_xyz,可以选择在卷积的时候把坐标和特征进行concat后卷积。

采样之后很重要的一点是分区,就是上面这个两个函数,如果是使用KNN分区,因为只是取每个中心点周围的固定个数的点(即上面提到的32),idx就是这些坐标的索引,点的个数就是(32*512),可以发现,原始点云是1024个,这样就必然会导致区域重叠,没关系,这是需要的效果。
ball query后得到的是idx,和pts_cnt,因为是优先根据radius分区,每个区域的点的数量是不确定的(最大32),所以pts_count就是计数的,每个区域有多少个点,方便把idx分开。
下图是ball query(a)和KNN(b)的示意图,一个是半径为主,一个是只看点的数量。

得到每个区域的点的索引后分组,结果是一个四位向量(batch_size, 512个区域,每个区域的32个点,每个点3个坐标),如下图。这里感觉有个漏洞,如果是用ball query得到的,每组的点的个数不是32,但这里又没有传入pts_cnt的值,那又是怎么知道如何分配idx?

下面来看PointNet层
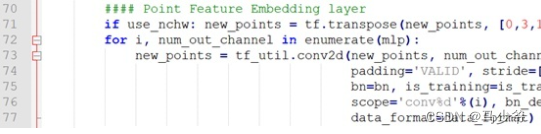
grouping后的点集进行卷积,可以注意一下,我们上面已经说过,new_points是一个4维向量<(batch_size,512, 32, 3)——(batch_size, 512个区域,每个区域的32个点,每个点对应的特征)>512个区域,每个区域32个点。每个区域的32个点经过PointNet的卷积核池化,整合成一组特征,这一组特征就属于每个区域的中心点。
参考文献:https://zhuanlan.zhihu.com/p/88238420