
Hierarchical point set feature learning(层次化特征学习):由一系列set abstraction层(点集抽象层)堆叠而成,每个抽象层都包括三个部分:1)采样——最远点采样(FPS)选取簇的中心,就是选取簇的中心的时候当前要选择的点是距离前面所有已选择的点的距离最远的点,这样能保证采样尽可能覆盖所有的点,这种方式不是像CNN卷积那样一成不变,而是依赖于数据本身的;2)组合——按采样得到的中心组合邻域内的点形成簇,作者提出了两种方案,一种是KNN,组合离中心最近的固定K个点,一种是Ball query即球形检索,在给定半径的球邻域中选取点,K不是固定的,但是会设置一个上限,由于Ball query更能保证在每层set abstraction中特征提取的尺度,所以选择了Ball query;3)PointNet 提取特征,以每个簇为单位,将簇中的xyz坐标进行局部坐标化后输入到PointNet,提取到的特征不断地拼接到坐标维度的后面。
对于一个set abstraction层,输入是(N,d+C)即N个点,每个点含d维坐标,C维特征;经过最远点采样和组合之后得到N1个中心点,每个簇(邻域)中包含K个点;对于每个簇都用pointnet进行特征提取,将K个点聚合为一个特征,即一个簇对应得到一个特征,N1个簇得到N1个特征,过程中得到的新特征不断拼接到d维坐标信息和之前得到的特征后面,所以输出是(N1,d+C1)。得到的输出再作为下一个set abstraction的输入。
对于分类网络,最后得到的特征直接展平输入全连接层进行分类即可。
对于分割网络,需要做逐点分类,所以有一个上采样的过程,作者把这部分叫做FP(Feature Propagation)——从下采样的点到原始点的特征传播,主要通过插值和跳跃连接来完成,插值这里采用了k个最近邻点的距离倒数加权平均,即如下公式,p和k是经验参数,实验中分别设置为2和3,d()是距离函数。
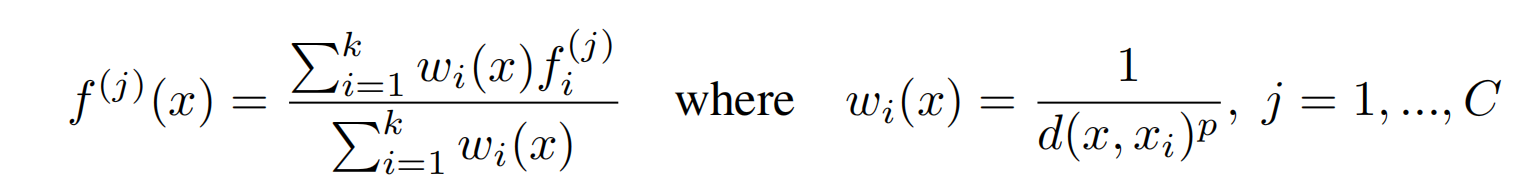
跳跃连接即将前面各个set abstraction层得到的输出的特征与插值后的点的特征进行拼接。其实按照我的理解这个地方称为插值有点不太贴切,实际上是在上采样的过程中,点的xyz位置信息直接就是未采样层的,然后对于未采样层的每一个点,在采样后的点里面寻找最近邻的k个点(k=3),然后利用这k个点的特征按照距离进行加权求和作为未采样层中这个点的特征,所以上采样(插值)后点的特征维度是和未进行上采样之前的特征维度是一样的,比如网络中橙色的上采样层,未进行上采样前特征维度为d+C2,插值后的特征仍为d+C2,然后再拼接上之前的C1,最终得到d+C1+C2。
得到的特征再经过unit pointnet(类似于CNN里面的1*1卷积,只改变特征维度,不改变点的个数,其实就是mlp),重复这个过程,直到将特征传播到原始的点集。
PointNet++:对于非均匀采样密度的鲁棒性
一开始我们就说过PointNet++可以提取到不同尺度的局部特征,这样的特性对于点云来说尤为重要,因为点云在实际的采集过程中不可避免的会产生离传感器近密远疏的现象,点云各个部分的密度不一致。具体就是提出了下面这样两种不同尺度特征融合的方案——MSG和MRG,即设置不同的Ball query半径将提取到的特征进行拼接,或者拼接不同set abstraction层得到的特征,作者把这种具有密度适应性的结构就叫做Pointnet++.

这是作者对比了几种不同结构对于不同的数据密度在分类任务上的表现情况:

其中DP是指对输入的随机Dropout,而”vanilla“这个词还挺有意思,之前也听过类似”香草卷积”这种说法,一般来说,vanilla这个词作形容词的话,可以表示 “常见的;原版的;传统的;一般的”等含义,但其原意是“n.香草;adj.香草味的”,由于冰激凌最常见、最原始的口味就是香草冰激凌,所以才引申出了这个含义,这里面其实还是有一点语言文化的味道。
对比MSG和MRG,前者表现稍好,但由于需要以不同的半径进行邻域选取,然后输入pointnet,所以计算量很大;而后者要做的仅仅是把原来网络中不同层的结果进行拼接,所以计算量要小很多。
语义分割实验:
为了和PointNet进行对比,仍然采用同样的S3DIS数据集进行语义分割,数据集介绍和数据处理部分可以参考上一篇文章,代码也在同一个仓库之中。
同样按照模型文件、数据处理文件、训练文件、测试文件的顺序阅读代码。由于数据处理、训练、测试文件与PointNet基本相同,所以不再赘述,主要看其模型文件。
模型文件:models\pointnet2_utils.py,models\pointnet2_sem_seg_msg.py
在pointnet2pointnet2_utils.py中定义了网络的主要部件PointNetSetAbstractionMsg和PointNetFea- turePropagation以及构建这两个部件需要用到的一些函数:
farthest_point_sample:最远点采样:输入点坐标以及需要采样的点数,返回采样点在输入数据中的索引。对于每个batch,都先随机初始化一个点作为要采样的第一个点,然后建立计算所有点离这个点的距离(包括它本身离自己的距离)的表,不断更新维护这个存储距离信息的表,然后对于任意一个点要判断是否是最远点(是否进行采样),只需比较它和前面已采样点距离的最小值,这个最小值最大的点就是最远点。



比如要判断1和2谁是最远点,比较的距离值是它们各自和前面已采样的点中距离最近的那个点的距离。
index_points输入点数据和索引,取出索引对应的数据。(最远点采样和球邻域查找后返回的都是索引,所以需要这个函数把索引转换为数据)。
query_ball_point球邻域查找:输入半径、每个邻域中的点数、所有点的坐标数据、最远点采样得到的球心坐标数据,返回组合成簇的点的索引。计算每个点到中心点的距离,距离大于给定半径的点统一赋予一个大的索引(如N-1),然后进行排序,这些半径以外的点的索引就会排在后面,然后在前面选取K个点(即距离中心点最近的K个点),如果索引出现N-1(即在半径之外),就把这些点更改为离中心点最近的那个点(即半径内的点不足K就用最近的点替代)。
PointNetSetAbstractionMsg:输入参数为:采样中心点个数、采样半径、每个簇的点数、输入特征维度、mlp各层神经元个数;输出采样后的点及特征。内部包含三个过程:1)FPS最远点采样,得到采样中心点;2)ball query球邻域搜索,以给定半径搜索中心点邻域最近的K个点(不足K个就复制最近的那个点补足);3)PointNet:每个簇输入PointNet,经过mlp和maxpooling ,每个簇的K个点的特征最终聚合为一个特征。
PointNetFeaturePropagation特征传播:输入参数为:输入特征维度,mlp(unit pointnet)各层神经元个数。输出上采样(特征传播)之后的点及特征。内部包含三个过程:1)插值:上采样后的层中点的位置信息就是待上采样层在SA模块中未经下采样的那层的信息,对于每个点去寻找它在采样之后那层中最近的k个点进行加权求出特征(这里的特征是包含xyz这三维的信息的);2)跳跃连接,计算出来的特征拼接上未下采样层原有的特征;3)unit pointnet:即mlp。
models\pointnet2_sem_seg_msg.py定义了模型和损失函数,以
torch.rand(6, 9, 2048) #B C N作为输入举例说明模型结构及各层输入输出情况:

模型训练
仓库里面提供了不采用msg(即ssg)进行训练的预训练模型,可以直接用于测试,但是感觉结果不是太理想,既然论文说了msg和mrg的效果会更好,那何不采用带有msg的模型自己进行训练
python train_semseg.py --model pointnet2_sem_seg_msg --test_area 5 --log_dir pointnet2_sem_seg模型比较大,训练过程batch_size设为32需要11G左右的显存,在Titan X上一个epoch也需要两小时。
模型测试
python test_semseg.py --log_dir pointnet2_sem_seg_msg --test_area 5 --visual自己训练完之后发现结果仍然不是很理想(按道理mIoU至少达到0.5以上),在查看仓库作者的日志时发现即使是采用ssg的方案,测试的mIoU也超过了50%,并且在测试时才发现我的区域5中仅包含67个房间,而实际上数据集中区域5应该包含68个房间(仓库中原有的eval.txt日志也显示有68个房间),没有找到问题的原因。下面是不够理想的最终测试效果,和PointNet几乎差不多。

随意选几个房间进行可视化:
Raw Ground Truth Prediction




