PointNet学习笔记
本文记录了博主在学习《PointNet: Deep Learning on Point Sets for 3D Clasification and Segmentation》过程中的总结笔记。更新于2018.10.12。
文章目录
Introduction
网络输入:点云输据(point clouds);
网络输出:将输入视作一个整体的标签,或输入内每个分割部分(segment/part)的标签。
每个点的基本描述是其坐标 ,当然也可以加上均值及其他局部或全局特征。
网络的前一部分学习的是提取兴趣点或信息点,并将选择它们的原因形成编码;后面的全连接层则用于整合这些信息,实现分类或分割。
另外,由于网络的输入是点云数据(每个点之间是独立的),因此可以尝试用一个空间转换器(spatial transformer network)规范化数据。
论文中证明了所提网络可以模拟任何连续函数。通过实验发现,网络会用一组稀疏的关键点总结描述输入点云,可视化后发现,这些点恰巧也是目标图形的骨架(skeleton)。
此外,论文中也从插点(outliers)和删点(missing data)的角度证明了为何网络对于输入的小扰动鲁棒。
网络对于形状分类、部分分割、场景分割等任务(数据库下)都有较好的表现。
问题描述
用 描述一个3D点云,其中每一个点 都是一个向量。在本文中,除非特殊描述,其通道只包括位置信息 。
对于分类问题,网络输出对应 个类别的 个概率;对于分割问题,网络则输出所有 个点对于所有 个语义类别的的概率,即输出尺寸为 。
Deep Learning on Point Sets
网络结构的提出是受到了 内点云的性质的启发,因此第一部分介绍性质,第二部分介绍网络结构。
点云数据的性质
网络的输入是欧氏空间下的一个点的子集,因此具有下面三个主要性质:
- 无序性(Unordered):与像素点阵或三维点阵下排布的网格状数据不同,此时的点云是无序的。因此要求一个以 个3D点为输入的网络需要对数据的 排布具有不变性(invariant to permutations of the input set in data feeding order)。
- 点之间有关系(interaction among points):由于这些点是空间中一个有意义的子集里面按照某种距离矩阵生成的,这就要求网络要有能力识别这些相邻点之间的局部结构和这些结构的组合。
- 平移不变性(invariance under transformations):习得的点云描述应当对于某些变换鲁棒,比如在点云整体平移和旋转等变换下,网络对于点云的分割和分类结果不应当改变。
PointNet网络结构
下图是网络的整体结构(分割和分类网络共享大部分网络),包括用于整合所有点信息的对称函数max pooling、一个局部和全局信息整合结构,和两个连结结构用于连结输入点和点特征。
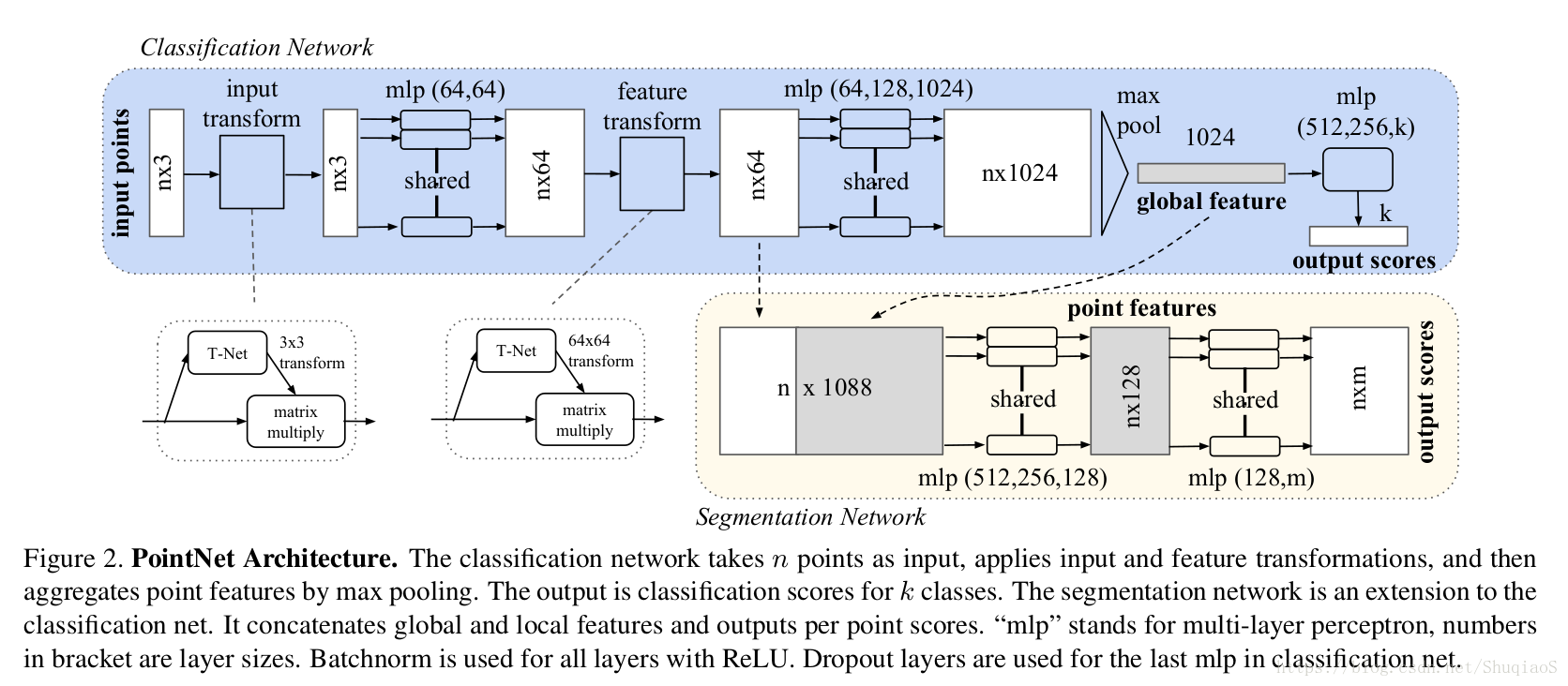
Symmetry Function for Unordered Input
目前存在三种方法保证模型对于输入不同排序具有不变性:
- 将输入归类为一个规范化的顺序(canonical order);
- 在训练RNN时将数据视为一个序列,但对训练数据以所有可能的排序进行扩张;
- 应用一个简单的对称函数整合每个点的信息:此时,对称函数以 个向量为输入,输出一个对于输入顺序具有不变性的新向量(例如+和*操作都属于二值对称函数symmetric binary function)。
尽管第一种方法看起来很简单,但实际上不难证明是无法找到一种高维下的排序使得其对于扰动鲁棒的。这种方法比直接用无序输入会稍微好一点,但表现还是很差。此外,对于第二种方法,尽管其对于小长度(几十)的序列具有鲁棒性,但对于上千个点(点云的通常大小)就无法得到相同的表现了。文中的实验证明了PointNet所使用的方法更好。
文中希望通过对变换后的元素应用对称函数,从而估计得到一个定义在点集上的一般函数(general function):
其中,
,
,对称函数
。
文章通过实验确定的基本模型用多层感知机(multi-layer perceptron)习得 ,用一个单变量函数(single variable function)和max pooling函数习得 。通过不同的 ,可以习得表征不同属性的多个 。
博主注:
- 所谓多个 :这里的理解就像当一组点具有某种不同属性时,其组成的整体也可以根据这些属性得到可能的属性。如大部分的点都是黑的,那么整体的颜色属性就是黑色;再如点与点之间存在某种位置关系,那么整体就是球形;以此类推……。而这里的 就代表了不同考量下得到的属性结论,而 要近似的也是这种结论,只不过 并非直接考量输入的各个点,而是这些点经过 处理后的体现。这就使得不同的 处理出来经过相同的考量,也会对应不同的属性结论,即不同的 。
- 为什么可以有这个近似:因为如果直接以原始点为输入,那么对于点的排序就有要求。而通过之前的分析,是很难找到一种方法使得结果不受顺序的影响。而这里用于近似的函数 是一个对称函数,也就是其不考虑输入的顺序,只要保证需要的输入都进来了,就可以了。然而,在原始特征空间下,这种不考虑顺序的行为是无法实现的,因此需要一种映射,将原始数据映射到一个新的空间,使得在该空间下,数据的顺序(相互之间的关系)已经以某种形式表征出来,从而使得接下来的操作不需要考虑顺序。
局部和全局信息整合(Local and Global Information Aggregation)
上面一步的输出是一个表征了全局特征的向量 。对于分类问题,可以直接训练一个SVM或多层感知机分类器,用于在给定全局特征向量的基础上判断类别(比如黑色、球体等等得到“眼睛”);但是对于点的分割问题,就需要统筹考虑全局和局部特征了。文章的做法是将获得的全局特征级联在每个点的局部特征后面(如上图中分割部分所示),在此基础上再学习得到新的点局部特征,此时的每个点的特征就既包含局部特征(局部几何信息)又包含全局特征(全局语义)了。
Joint Alignment network
一个点云的语义标签应当对于部分变换(如刚体变换rigid transformation)具有不变性。因此,应当要求习得的点云描述也对于这些变换具有不变性。
一个比较典型的做法是在提取特征之前将所有输入集合整合到一个标准化空间(canonical space)内。与之前存在的工作(原文参考文献9)不同,文章中的做法不需要发明任何新的层,也不需要引入任何别名(alias)。论文中应用了一个迷你网络T-Net学习一个仿射变换,并将其直接应用到原始点云坐标系。
T-Net是作为整个网络的一部分存在的,其中包括点独立特征提取(point independent feature extraction)、max pooling、和全连接层。关于T-Net的详细信息可以看支撑材料的学习。
同样的思想也可以用于特征空间,即用于整合不同点云得到的特征。然而,由于特征空间下的变换矩阵维度要远远高于原始空间,为了降低最优化的难度,文章作者在softmax训练损失的基础上加了一个正则项:
其中
是迷你网络习得的特征整合矩阵。该正则项要求学习得到的矩阵是正交矩阵,因为正交变换不会丢失输入的信息。
理论分析
1. 万能近似(Universal approximation)
博主注:虽然神经网络的主要运算层进行的都是线性运算,但我们无需为了期望的到的非线性函数单独设计需要的模型。万能近似定理(Universal approximation theorem)(Hornik et al., 1989;Cybenko, 1989) 表明,一个前馈神经网络如果具有线性输出层和至少一层具有任何一种‘‘挤压’’ 性质的激活函数(例如logistic sigmoid激活函数)的隐藏层,只要给予网络足够数量的隐藏单元,它可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的Borel 可测函数。
万能近似定理意味着无论我们试图学习什么函数,我们知道一个大的MLP 一定能够表示这个函数。然而,我们不能保证训练算法能够学得这个函数。即使MLP能够表示该函数,学习也可能因两个不同的原因而失败。
- 用于训练的优化算法可能找不到用于期望函数的参数值。
- 训练算法可能由于过拟合而选择了错误的函数。
根据‘‘没有免费的午餐’’ 定理,说明了没有普遍优越的机器学习算法。前馈网络提供了表示函数的万能系统,在这种意义上,给定一个函数,存在一个前馈网络能够近似该函数。但不存在万能的过程既能够验证训练集上的特殊样本,又能够选择一个函数来扩展到训练集上没有的点。
总之,具有单层的前馈网络足以表示任何函数,但是网络层可能大得不可实现,并且可能无法正确地学习和泛化。在很多情况下,使用更深的模型能够减少表示期望函数所需的单元的数量,并且可以减少泛化误差。
这里文章作者证明了网络拟合任意连续函数的万能近似能力。直观上,由于集合函数(set function)的连续性,一个输入点集中的小扰动不太可能极大地改变函数的数值(如分类或分割score)。正式分析: 令 , 是一个 上对Hausdroff距离 连续的集合函数,即 , 使得对于任意 ,若 ,都有 。下面的理论证明,只要max pooling层输入的神经元个数足够多(也就是公式(1)中的 足够大),PointNet神经网络就可以随机近似任意 。
Theorem 1. 假设
是一个对于Hausdorff距离
连续的集合函数。
,
一个连续函数
和一个对称函数
,使得对于任意
有
其中
是
中所有元素的列表(随机排列),
是一个连续函数,
是一个向量最大算子(输入
个向量,其返回一个包含element-wise最大值的向量)。
博主注: 其中 是映射乘法,也就是应用了映射 后的结果再应用映射 。关于Theorem的证明可以在支撑材料中找到。
这个理论显示,在最坏的情况下,网络也会将空间等分成voxel以描述输入。然而,实验显示,网络的学习结果要比这个好很多。
2. Bottleneck dimension and stability.
实验和理论标明,PointNet的表现严重受到max pooling层维度的影响(也就是公式(1)中的 )。作者在这一部分给出了分析,同时也揭示了网络模型与稳定性相关的性质。
定义 为 的子网络,用于将 的点集映射成一个K维的向量。下面的定理证明了输入集合中的小扰动或多余的噪声点不太可能影响网络的结果:
Theorem 2. 假设 且 , 。那么:
上面的定理说明:(a)说明只要输入中存在的扰动没有影响到 中的点,或者加入噪声点后不超过 ,那么 就不变;(b)说明 只包含有限个点,且点的个数由公式(1)中的 决定。总的说来,也就是 实际上完全由一个有限的子集 决定,且子集中元素的个数不超过 个。
因此,称 是 的关键点集, 是 的瓶颈维度(bottleneck dimension)。
结合 的连续性,就可以解释模型对于点的扰动、损坏、额外噪声点的鲁棒性(参考机器学习中的稀疏性原理)。直观上来看,网络学习了如何通过一组稀疏的关键点组成的集合总结一个形状。实验标明,这组关键点恰好组成了一个目标的骨架。
支撑材料C
支撑材料C为网络结构和训练细节。
PointNet分类网络
由于主体的网络结构已经在正文中说过了,这一部分主要介绍joint alignment/transformation网络以及网络训练细节。
注:这里的变换网络其实就是前面提到的T-Net
第一个变换网络(transformation network)是一个mini-PointNet,其直接以未处理的点云为输入,并回归成一个
的矩阵。这个网络由一个每个点共享的MLP(层输出尺寸分别为64, 128, 1024)、一个点间max pooling、和两个全连接层(层输出尺寸分别为512, 256)组成。输出矩阵初始值为单位阵(identity matrix)。除了最后一层,其余所有层都应用了ReLU和Batch Normalization。
第二个变换网络与第一个结构相同,除了输出矩阵尺寸为
。输出矩阵也被初始化为单位阵。
在softmax clssification的基础上增加了正则损失(regularization loss,权重0.001)以约束输出尽量为正交矩阵。
训练时,在估计类别概率前,对最后一层全连接层(维度256)应用了keep ratio 为0.7的dropout。Batch Normalization的衰减率(decay rate)从初始的0.5逐渐增加到0.99。用adam优化方法,初始学习率0.001,动量(momentum)0.9,batch size 32。学习率每迭代20次下降一半。
在TensorFlow下用GTX1080 GPU和ModelNet数据集训练,网络需要3-6个小时收敛。
PointNet分割网络
分割网络是分类网络的一个延伸。
局部点特征(应用第二个变换网络后的结果)和全局特征(max pooling的输出)按每个点级联。在分割网络中不应用dropout。训练参数与分类网络相同。
对于形状部分分割任务(shape part segmentation),作者对基础网络结构做了一定的调整以实现更好的结果。他们增加了一个one-hot向量(指示输入的类别)并将其与max pooling层的输出级联。他们还增加了某些层的神经元个数和skip links以获取不同层对应的特征,并将这些特征级联作为分割网络的输入。具体网络结构如下图所示。
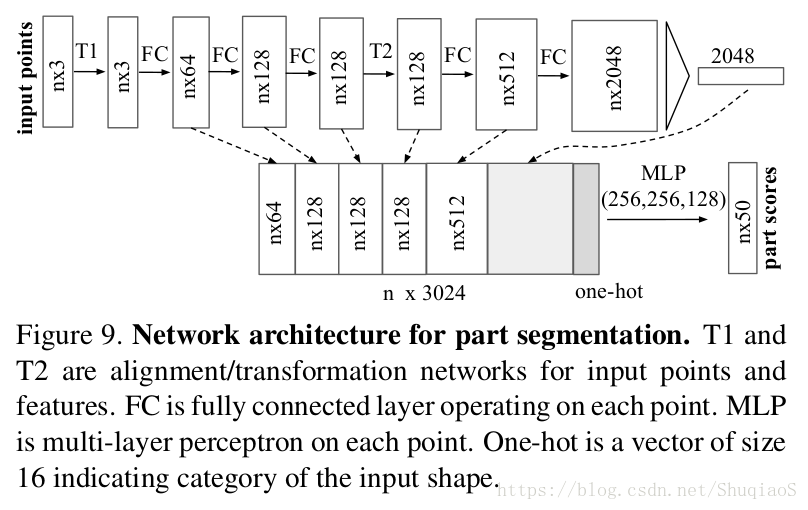
对于语义学分割(semantic segmentation)任务,应用的是与论文主体中相同的基本网络结构(Figure 2)。
用ShapeNet part 数据集训练需要大约6-12小时,Stanford semantic parsing数据集训练大概需要半天。
基准3D CNN分割网络
在ShapeNet part分割实验中,作者将所提网络与另外两个传统方法和一个3D volumetric CNN网络(如下图)做比较。给定一个点云,作者首先将其转化成分辨率为 的占用率网格(occupancy grid)形式的体积描述,再根据图中所示一步步实现。
