基础概念
1.few-shot learing(少样本学习):意思是用少量带标签的样本来训练就得到一个好的模型去做分类或回归任务
2.few-shot learning是一种meta learning(元学习),它的目标是learn to learn,即让计算机自己学会学习。用一个通俗的意思来解释meta learning,当我们带小朋友去动物园时,小朋友见到了一个不认识的动物,但是他具备自主学习能力,因此我们把几个带有名字标签的图片拿给小朋友看,让他自己去学习,小朋友通过比较知道了眼前的这只动物是什么。培养计算机自主学习的过程就是meta learning。

3.Support Set:meta learning中的术语,指很小的样本集,不足以训练大的神经网络,只能在预测时提供一些参考信息。Support Set与训练集不同,训练集很大,足以训练神经网络。
4.query:要预测的图片
传统的监督学习 vs Few-Shot Learning
传统的监督学习的目标通过训练集训练模型,使经过训练的模型对新样本能正确识别。比如模型判断一张哈士奇的图片,虽然训练集没有这张图片,但是有其他上百张哈士奇的图片,模型很容易就能判断这是哈士奇。

few-shot learning的目标是让机器学会学习,判断事物的异同,区分不同的事物。(理解两图片是否相同)
我拿一个很大的数据集来训练神经网络模型,学习的目的并不是让模型识别没见过的图片,而是比较图片的异同。
给两张图片,模型能够识别两张图片是相同还是不同的,而不是让模型识别出图片是什么。
比如这两张图片是一个动物吗?

即使训练集中并没有松鼠这个类别,不能识别图片是什么,但是模型已经学会了判断事物的异同,所以模型通过比较知道这两张图片的动物长得很像,所以模型会预测两张图片很有可能是一个动物。
再比如,模型既没有见过这张兔子的图片,甚至在训练集也没见过任何其他兔子的图片,我们需要给模型提供参考信息Support set,通过将图片与Support set中的图片比对,预测结果,判断这是一只兔子
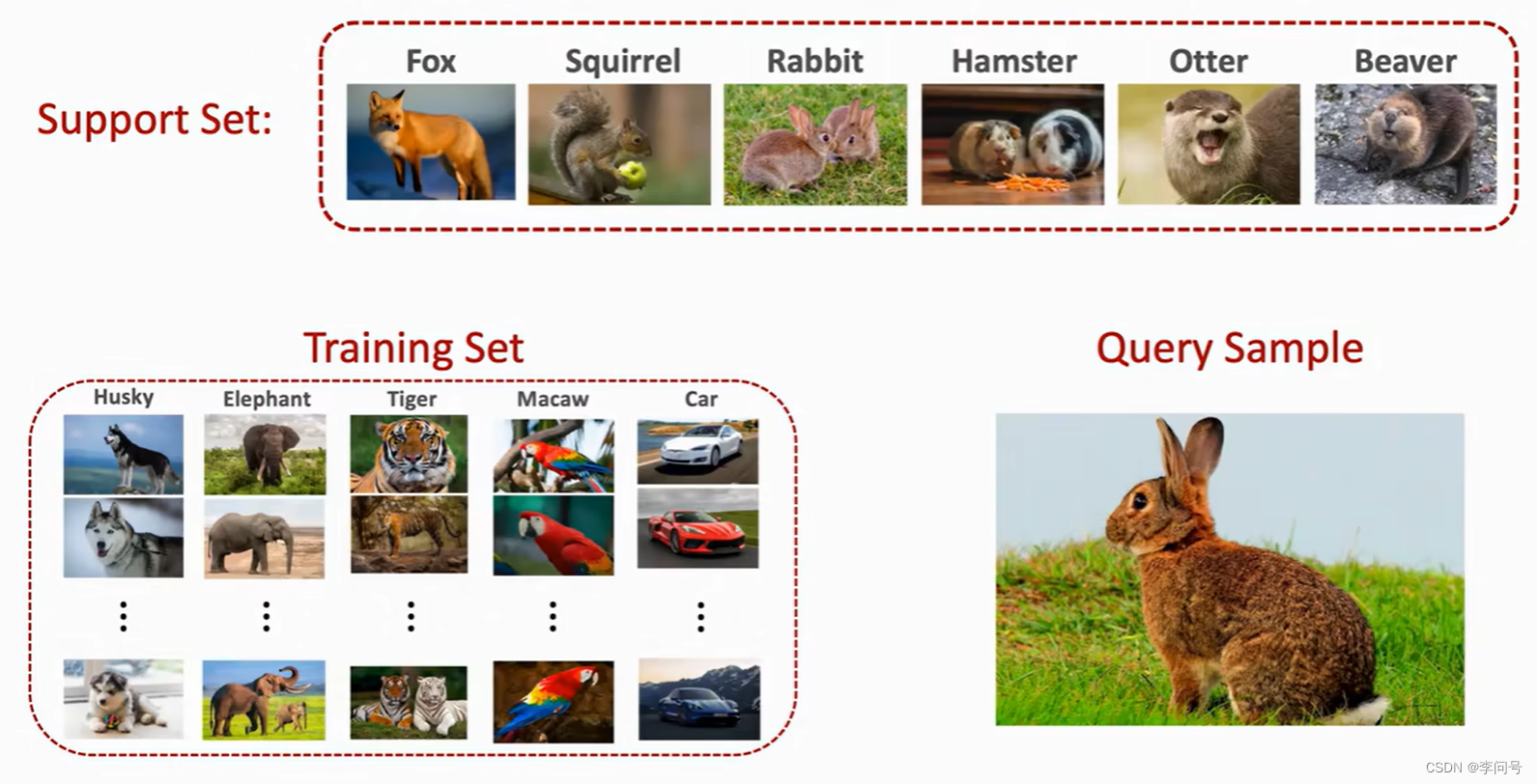
Support Set
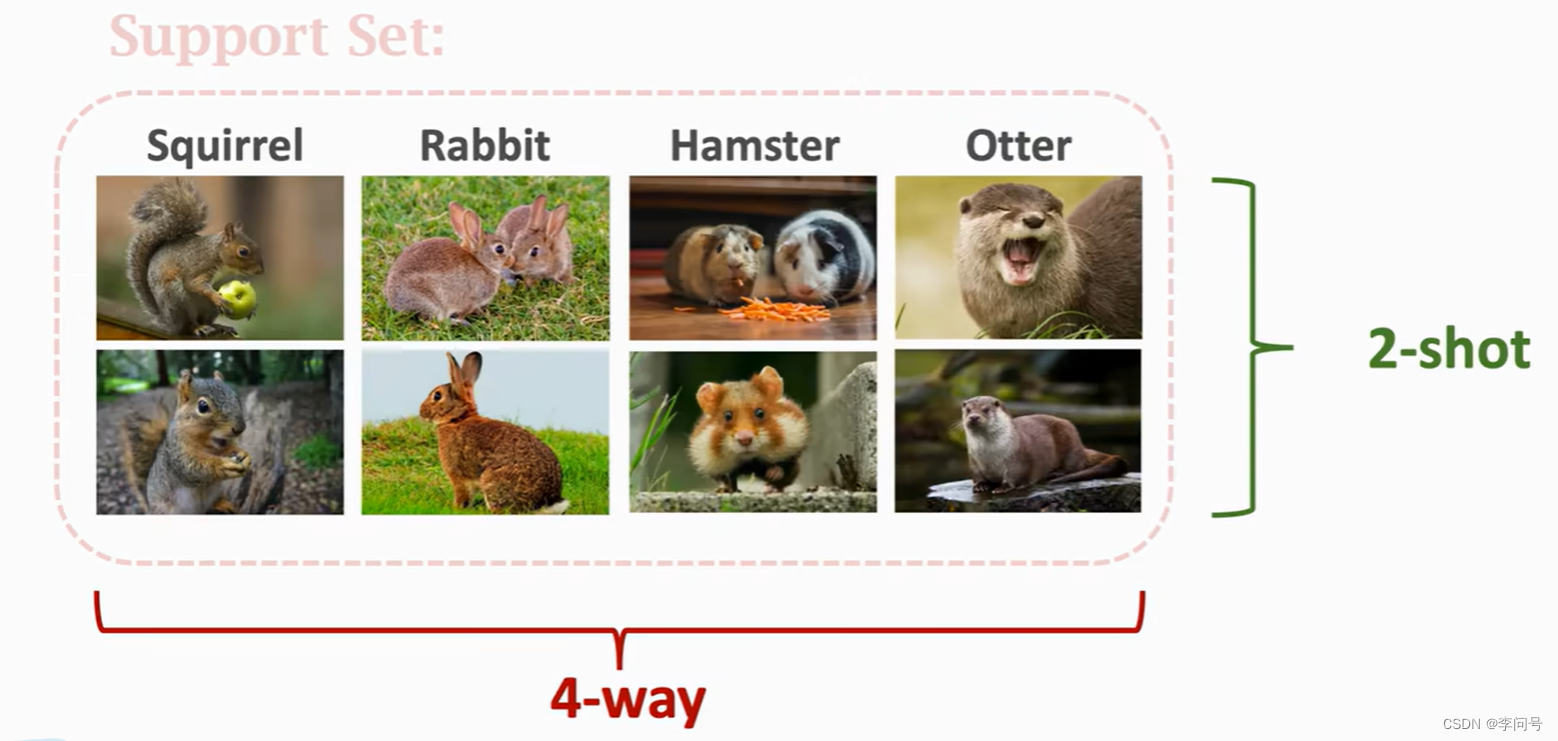
k-way n-shot Support Set
(1) k-way:Support Set中有k个类别
(2) n-shot:每个类别有n个样本
6-way 1-shot Support Set:

4-way 2-shot Support Set:
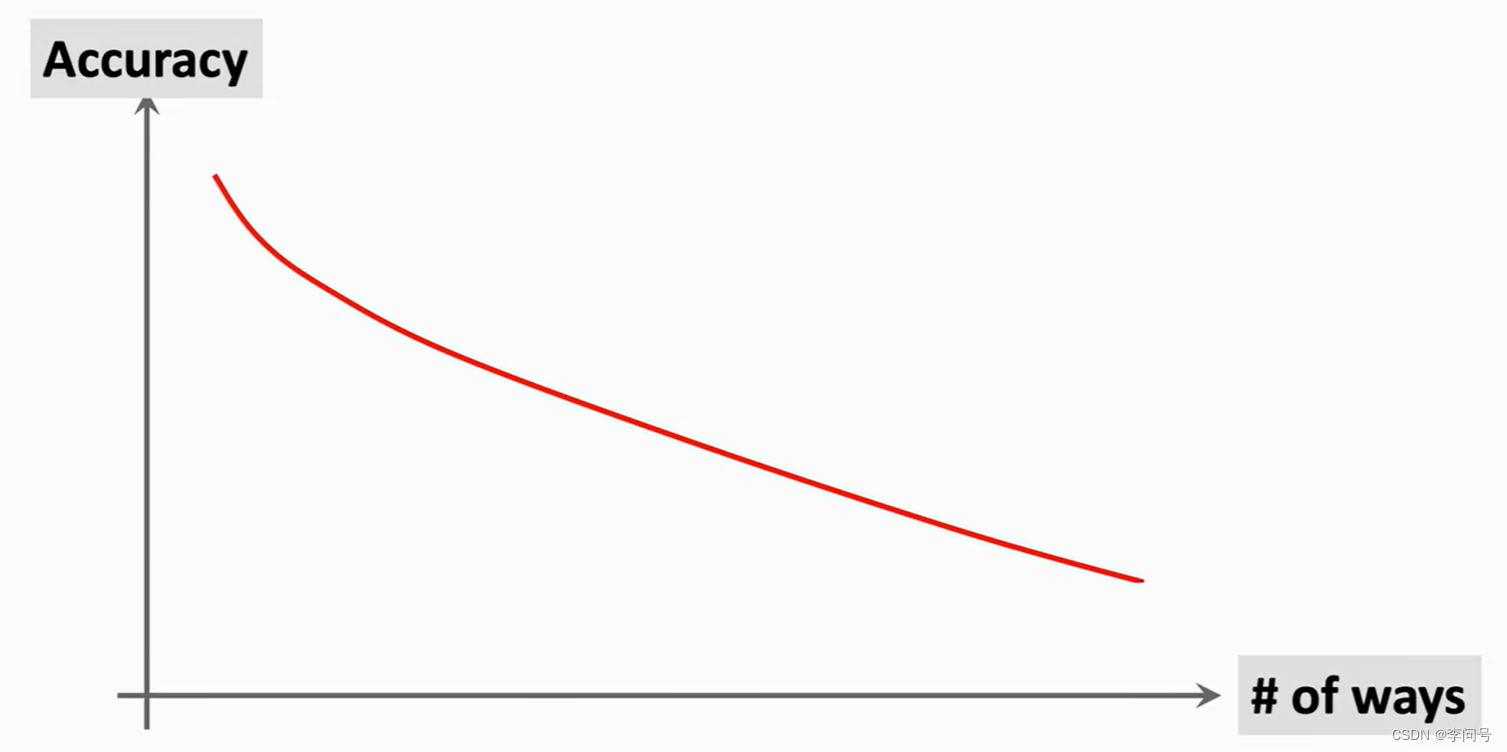
few-shot 分类的预测准确率受到类别数和样本数的影响
准确率随着类别数增加而降低
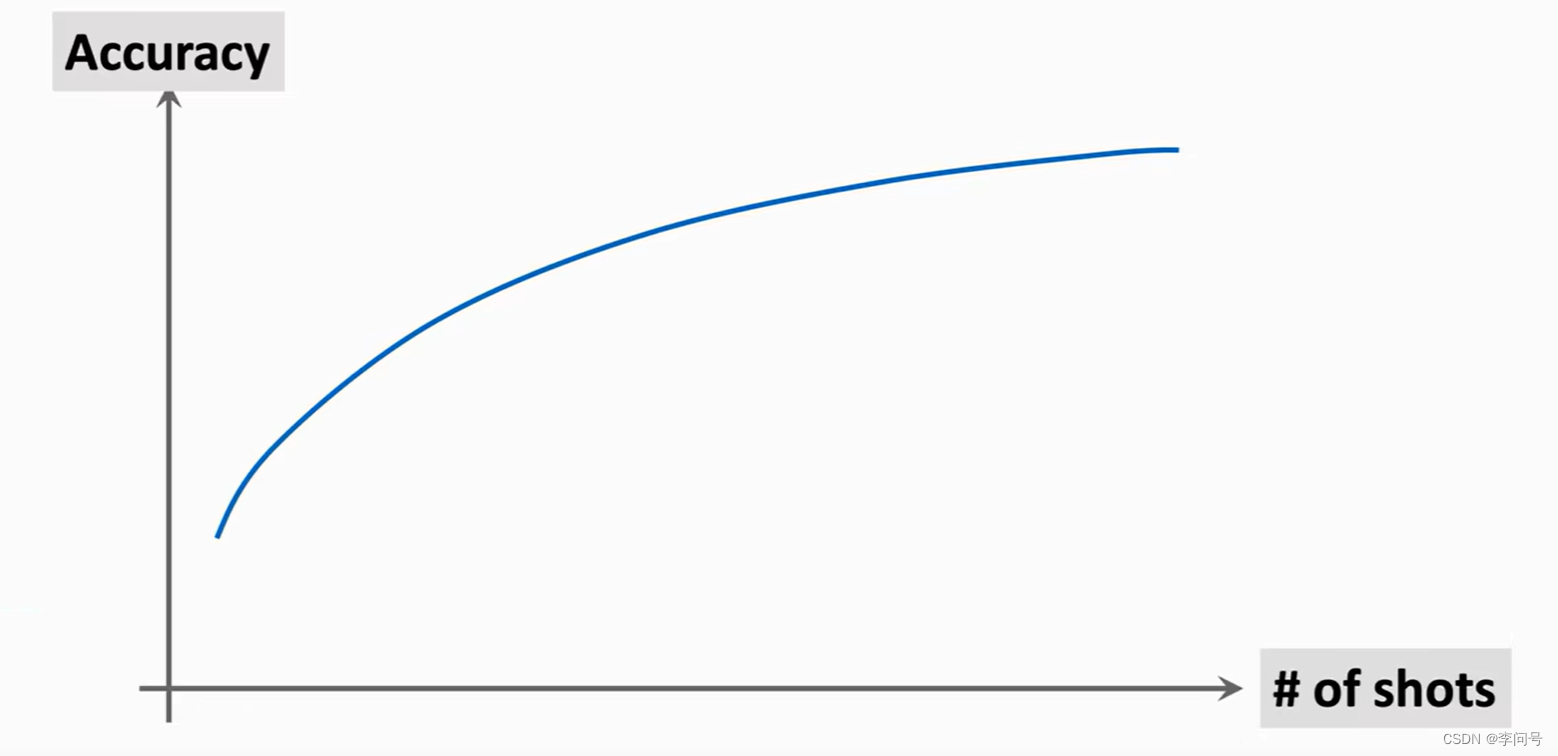
准确率随着样本数增加而增加
实现原理
few-shot learning最基本的想法就是学习一个函数来判断相似度,把函数记为sim(x1,x2),两个事物x1,x2的相似度越高表明两者越相似。
具体步骤
1.从一个大训练集中学习一个相似度函数,可以判断两张图片的相似度。
2.应用相似度函数做预测。
3.对比query和support set中每个样本的相似度
4.找出相似度最高的作为预测结果。

数据集
如果做meta learning的研究,需要用一些标准数据集来评价模型的表现,在此介绍两个在论文中总能看到常用的数据集。
Omniglot
Omniglot是手写字体数据集,这个数据集不大,只有几兆,很适合学术界使用。
数据集下载链接:https://github.com/brendenlake/omniglot

(1)数据集包括50种不同的字母表,包括希伯来字母,希腊字母等。
(2)数据集一共有1623个不同的字母,每个字母是一个类别,每一个类别有20个不同的手写样本。
(3)每个样本是105×105的图像
(4)训练集有30个字母表,964个字符和19280个样本
(5)测试集有20个字母表,659个字符和13180个样本
Mini-ImageNet
Mini-ImageNet一共有100个类,每个类有600个样本