评价方法大体上可分为两类,其主要区别在确定权重的方法上。一类是主观赋权法,多数采取综合咨询评分确定权重,如综合指数法、模糊综合评判法层次分析法、功效系数法等。另一类是客观赋权,根据各指标间相关关系或各指标值变异程度来确定权数,如主成分分析法、因子分析法、理想解法(也称TOPSIS 法)等。
目前国内外综合评价方法有数十种之多,其中主要使用的评价方法有主成分分析法、因子析、TOPSIS秩和比法、灰色关联法、权法、层次分析法、糊评价法、物元分析法、聚类分析法、价值工程法、神经网络法等。
理想解法

1.1方法和原理


用理想解法求解多属性决策问题的概念简单,只要在属性空间定义适当的距离测度就能计算备选方案与理想解的距离。TOPSIS 法所用的是欧民距离。至于既用正理想解又用负理想解是因为在仅仅使用正理想解时有时会出现某两个备选方案与正理想解的距离相同的情况为了区分这两个方案的优劣,引入负理想解并计算这两个方案与负理想解的距离,与正理想解的距离相同的方案离负理想解远者为优
1.2TOPSIS法的算法步骤
以下是步骤的大致介绍,更够等好的理解整个算法的流程
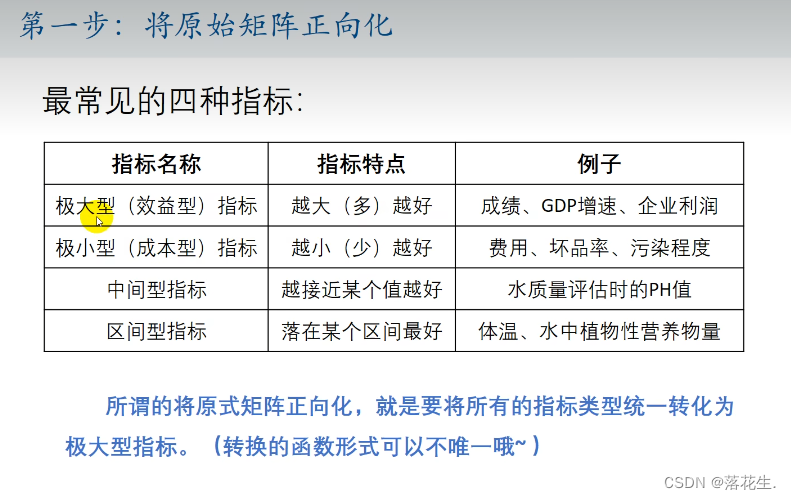
有些时候正向化的步骤会省略,这时,在后面处理成本型的数据时,就需要去取最小值。
拿到数据之后要先处理成本型数据和区间型数据
为了消去不同指标量纲的影响,需要对已经正向化的矩阵进行标准化处理


另一种表达方式如下




数据预处理数据的预处理又称属性值的规范化(不是正向化,更像是标准化)
在进行决策时,一般要进行属性值的规范化,主要有如下三个作用:
(1) 属性值有多种类型,上述三种属性放在同一个表中不便于直接从数值大小判断方案的优劣,因此需要对数据进行预处理,使得表中任一属性下性能越优的方案变换后的属性值越大。
(2)量化,多属性决策与评估的难之一是属性间的不可公度性,即在属性值表中的每一列数具有不同的单位(量纲)。即使对同一属性,采用不同的计量单位,表中的数值也就不同。在用各种多属性决策方法进行分析评价时,需要排除量纲的选用对决策或评估结果的影响,这就是非量纲化。
(3)归一化,属性值表中不同指标的属性值的数值大小差别很大,为了直观,更为了便于采用各种多属性决策与评估方法进行评价,需要把属性值表中的数值归一化,即把表中数值均变换到[0,1]区间上。
常见的属性规范化方法



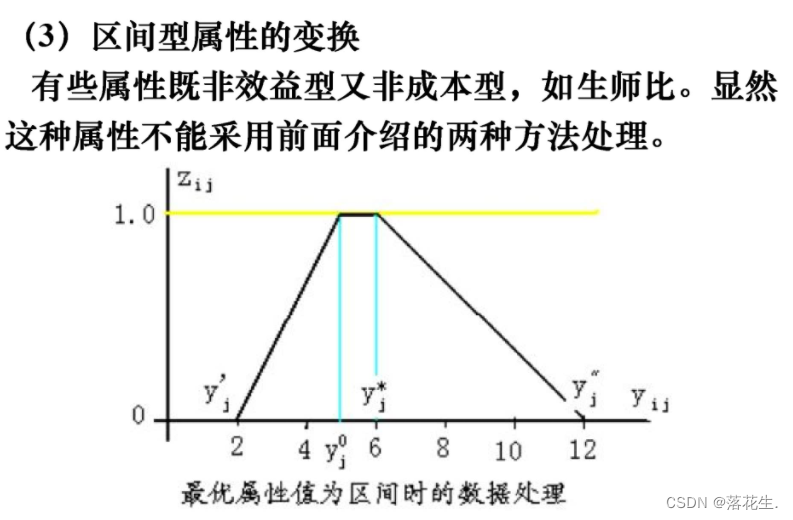


区间数据或者是成本数据一定要先利用转换方法转换成效益数据,然后再进行规范化处理。即先一致化再规范化。
向量规范化不适合区间型数据。
向量规范化对于效益型来说使用PPT上的bij即可。
对于成本型bij*=1-bij

例子

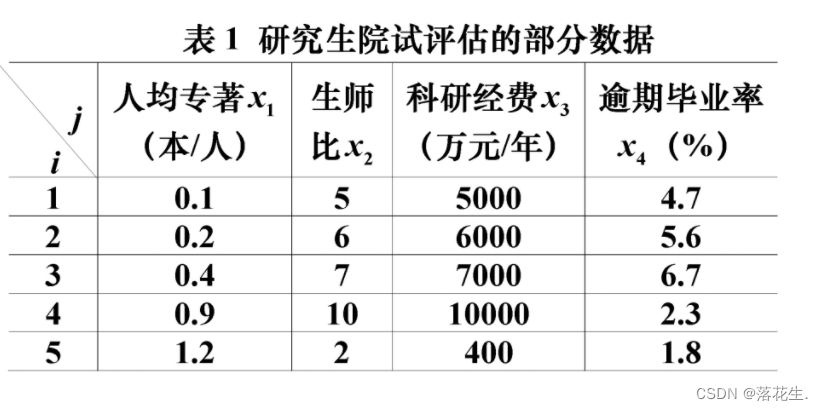
先处理区间数据师生比
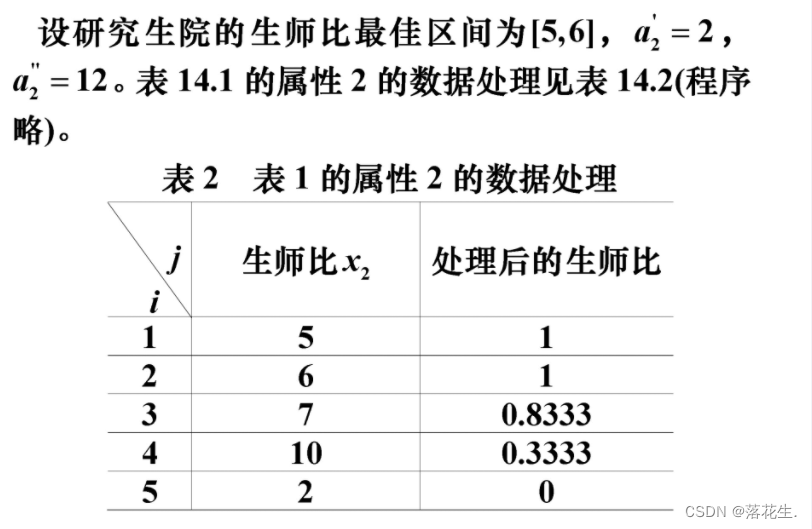
按照区间型属性的变换规则公式12进行编码
x2=@(qujian,lb,ub,x)(1-(qujian(1)-x)./(qujian(1)-lb)).*(x>=lb&x<qujian(1))+...
(x>=qujian(1)&x<=qujian(2))+(1-(x-qujian(2))./(ub-qujian(2))).*...
(x>qujian(2)&x<=ub);
%当在此区间时此区间为1,其他区间为0。此点乘其此作用
qujian=[5,6];lb=2;ub=12;%定义最优区间,最大最小值。
x2data=[5 6 7 10 2]';%x2的输入值
y2=x2(qujian,lb,ub,x2data)%输出数据

下面是整体代码
a=[0.1 5 5000 4.7
0.2 6 6000 5.6
0.4 7 7000 6.7
0.9 10 10000 2.3
1.2 2 400 1.8];
[m,n]=size(a);
%第一步,对区间属性的数据进行预处理
x2=@(qujian,lb,ub,x)(1-(qujian(1)-x)./(qujian(1)-lb)).*(x>=lb&x<qujian(1))+...
(x>=qujian(1)&x<=qujian(2))+(1-(x-qujian(2))./(ub-qujian(2))).*...
(x>qujian(2)&x<=ub);%分段函数的表达
qujian=[5,6];lb=2;ub=12;
a(:,2)=x2(qujian,lb,ub,a(:,2))%对属性2进行变换
%第二步:设置权向量,并得到加权向量规范化矩阵
for j=1:n
b(:,j)=a(:,j)/norm(a(:,j));%向量规范化。
end
w=[0.2 0.3 0.4 0.1];
c=b.*repmat(w,m,1);%求加权矩阵
%第三步求正理想解和负理想解
cstar=max(c);%求正理想解
cstar(4)=min(c(:,4))%属性4为成本型,正理想解成本型取最小值
c0=min(c);%求负理想解
c0(4)=max(c(:,4))%属性4为成本型的,负理想解成本型取最大值
% 第四步
for i=1:m
sstar(i)=norm(c(i,:)-cstar);%求到正理想解的距离
s0(i)=norm(c(i,:)-c0);%求到负理想解的距离
end
%第五步
f=s0./(sstar+s0);%求得分结果
[sf,ind]=sort(f,'descend')
%"ascend"时,进行升序排序,为"descend"时,进行降序排序
第一步以后得到的结果
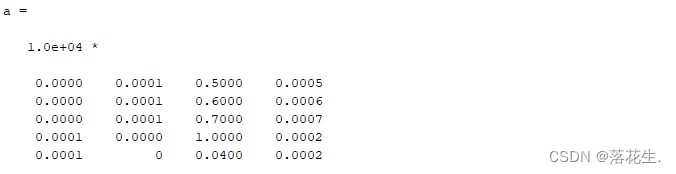
这里为什么和上面单独运行的代码差别这么大?
此时这个数据只是在显示时进行了进位估算,点击工作区的a文件可以得到一下结果
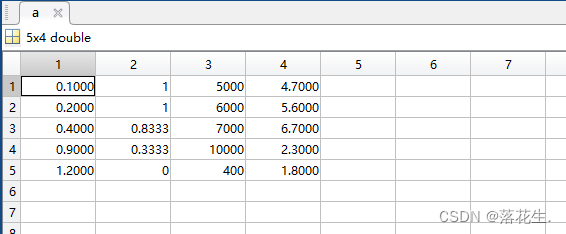
第二步运行得到结果
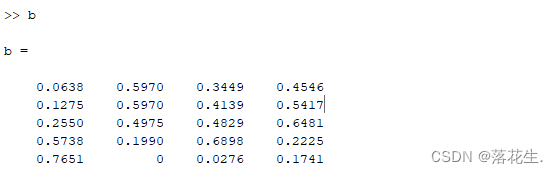
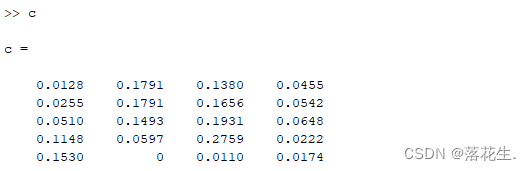
第三步的结果
正理想解cstar

负理想解c0

第四步
到正理想解的距离sstar

到负理想解的距离s0
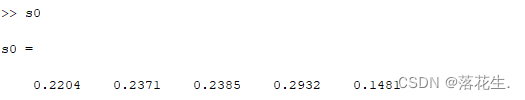
第五步
求得分结果

最后结果
得分和排序

部分代码释义
norm 向量范数和矩阵范数

repmat 重复数组副本。详情见帮助
垂直堆叠行向量四次。
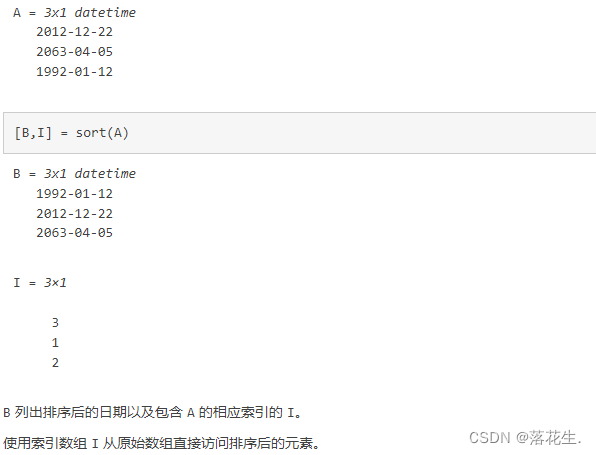
sort 对数组元素排序
[B,I] = sort(___) 还会为上述任意语法返回一个索引向量的集合。I 的大小与 A 的大小相同,它描述了 A 的元素沿已排序的维度在 B 中的排列情况。例如,如果 A 是一个向量,则 B = A(I)。