Topsis法,全称为Technique for Order Preference by Similarity to an Ideal Solution中文常翻译为优劣解距离法,该方法能够根据现有的数据,对个体进行评价排序。根据有限个评价对象与理想化目标的接近程度进行排序的方法,是在现有的对象中进行相对优劣的评价。
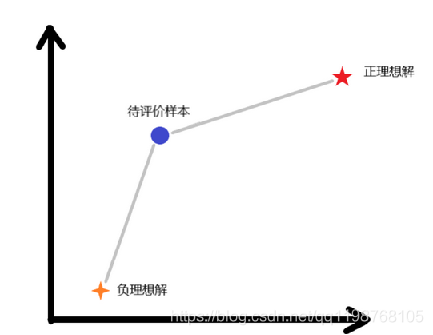
引入一个实际例子来理解一下:
例题:下表是5位同学身体相关参数,请用TOPSIS法来对同学身体情况进行一个综合的评价
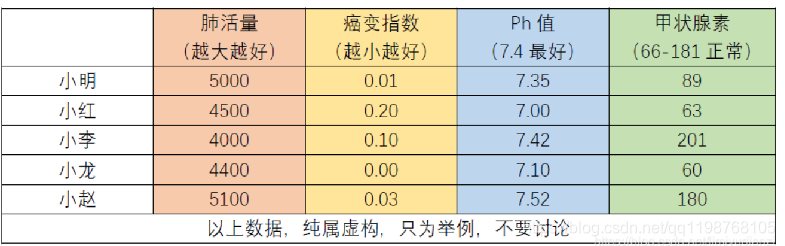
注意到,上面四个指标方向并不相同
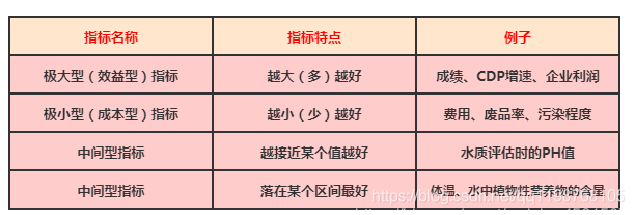
需要对不同指标进行正向化:
1、极小型指标
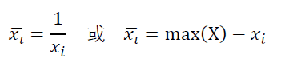
2、中间型指标
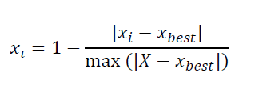
3、区间型指标
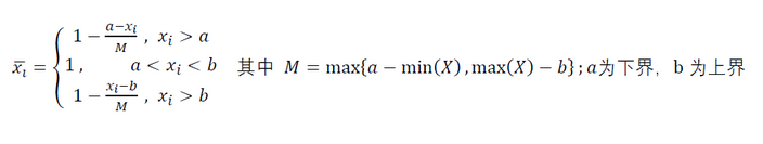
因为不同特征的量纲不同,之后需要对指标进行标准化
最优、最劣方案集的确定:
1、一方面看是否该决策因素本身有限定值,要符合现实意义
2、如果没有或者难以找到,就在所有评价集中找到MAX与MIN值
计算距离:
1、正向距离公式:
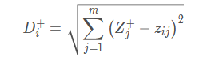
2、负向距离公式:
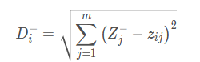
3、评价指标值:
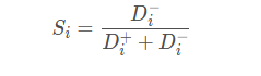
以小明为例计算评价指标值:
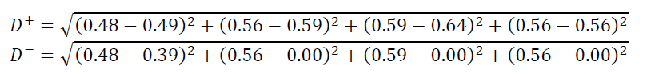

进一步拓展:
上例中的计算,是默认评价因素之间重要程度相同,往往实际中并非如此,各个因素之间有重要程度之别。如何去给每个因素设置重要程度呢?
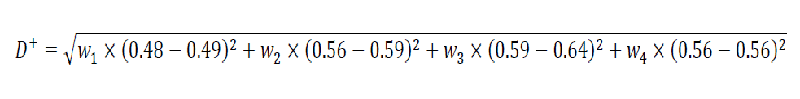
权重通过AHP或熵权法确定
(本专栏第三篇介绍过EXCEL的熵权法)
matlab:熵权法结合TOPSIS
%基于熵权法对于TOPSIS的修正
clear;clc;
load X.mat;
%获取行数列数
r = size(X,1);
c = size(X,2);
%首先,把我们的原始指标矩阵正向化
%第二列中间型--->极大型
middle = input("请输入最佳的中间值:");
M = max(abs(X(:,2)-middle));
for i=1:r
X(i,2) = 1-abs(X(i,2)-middle)/M;
end
%第三列极小型--->极大型
max_value = max(X(:,3));
X(:,3) = abs(X(:,3)-max_value);
%第四列区间型--->极大型
a = input("请输入区间的下界:");
b = input("请输入区间的下界:");
M = max(a-min(X(:,4)),max(X(:,4))-b);
for i=1:r
if (X(i,4)<a)
X(i,4) = 1-(a-X(i,4))/M;
elseif (X(i,4)<=b&&X(i,4)>=a)
X(i,4) = 1;
else
X(i,4) = 1-(X(i,4)-b)/M;
end
end
disp("正向化后的矩阵为:");
disp(X);
%然后对正向化后的矩阵进行熵权法赋权重
tempX = X; %代替X进行计算的辅助变量,避免X受到影响而发生改变
%测试:tempX = [1,2,3;-1,0,-6;5,-3,2];
%标准化矩阵,消除负数项,并且把数值控制在0-1区间
min = min(tempX);
max = max(tempX);
min = repmat(min,size(tempX,1),1);
max = repmat(max,size(tempX,1),1);
tempX = (tempX-min)./(max-min);
%求出矩阵的概率矩阵,即能取到该值的概率
sumX = repmat(sum(tempX),size(tempX,1),1);
pX = tempX./sumX;
%求出信息熵矩阵,信息熵越大,能获得的信息就越少
temp = pX.*mylog(pX);
n = size(tempX,1);
sum1 = sum(temp);
eX = sum1.*(-1/log(n));
%求出信息效用值
dX = 1-eX;
%求出每个指标的熵权
wX = dX./(sum(dX));
%打印输出
disp("每个指标依次的熵权为:");
disp(wX);
熵值法:
function [W] = Entropy_Method(Z)
% 计算有n个样本,m个指标的样本所对应的的熵权
% 输入
% Z : n*m的矩阵(要经过正向化和标准化处理,且元素中不存在负数)
% 输出
% W:熵权,m*1的行向量
%% 计算熵权
[n,m] = size(Z);
D = zeros(1,m); % 初始化保存信息效用值的行向量
for i = 1:m
x = Z(:,i); % 取出第i列的指标
p = x / sum(x);
% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以这里我们自己定义一个函数
e = -sum(p .* mylog(p)) / log(n); % 计算信息熵
D(i) = 1- e; % 计算信息效用值
end
W = D ./ sum(D); % 将信息效用值归一化,得到权重
end