参考博客:点击打开链接
KNN理论成熟,是最简单的机器学习方法之一,可以用它来实现分类和回归,是监督学习方法之一。
假设每一个样本有m个特征值,则一个样本的可以用一个m维向量表示: X =( x1,x2,... , xm ), 同样地,测试点的特征值也可表示成:Y =( y1,y2,... , ym )。选取适当的的距离函数,能够提高其正确率。通常KNN可采用Euclidean、Manhattan、Mahalanobis等距离用于计算。这里只说第一种Euclidean距离。
Euclidean距离为: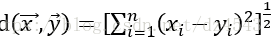
#标准化数据,即将数据化为0~1之间
def normData(dataSet):
maxVals = dataSet.max(axis=0)
minVals = dataSet.min(axis=0)
ranges = maxVals - minVals
retData = (dataSet - minVals) / ranges
return retData, ranges, minVals
#实现KNN算法
def kNN(dataSet, labels, testData, k):
distSquareMat = (dataSet - testData) ** 2 # 计算差值的平方
distSquareSums = distSquareMat.sum(axis=1) # 求每一行的差值平方和
distances = distSquareSums ** 0.5 # 开根号,得出每个样本到测试点的距离
sortedIndices = distances.argsort() # 排序,得到排序后的下标
indices = sortedIndices[:k] # 取最小的k个
labelCount = {} # 存储每个label的出现次数
for i in indices:
label = labels[i]
labelCount[label] = labelCount.get(label, 0) + 1 # 次数加一
sortedCount = sorted(labelCount.items(), key=opt.itemgetter(1), reverse=True)
# 对label出现的次数从大到小进行排序
return sortedCount[0][0] # 返回出现次数最大的label
#代入数据测试
import numpy as np
import operator as opt
if __name__ == "__main__":
dataSet = np.array([[2, 3],[1, 1],[9, 9],[6, 8]])
normDataSet, ranges, minVals = normData(dataSet)
labels = ['a','a', 'b','b']
testData = np.array([3.9, 5.5])
normTestData = (testData - minVals) / ranges
result = kNN(normDataSet, labels, normTestData, 1)
print(result)输出为a