机器学习实战学习笔记(二)-KNN算法(2)-KNN算法改进约会网站的配对效果
情景概要
某个妹子交往过三种类型的人:
- 不喜欢的人
- 魅力一般的人.
- 极具魅力的人
这个妹子想要知道自己到底喜欢哪一类男人,于是提供了她收集的约会数据(1000行,吐槽一波,手动狗头),并希望能创建一种分类机制来帮她完成这件事情。
数据表格如下:

实际数据集是这样的:
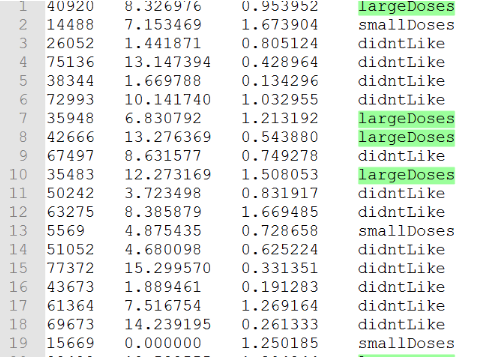
datingTestSet.txt
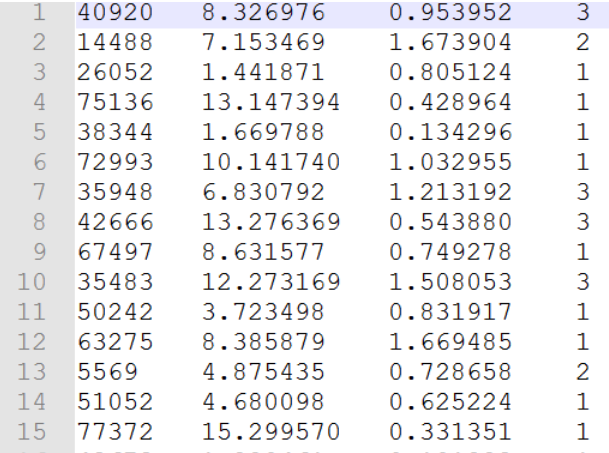
datingTestSet2.txt
导入数据
# 判断分类
def isWhichClass(className):
if className=='didntLike':
return 1
elif className=='smallDoses':
return 2
elif className=='largeDoses':
return 3
#加载数据
def file2matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
numbersOfLines=len(arrayOLines)#获取一共有多少行
returnMat=np.zeros((numbersOfLines,3))#创建n行3列的全零矩阵
classLabelVector=[]#标签向量
index=0
for line in arrayOLines:
line=line.strip()
listFormLine=line.split('\t')
returnMat[index,:]=listFormLine[0:3]
classLabelVector.append(isWhichClass(listFormLine[-1]))
index+=1
return returnMat,classLabelVector数据可视化
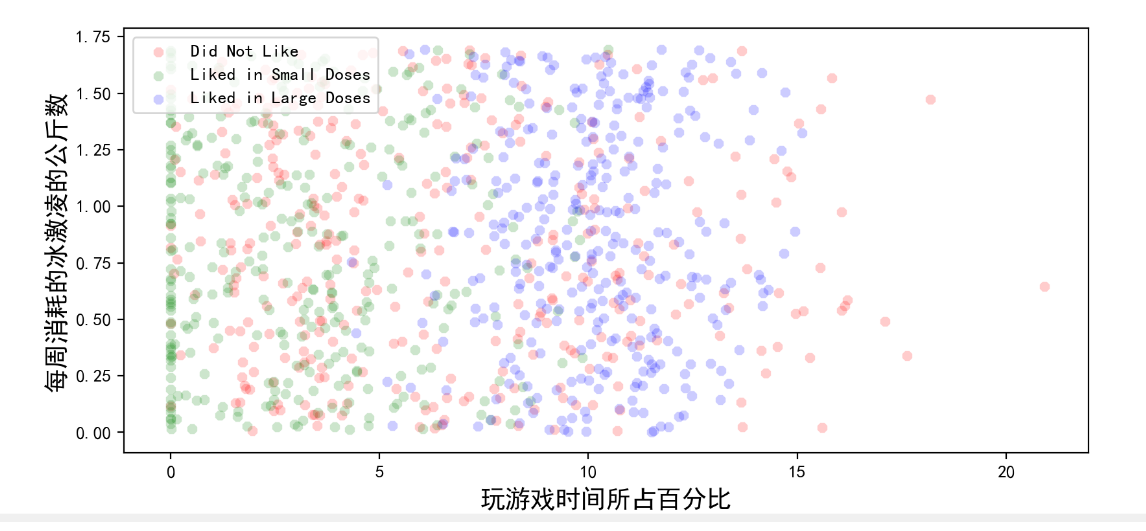
#绘图
def makeGraph():
returnMat,classLabelVector=file2matrix('KNN\datingTestSet.txt')
fig=plt.figure()
ax=fig.add_subplot(111)
x1=[x[1] for i,x in enumerate(returnMat) if classLabelVector[i]==1]
y1=[x[2] for i,x in enumerate(returnMat) if classLabelVector[i]==1]
x2=[x[1] for i,x in enumerate(returnMat) if classLabelVector[i]==2]
y2=[x[2] for i,x in enumerate(returnMat) if classLabelVector[i]==2]
x3=[x[1] for i,x in enumerate(returnMat) if classLabelVector[i]==3]
y3=[x[2] for i,x in enumerate(returnMat) if classLabelVector[i]==3]
type1=plt.scatter(x1,y1,c="red",cmap='brg',alpha=0.2, marker='8', linewidth=0)
type2=plt.scatter(x2,y2,c="green",cmap='brg',alpha=0.2, marker='8', linewidth=0)
type3=plt.scatter(x3,y3,c="blue",cmap='brg', alpha=0.2, marker='8', linewidth=0)
ax.legend([type1, type2, type3], ["Did Not Like", "Liked in Small Doses", "Liked in Large Doses"], loc=2)
mpl.rcParams['font.sans-serif']=['SimHei'] #指定默认字体 SimHei为黑体
mpl.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.xlabel('玩游戏时间所占百分比', fontsize=14)
plt.ylabel('每周消耗的冰激凌的公斤数', fontsize=14)
plt.show()归一化数据
原理:
扫描二维码关注公众号,回复:
8784931 查看本文章

为什么要归一化?
数字差值最大的属性对计算结果的影响最大,也就是说,但这三种特征是同等重要的,因此要归一化
归一化方法
在处理这种不同取值范围的特征值时,我们通常采用的方法是将数值归一化,如将取值范围
处理为0到1或者-1到1之间。下面的公式可以将任意取值范围的特征值转化为0到1区间内的值:
newvalue=(o1dValue -min) / (max- min)其中min和max分别是数据集中的最小特征值和最大特征值。
# 自动归一化
def autoNorm(dataSet):
minVal=dataSet.min(0)
maxVal=dataSet.max(0)
ranges=maxVal-minVal
normDataSet=np.zeros(np.shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet-np.tile(minVal,(m,1))
normDataSet=normDataSet/np.tile(ranges,(m,1))
return normDataSet,ranges,minVal测试分类效果
#测试数据
def datingAllClassTest():
hoRatio = 0.10 #测试集数量比例
datingDataMat,datingLabels = file2matrix("KNN\datingTestSet.txt") #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]#总样本数
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult=knnClassify(normMat[i,:],normMat[numTestVecs:m,:],datingLabels,3)
print("预测的结果是%d 真正的答案是%d"%(classifierResult,datingLabels[i]))
if classifierResult!=datingLabels[i]:
errorCount+=1
print("总的正确率是 %f"%(errorCount/float(numTestVecs)))
print("错误数量是 %d"%errorCount)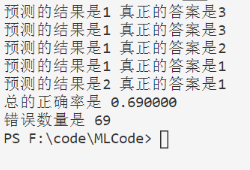
实际应用作为分类器
#使用数据判断妹子是否喜欢你
def datingClassTest():
resultList = ['妹子不喜欢你', '妹子有点喜欢你', '妹子特别喜欢你']
ffMiles=float(input("你一年坐的飞机飞多少里:"))
iceCream=float(input("你一年吃多少冰激凌?"))
gameTime=float(input("你一年打多少小时的游戏?"))
inArr=np.array([ffMiles,gameTime,iceCream])
resDataMatrix,labels=file2matrix("KNN\datingTestSet.txt")
normData,ranges,minVal=autoNorm(resDataMatrix)
classResult=knnClassify((inArr-minVal)/ranges,normData,labels,3)
print("估计是%s"%(resultList[classResult-1]))
源代码
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import operator as op
# 判断分类
def isWhichClass(className):
if className=='didntLike':
return 1
elif className=='smallDoses':
return 2
elif className=='largeDoses':
return 3
#加载数据
def file2matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
numbersOfLines=len(arrayOLines)#获取一共有多少行
returnMat=np.zeros((numbersOfLines,3))#创建n行3列的全零矩阵
classLabelVector=[]#标签向量
index=0
for line in arrayOLines:
line=line.strip()
listFormLine=line.split('\t')
returnMat[index,:]=listFormLine[0:3]
classLabelVector.append(isWhichClass(listFormLine[-1]))
index+=1
return returnMat,classLabelVector
def file3matrix(filename):
fr=open(filename)
arrayOLines=fr.readlines()
numbersOfLines=len(arrayOLines)#获取一共有多少行
returnMat=np.zeros((numbersOfLines,3))#创建n行3列的全零矩阵
classLabelVector=[]#标签向量
index=0
for line in arrayOLines:
line=line.strip()
listFormLine=line.split('\t')
returnMat[index,:]=listFormLine[0:3]
classLabelVector.append(int(listFormLine[-1]))
index+=1
return returnMat,classLabelVector
#绘图
def makeGraph():
returnMat,classLabelVector=file2matrix('KNN\datingTestSet.txt')
fig=plt.figure()
ax=fig.add_subplot(111)
x1=[x[1] for i,x in enumerate(returnMat) if classLabelVector[i]==1]
y1=[x[2] for i,x in enumerate(returnMat) if classLabelVector[i]==1]
x2=[x[1] for i,x in enumerate(returnMat) if classLabelVector[i]==2]
y2=[x[2] for i,x in enumerate(returnMat) if classLabelVector[i]==2]
x3=[x[1] for i,x in enumerate(returnMat) if classLabelVector[i]==3]
y3=[x[2] for i,x in enumerate(returnMat) if classLabelVector[i]==3]
type1=plt.scatter(x1,y1,c="red",cmap='brg',alpha=0.2, marker='8', linewidth=0)
type2=plt.scatter(x2,y2,c="green",cmap='brg',alpha=0.2, marker='8', linewidth=0)
type3=plt.scatter(x3,y3,c="blue",cmap='brg', alpha=0.2, marker='8', linewidth=0)
ax.legend([type1, type2, type3], ["Did Not Like", "Liked in Small Doses", "Liked in Large Doses"], loc=2)
mpl.rcParams['font.sans-serif']=['SimHei'] #指定默认字体 SimHei为黑体
mpl.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.xlabel('玩游戏时间所占百分比', fontsize=14)
plt.ylabel('每周消耗的冰激凌的公斤数', fontsize=14)
plt.show()
#K近邻算法
#inX是输入的数据
#dataSet是训练的数据
#labels是标签,类别
#k是周围邻居的数量
#返回预测的类别
def knnClassify(inX,dataSet,labels,k):
#计算欧式距离
dataSetSize=dataSet.shape[0]#shape是(4,2),要获取点的数量显然是shape[0]
diffMat=np.tile(inX,(dataSetSize,1))-dataSet
'''
np.tile(inX,(dataSetSize,1))=[[0,0],[0,0],[0,0],[0,0]]
dataSet=[[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]
np.tile-dataSet=[[-1.0,-1.1],[-1.0,-1.0],[0,0],[0,-0.1]]
即([x1-x0,y1-y0],[x2-x0,y2-x0],[x3-x0,y3-y0],[x4-x0,y4-y0])
'''
sqdiffMat=diffMat**2
#([(x1-x0)**2,(y1-y0)**2],[(x2-x0)**2,(y2-x0)**2],[(x3-x0)**2,(y3-y0)**2],[(x4-x0)**2,(y4-y0)**2])
sqDistances=sqdiffMat.sum(axis=1)
#([(x1-x0)**2+y1-y0)**2],[(x2-x0)**2+(y2-x0)**2],[(x3-x0)**2+(y3-y0)**2],[(x4-x0)**2+(y4-y0)**2])
# print(sqDistances)
distances=sqDistances**0.5
#([(x1-x0)**2+(y1-y0)**2]**(0.5),[(x2-x0)**2+(y2-x0)**2]**(0.5),[(x3-x0)**2+(y3-y0)**2]**(0.5),[(x4-x0)**2+(y4-y0)**2])**(0.5)
sortedDistIndicies=distances.argsort()#按照数值大小对下标排序,[2 3 1 0]
classCount={}
#选择距离最小的k个点
for i in range(k):
votIlabel=labels[sortedDistIndicies[i]]#获取最近的K个邻居的距离,对应的目标值
# print(votIlabel)
classCount[votIlabel]=classCount.get(votIlabel,0)+1#get(key,default)当key不存在时候默认值是default
sortedClassCount = sorted(classCount.items(), key=op.itemgetter(1), reverse=True)
# [('B', 2), ('A', 1)]
return sortedClassCount[0][0]#返回与其最近的k个邻居中,出现最多的次数
# 自动归一化
def autoNorm(dataSet):
minVal=dataSet.min(0)
maxVal=dataSet.max(0)
ranges=maxVal-minVal
normDataSet=np.zeros(np.shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet-np.tile(minVal,(m,1))
normDataSet=normDataSet/np.tile(ranges,(m,1))
return normDataSet,ranges,minVal
#测试数据
def datingAllClassTest():
hoRatio = 0.10 #hold out 10%
datingDataMat,datingLabels = file2matrix("KNN\datingTestSet.txt") #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult=knnClassify(normMat[i,:],normMat[numTestVecs:m,:],datingLabels,3)
print("预测的结果是%d 真正的答案是%d"%(classifierResult,datingLabels[i]))
if classifierResult!=datingLabels[i]:
errorCount+=1
print("总的正确率是 %f"%(errorCount/float(numTestVecs)))
print("错误数量是 %d"%errorCount)
#使用数据判断妹子是否喜欢你
def datingClassTest():
resultList = ['妹子不喜欢你', '妹子有点喜欢你', '妹子特别喜欢你']
ffMiles=float(input("你一年坐的飞机飞多少里:"))
iceCream=float(input("你一年吃多少冰激凌?"))
gameTime=float(input("你一年打多少小时的游戏?"))
inArr=np.array([ffMiles,gameTime,iceCream])
resDataMatrix,labels=file2matrix("KNN\datingTestSet.txt")
normData,ranges,minVal=autoNorm(resDataMatrix)
classResult=knnClassify((inArr-minVal)/ranges,normData,labels,3)
print("估计是%s"%(resultList[classResult-1]))
if __name__ == "__main__":
datingClassTest()
目录结构
数据集
https://github.com/pbharrin/machinelearninginaction
参考书籍
《机器学习实战》-彼得·哈灵顿