导读
本文是对我们ICLR 2023被接收的文章《Exploring Active 3D Object Detection from a Generalization Perspective》的介绍。这是主动学习(Active Learning)在 3D 目标检测中的开创性研究,旨在以最低的边界框标注成本来提升检测性能。为此,我们提出了一种用于 3D目标检测的分层主动学习方案,该方案可根据提出三个选择标准逐步筛选出少部分的点云用以人工标注。很荣幸地,我们的文章被ICLR 2023收录,目前项目代码已开源,欢迎大家试用。

OpenReview: https://openreview.net/forum?id=2RwXVje1rAh
Code: https://github.com/Luoyadan/CRB-active-3Ddet
概述
基于LiDAR的三维物体检测在三维场景理解中扮演着不可或缺的角色,广泛应用于自动驾驶和机器人等领域。新兴的三维检测模型可在大规模标注点云的代价下实现精确识别,其中7自由度(DOF)的三维边界框——包括每个物体的位置、尺寸和方向信息——被标注出来。在像Waymo这样的基准数据集中,超过1200万个LiDAR边界框需要进行标注,对于一个标注者来说,标注一个精确的3D框需要超过100秒的时间。这种性能提升的先决条件在很大程度上阻碍了将模型应用于野外境中的可行性,特别是在标注预算有限的情况下。
为了缓解这一限制,主动学习(Active Learning,AL)旨在通过仅查询一小部分未标注数据的标签来降低标注成本。基于标准的查询选择过程会迭代性地选择最有益于后续模型训练的样本,直至标注预算耗尽为止。该标准有望利用从样本不确定性和样本多样性中得出的启发式方法来量化样本的信息量。然而,这些AL方法通常倾向于包含更多物体(从而具有更高概率包含不确定和多样物体)的点云。在固定的注释预算下,选择这种类型的点云远非最佳选择,因为需要更多点击来形成3D框标注。
为了克服上述局限性,我们提出了以3D框为标注成本的经济高效AL标准,并实证研究其与优化泛化上界之间的关系。具体来说,我们提出了三个经济高效的点云采集选择标准,称为CRB,即标签简洁性(Label Conciseness)、特征代表性(Feature Representativeness)和几何平衡性(Geometric Balance)。我们的标准设计基于优化泛化风险上限的理论分析,泛化风险上限可以重新表述为所选子集与测试集的分布一致性。需要注意的是,由于测试集的经验分布在训练过程中无法观察到,无失一般性地,我们对其先验分布做了适当的假设。经过大量实验验证,所提出的CRB策略在两个大规模3D目标检测数据集上,无论检测器架构如何,始终能够稳定地优于所有现有的最先进AL基线算法。
方法
理论动机
由于3D目标检测是本质上是分类和回归任务的整合,因此减小集合差异是对每个分支的输入和输出进行对齐。因此,在主动选择过程中冻结检测器的情况下,找到一个最优的 D S ∗ \mathcal{D}^*_S DS∗ 可以解释为增强所获得集合的以下方面:
- 标签简洁性:对边界框的边际标签分布进行对齐;
- 特征代表性:对点云的潜在表征的边际分布进行对齐;
- 几何平衡:对点云和预测边界框的几何特征的边际分布进行对齐,可以表示为:
KaTeX parse error: Undefined control sequence: \strut at position 286: …\mathcal{P}_S, \̲s̲t̲r̲u̲t̲\widehat{\mathc…
在这里, P S \mathcal{P}_S PS 和 P T \mathcal{P}_T PT 分别表示选定集合中的点云和测试集中的点云。符号 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 表示点云的几何描述符,而 d A d_{\mathcal{A}} dA 距离可以通过有限样本集估计得出。对于潜在特征 X S X_S XS 和 X T X_T XT,我们仅关注与训练集不同的特征,因为基于零训练误差假设, E D ^ L ℓ c l s = 0 \mathbb{E}_{\widehat{D}_L}\ell^{cls}=0 ED Lℓcls=0 且 E D ^ L ℓ r e g = 0 \mathbb{E}_{\widehat{D}_L}\ell^{reg} = 0 ED Lℓreg=0。考虑到在训练期间无法观察到测试样本及其相关标签,我们对测试数据的先验分布做出假设。我们假设边界框标签和几何特征的先验分布是均匀的,注意我们可以采用KL散度来实现 d A d_{\mathcal{A}} dA,假设潜在表示服从单变量高斯分布。
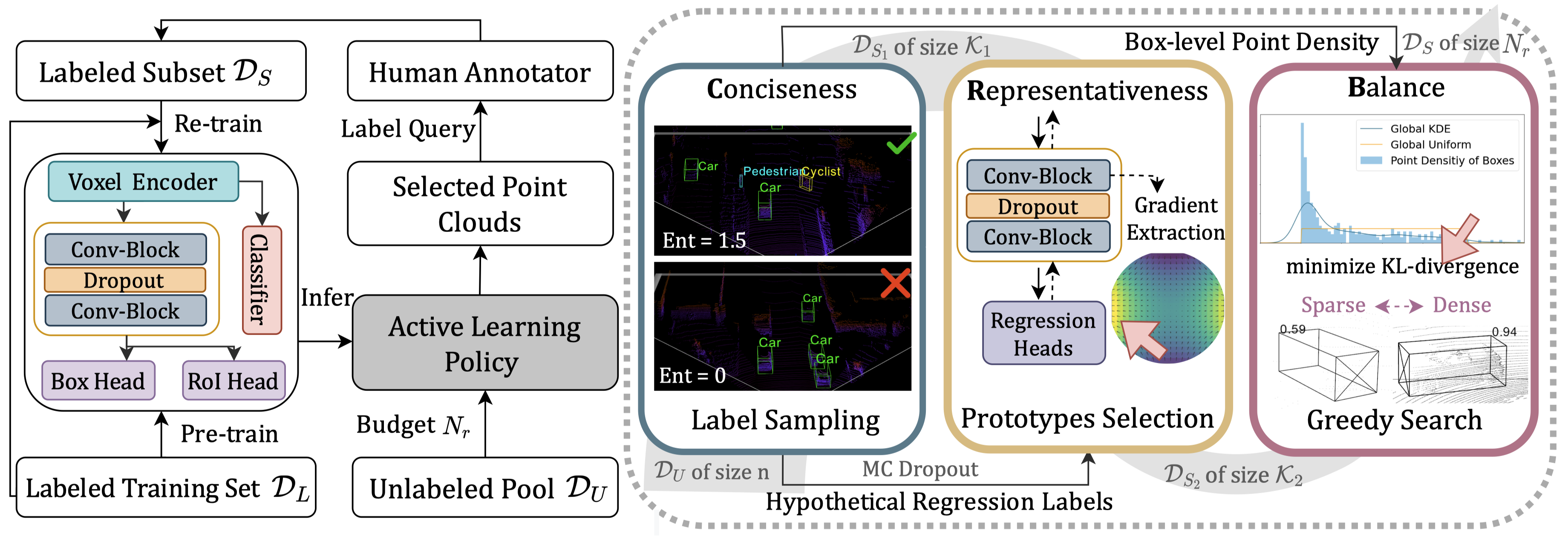
阶段1:简洁标签采样
通过将标签简洁性作为采样标准,我们旨在减轻标签冗余,并使源标签分布与目标先验标签分布相一致。特别地,我们寻找一个大小为 K 1 \mathcal{K}_1 K1的子集 D S 1 ∗ \mathcal{D}^*_{S_1} DS1∗,该子集使得概率分布 P Y S P_{Y_S} PYS与均匀分布 P Y T P_{Y_T} PYT之间的Kullback-Leibler(KL)散度最小化。为此,我们将KL散度与Shannon熵 H ( ⋅ ) H(\cdot) H(⋅)结合起来,并定义了一个最大化标签分布熵的优化问题:
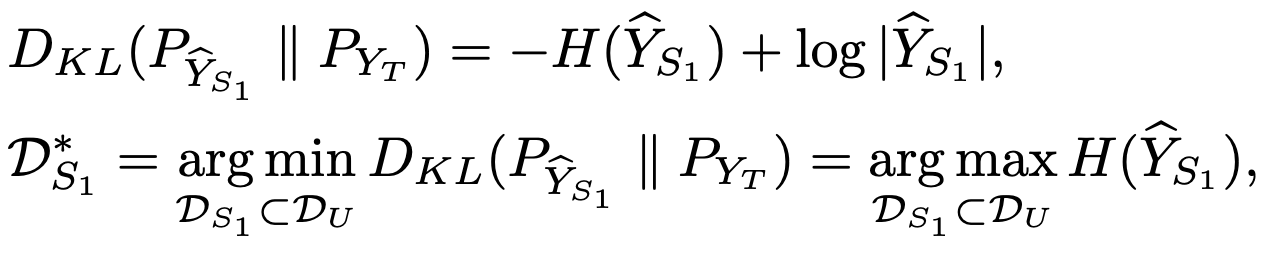
我们将来自未标记池的所有点云 { ( P ) j } i ∈ [ n ] \{(\mathcal{P})_j\}_{i\in[n]} {(P)j}i∈[n]传递给检测器,并提取 N B N_B NB个边界框的预测标签 { y ^ i } i = 1 N B \{\hat{y}_i\}_{i=1}^{N_B} { y^i}i=1NB,其中 y ^ i = argmax y ∈ [ C ] f ( x i ; w f ) \hat{y}_i = \text{argmax}_{y\in[C]} f(x_i; w_f) y^i=argmaxy∈[C]f(xi;wf)。第 j j j个点云的标签熵 H ( Y ^ j , S ) H(\widehat{Y}_{j, S}) H(Y j,S)可以计算如下,
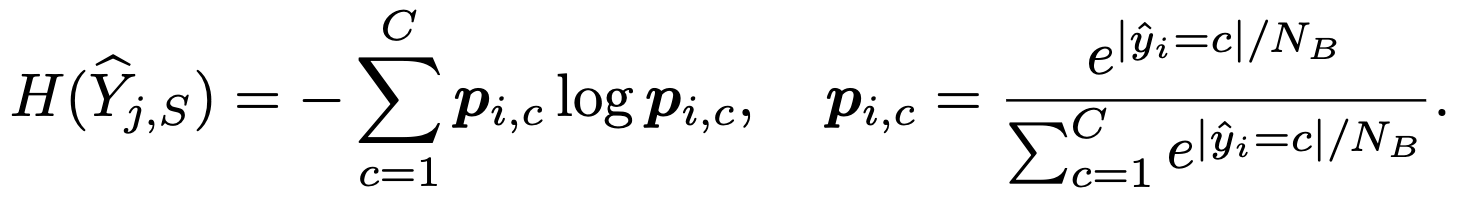
根据计算得出的熵分数,我们筛选出排名前 K 1 \mathcal{K}_1 K1 的候选项,并通过第二阶段代表性原型选择对其进行验证。
阶段2:代表性原型选择
在这个阶段,我们旨在通过测量点云的梯度向量的特征代表性,来确定子集是否涵盖了仅存在于 D U \mathcal{D}_U DU而不在 D L \mathcal{D}_L DL中编码的独特知识。我们将任务表述为梯度空间上的 K2-质心(medoids)问题,以此考察候选样本的特征代表性。为了共同考虑分类和回归目标对梯度的影响,我们启用了蒙特卡洛去除(MC-DROPOUT),并通过对多个随机前向传递的预测进行平均来构建假设标签:
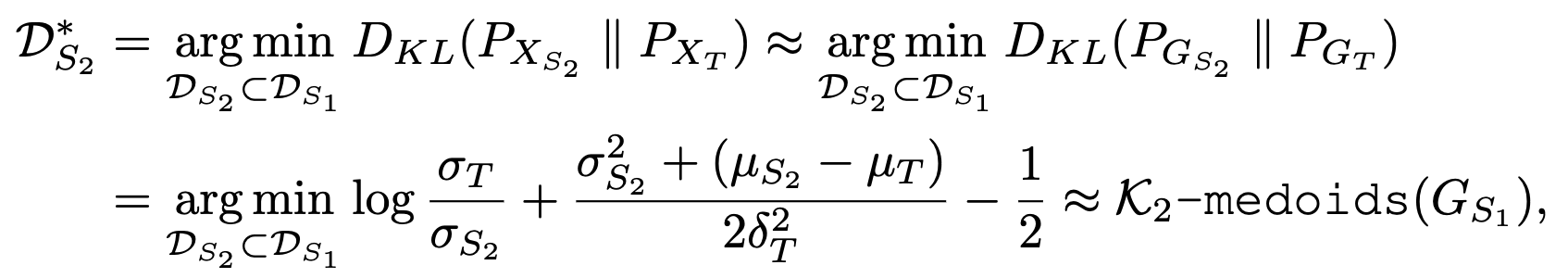
在公式中, μ S 2 \mu_{S_2} μS2、 σ S 2 \sigma_{S_2} σS2(以及 μ T \mu_T μT和 σ T \sigma_T σT)分别表示所选集合(测试集)的单变量高斯分布的均值和标准差。基于以上公式,寻找代表性集合的任务可以被视为从聚类数据中选择 K 2 \mathcal{K}2 K2个原型(即 K 2 {\mathcal{K}2} K2-medoids),以使所选子集和测试集的质心(平均值)能够自然匹配。方差 σ S 2 \sigma_{S_2} σS2和 σ T \sigma_{T} σT,基本上是每个点到其原型的距离,将同时被最小化。
阶段3:贪婪点密度平衡
所采纳的第三个标准是几何平衡,旨在使所选原型的分布与测试点云的边际分布保持一致。由于点云通常由成千上万(甚至数百万)个点组成,直接对齐点的元特征(如坐标)在计算上是昂贵的。因此,我们利用每个边界框内的点密度 ϕ ( ⋅ , ⋅ ) \phi(\cdot, \cdot) ϕ(⋅,⋅)来保持3D点云中对象的几何特性。通过对齐所选集合和未标记池的几何特征,预期精调后的探测器能够更准确地预测边界框的定位和尺寸,并在测试时识别密集和稀疏的近距离(即密集)和远距离(即稀疏)对象。点密度的概率密度函数(PDF)未知,必须从边界框预测中进行估计。为此,我们采用核密度估计(KDE),使用每个类别的有限样本集进行计算,可以表示为:

在预定义的带宽 h > 0 h>0 h>0的情况下,可以确定结果密度函数的平滑程度。我们采用高斯核函数 K e r ( ⋅ ) \mathcal{K}er(\cdot) Ker(⋅)。在定义了概率密度函数后,选取最终候选集合 D S \mathcal{D}_{S} DS的优化问题如下,其中候选集合大小为 N r N_r Nr:
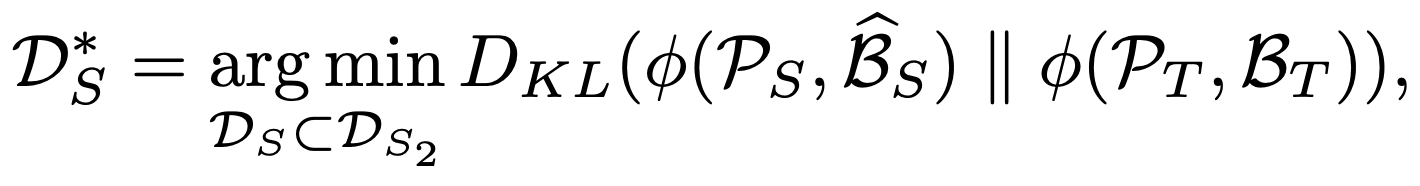
其中, ϕ ( ⋅ , ⋅ ) \phi(\cdot, \cdot) ϕ(⋅,⋅) 用于衡量每个边界框的点密度。我们采用贪婪搜索从子集 D S 2 \mathcal{D}_{S_2} DS2 中找到最优组合,以最小化与均匀分布 p ( ϕ ( P T , B T ) ) ∼ uniform ( α l o , α h i ) p(\phi(\mathcal{P}_T,\mathcal{B}_T)) \sim \texttt{uniform}(\alpha_{lo}, \alpha_{hi}) p(ϕ(PT,BT))∼uniform(αlo,αhi) 的KL距离。
实验
定量分析
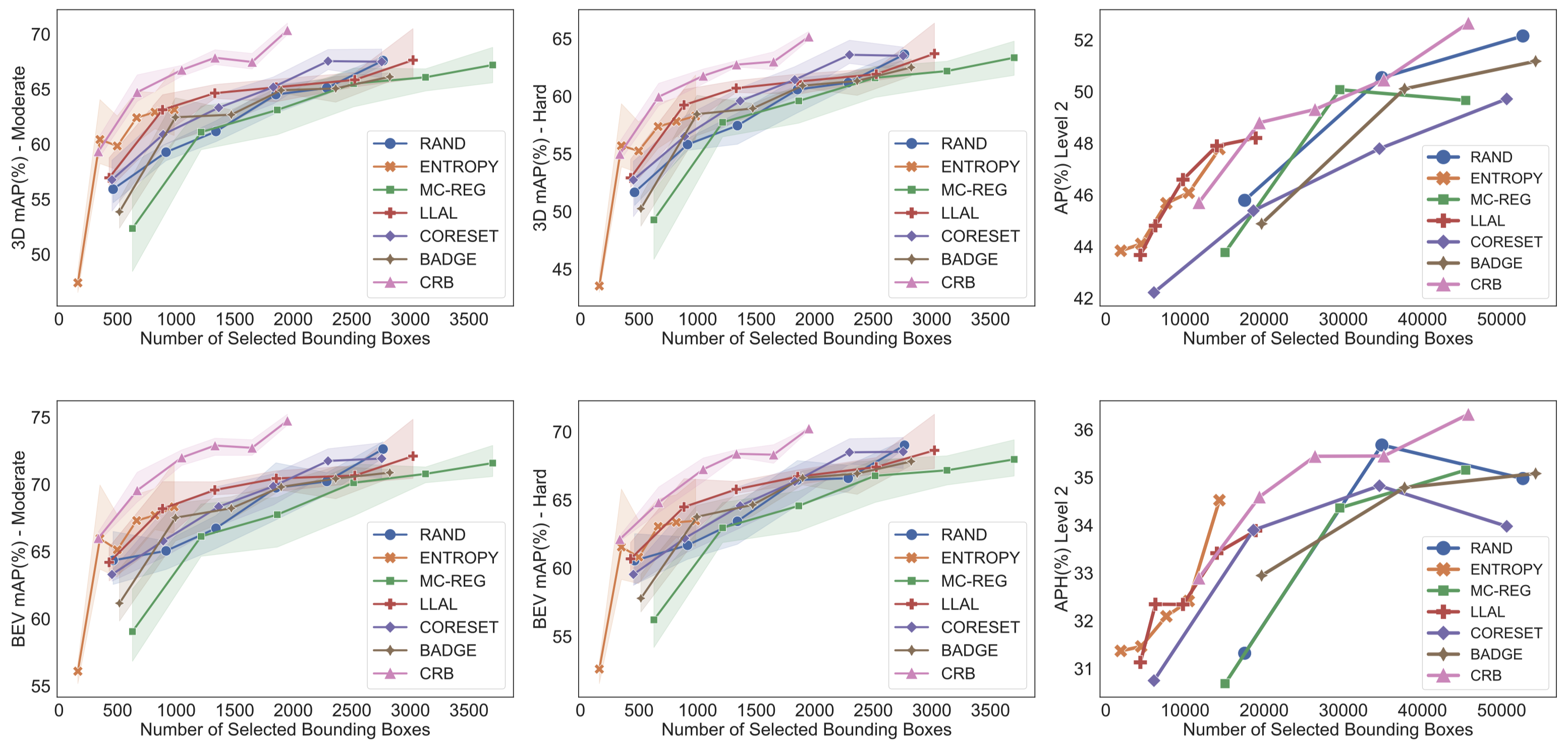
我们用PVRCNN为主干3D目标检测器。不同主动学习策略所实现的三维(3D)和鸟瞰图(BEV)检测性能如上图所示,阴影区域表示三次试验的标准差。我们可以清楚地观察到,无论注释的边界框数量和难度设置如何,CRB策略始终明显优于所有最先进的主动学习方法。值得注意的是,在KITTI数据集上,所提出的CRB的标注时间比随机抽样(RAND)快3倍,同时实现了可比较的性能。
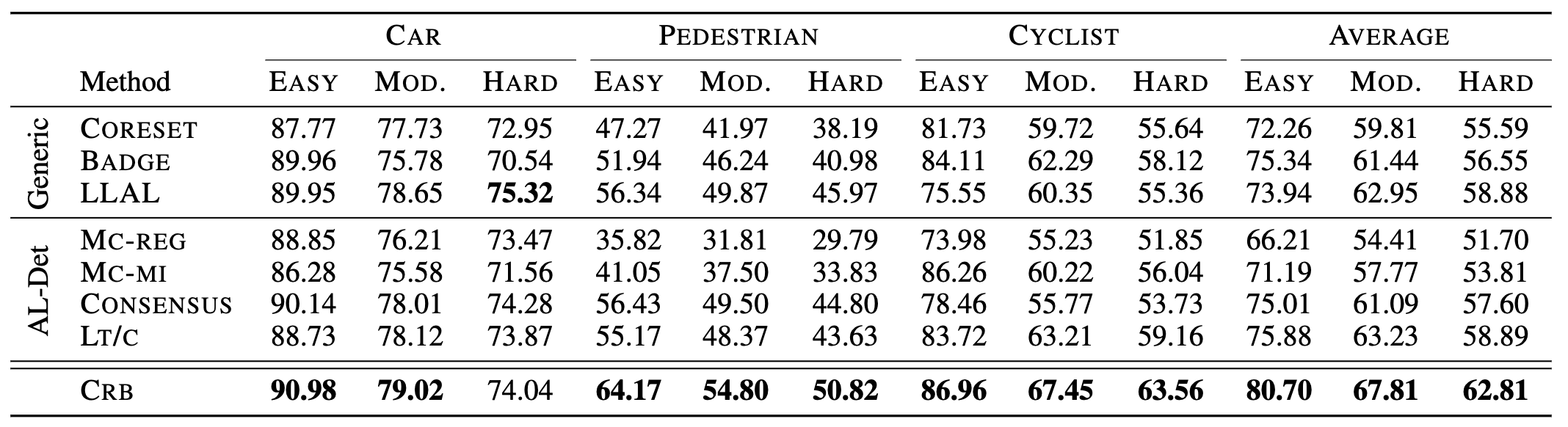
我们发现,在仅用1%标注框的情况下,由于所采用的获取标准共同考虑了分类和回归任务,LLAL和LT/C取得了具有竞争力的结果。我们提出的CRB将3D mAP分数提高了6.7%,这验证了最小化泛化风险的有效性。
定性分析

观察发现,在相同的条件下,与RAND相比,CRB能够提供更准确、更高置信度的预测。此外,从图中橙色框中突出显示的骑车者来看,采用RAND训练的检测器产生了显著较低的置信度分数。这证实了CRB所选样本与测试案例更为匹配。
3D目标检测器选择
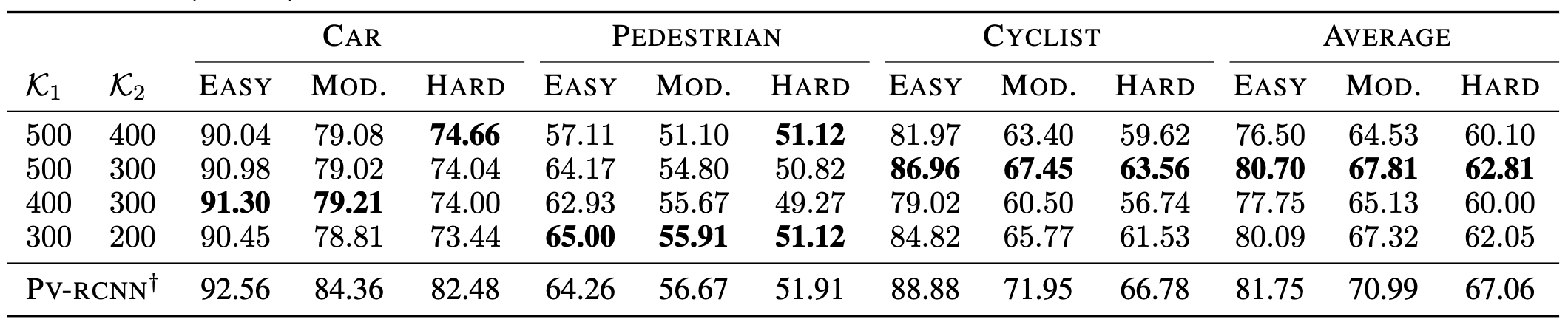
在KITTI数据集上,利用SECOND作为检测主干网络进行实验,结果如上表所示。仅利用3%的查询3D边界框,观察到所提出的CRB方法在各种检测难度下均稳定优于同类通用AL方法,在3D mAP和BEV mAP分别上提升了4.7%和2.8%。
结论、不足与未来展望
本文研究了主动3D物体检测的三种新标准,它们能以最低的3D边界框标注成本和运行时复杂性的前提下有效实现高性能3D目标检测。我们从理论上分析了找到最佳获取子集与减少集合差异之间的关系。该框架具有多功能性,可适应现有的AL策略,为启发式设计提供了深入的见解。这项工作的局限性在于对测试数据先验分布所做的一系列假设,这些假设在实践中可能会被违反。相反地,它为采用我们的框架进行主动领域自适应(Active Domain Adaptation)提供了机会,在这种情况下,目标分布可用于对齐。解决这两个问题将留给未来的工作。