点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文将为大家介绍上海人工智能实验室交通平台组ADLab-CVPR-2023最新中稿论文-Uni3D,以及3DTrans代码库中关于Multi-dataset 3D Detection算法的构建。

Uni3D: A Unified Baseline for Multi-dataset 3D Object Detection
论文:https://arxiv.org/abs/2303.06880
代码(已开源):
https://github.com/PJLab-ADG/3DTrans
PART.1
Uni3D - 一种多数据集3D目标检测的基线
1.1
Multi-domain Fusion (MDF)任务定义
MDF多域融合是指3D目标检测器在多个数据集上进行联合训练,并且需要尽可能同时在多个数据集实现较高的检测精度。需要注意,相比于Domain Adaptation(DA)领域中的Multi-source Domain Adaptation, 这里所提出的MDF任务不要求不同域之间是close-set闭集关系,即来自于不同域(或数据集)的类别分布是可以不一致的。相比于Multi-source Domain Adaptation,MDF任务设定弱化了对于不同域之间的数据分布和类别分布的条件限制。
同样我们知道,联合不同数据集进行训练从而得到一个更优的模型并不是一个新问题,在2D图像领域中已经被研究过[1, 2]。但是3D点云室外场景具有更强的数据和语义差异,导致不同3D数据集之间难以复用,难以合并到一起进行训练,成为了“数据孤岛”。
1.2
多数据集3D目标检测的主要挑战
多数据集3D目标检测主要面临以下两个挑战:
1)数据分布级别的差异:不同于由[0,255]的像素分布组成的2D图像数据,来自于不同数据集的3D点云数据通常是由不同传感器厂商采用不一致的点云感知范围采样获得的。关于三个最主流的公开自动驾驶数据集的主要差异如下所示:
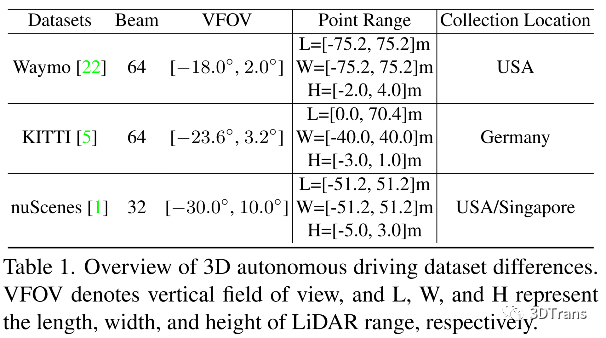
实际上,我们也发现在3D场景中难以进行多数据集3D目标检测. 其原因是:传感器不一致的点云感知范围导致对于相同物体的3D检测网络感受野是不一致的,这样会阻碍网络在不同数据集中对一种类别物体的学习过程。因此我们认为对点云进行前处理,包括不同传感器数据的点云范围对齐,传感器高度数据对齐,是进行多数据集3D目标检测的必要前处理过程。
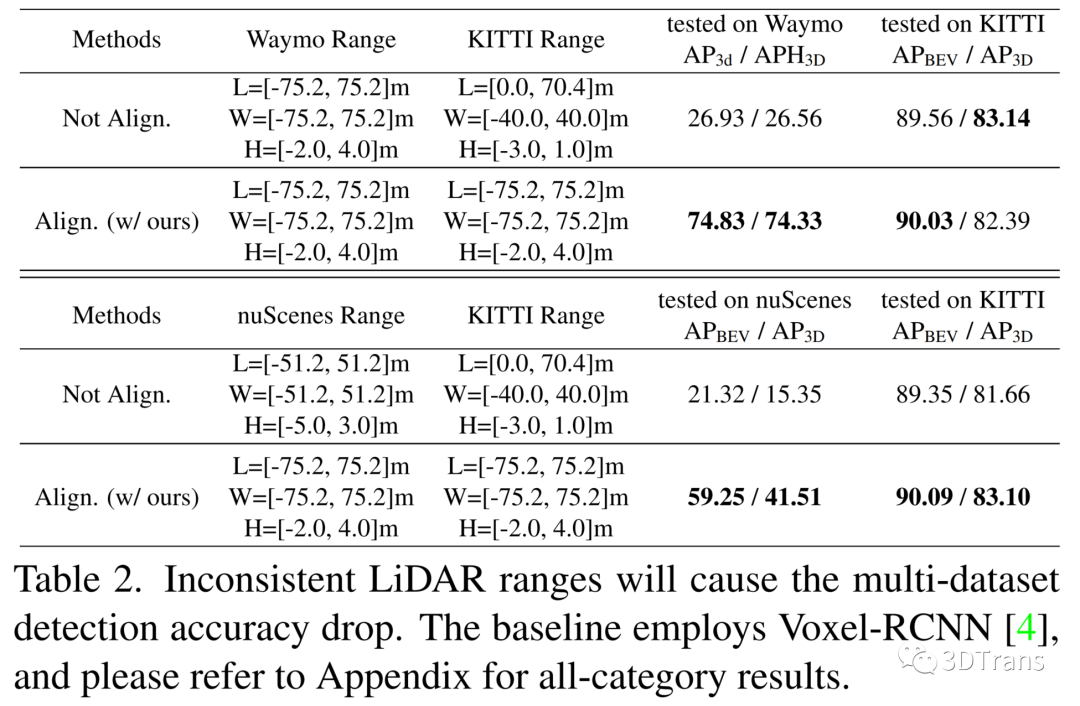
此外,数据分布级别差异也包括不同国家、地理位置,车辆大小的差异。这种差异主要会影响到3D检测器的候选框object-size的设定,对不同场景下物体定位的偏差等。
2)语义分布级别的差异:目前,不同数据集或者厂商还没有采用统一的感知类别指定标注。例如Waymo对“Vehicle”的定义是所有在地面上进行行驶的四轮车,包括卡车、货车、小汽车等。而nuScenes会采用更加细粒度的类别定义。因此要进行多数据集3D目标检测任务,我们还需要考虑语义相似性强但是定义不一致的类别空间。
1.3
Uni3D: 一种多数据集3D目标检测的基线
在设计Uni3D之前,我们尝试了一些典型的基线模型。如下图所示,我们采用Waymo和nuScenes数据集,初步设计了三种基线:Only Waymo,Only nuScenes,以及Direct Merging。这三个基线分别代表了,单数据集Waymo训练,单数据集nuScenes训练,合并Waymo-nuScenes训练三种常见的模型训练方式。
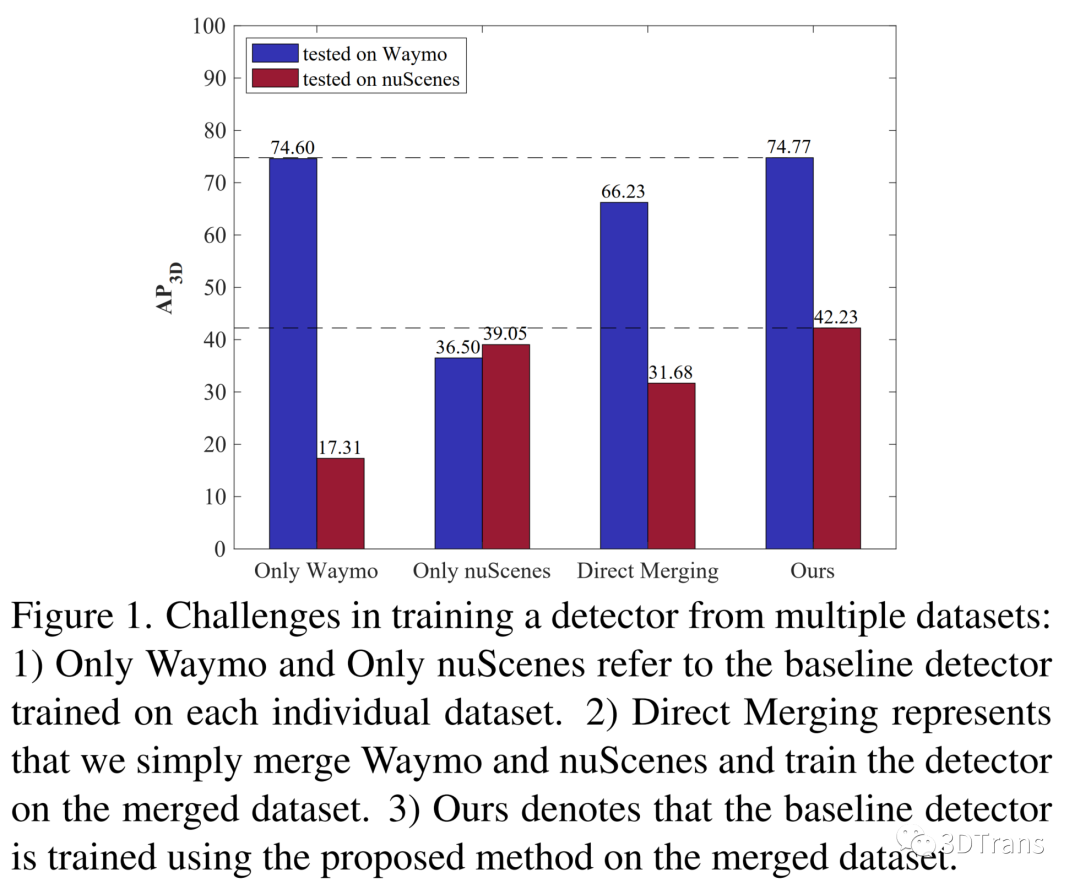
从上图我们可以观察到,对于单数据集训练方式,它对另一个数据集实际效果不理想;但是合并训练的方式同样会相比于其在原始数据集上单一训练的效果有着明显掉点,这进一步促使我们探索如何提升3D联合多数据集训练的精度。为此,我们设计了如下基线,包括:点云范围对齐/坐标矫正模块,共享参数的3D/2D骨干网络,统计量级别对齐模块,语义级别耦合模块,以及特定数据集的检测头部。
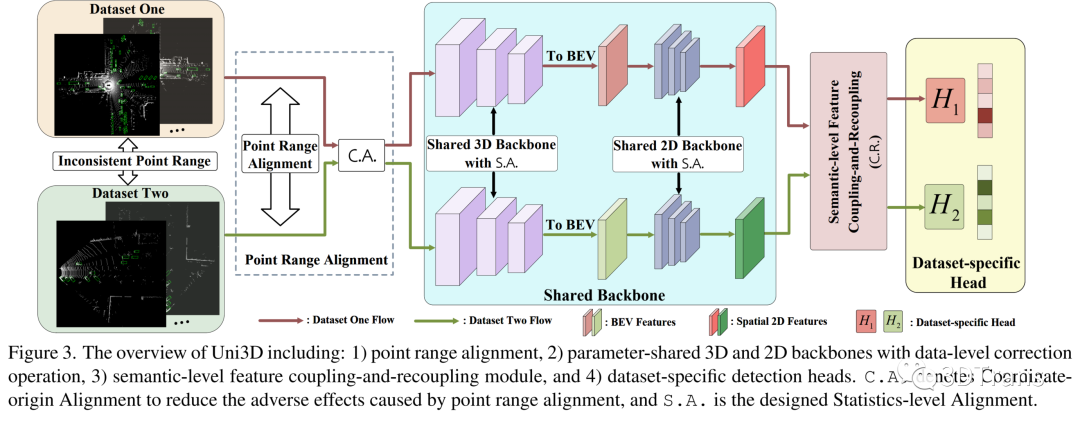
1.3.1 Uni3D框架优势
Uni3D可以将不一致的点云对齐到相同点云范围下进行训练,与此同时Uni3D采用共享参数的骨干网络和特定数据集的检测头部来实现联合多数据集检测任务,这种方式可以使用一个模型同时预测多个带有不一致类别定义和语义差异的数据集,这也进一步实现了MDF的任务要求。除此之外,Uni3D还包括两个新增模块:1)数据级校正操作和 2)语义级特征耦合-重耦合模块。
1.3.2 数据级校正操作
除了使用点云范围对齐等操作,我们还提出了数据级校正操作来缓解不同数据集之间数据统计量的差异。如果使用PV-RCNN或者Voxel-RCNN等基线检测器在多个数据集中进行训练,不同数据集输入数据的均值和方差的差异是非常显著的。然而,在MDF任务设置中,PV-RCNN或者Voxel-RCNN这种统计共享的归一化方式可能会损害训练中的模型可迁移性,因为一个Batch-size内的数据可能来自于具有不一致的均值和方差分布的不同数据集。为此,在MDF任务设置下,我们使用数据集相关的BN操作,即从第t个数据集获得数据集特定的通道平均值 和方差 。然后,采用数据集相关的均值和方差来为进行均值/方差正则化。
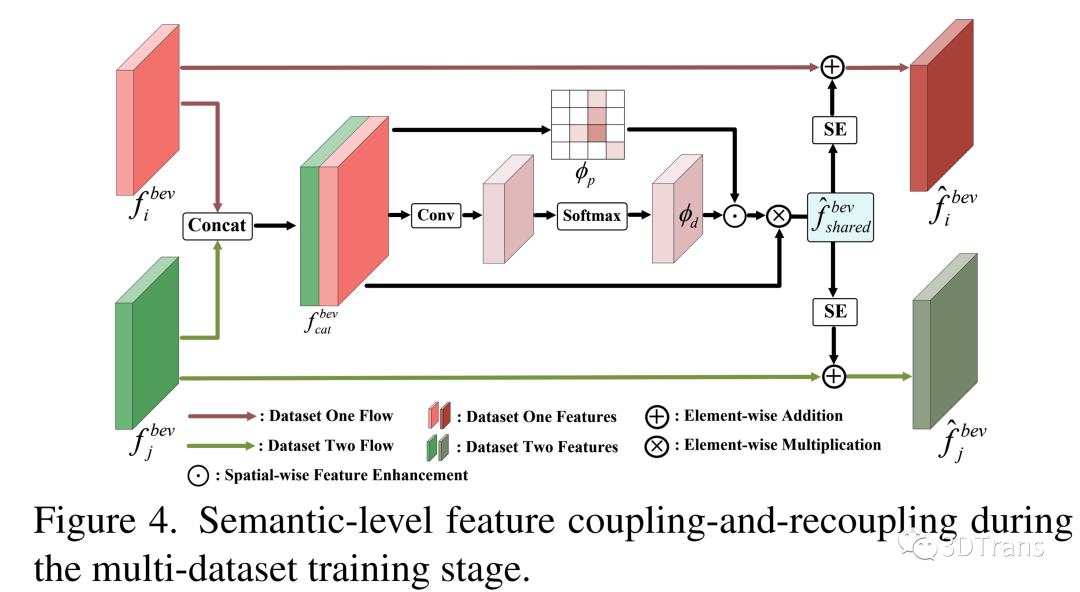
1.3.3 语义级特征耦合 - 重耦合模块
如上文所示,语义分布级别的差异主要表现为不同数据集或者自动驾驶厂商对于类别定义的粒度是不一样的。这与典型的Multi-source Domain Adaptation需要一致的类别分布是不同的。针对这样的挑战,我们采用数据集相关的检测头部,为每一个数据集分配一个参数特定的检测头。这样的方式可以使得我们的模型同时感知不同类别粒度的多个数据集。另外,我们还提出了语义级特征耦合-重耦合模块。这个模块的思路是从BEV features中探索不同数据集之前可以互相学习、复用的特征。
具体来说,首先来自于不同数据集的BEV features按照通道维度进行拼接,这样的拼接方式是为了将数据集信息编码到通道维度,从而利用后序的卷积核学习不同数据集的相关性。如下图,由于3D室外场景的稀疏性,我们采用Spatial-wise Feature Enhancement操作来增强BEV features中的前景物体表征,重点关注前景物体的可复用特征的学习;此外,学习到一个数据集re-scaling的掩码 ,根据这个掩码来重新re-scaling BEV features,获得数据集可共享的BEV features 。最终,语义级特征耦合-重耦合模块通过SENet网络将 进行channel-wise attention从而挖掘数据集相关的特性,以此来提升网络对于不同数据集的感知能力。这个模块输出 和 ,这两个BEV features是我们增强过的特征表达,分别将这两个BEV features送入到dataset-specific detection head来进行多数据集联合训练。
1.3.4 联合训练
在联合训练阶段,我们不改变原始基线检测器的Loss Function,而是对于每一个数据集都分配一个Dataset-specific Loss,最后训练过程中的总体Loss是这些Dataset-specific Loss的总和。
1.4
Uni3D实验结果
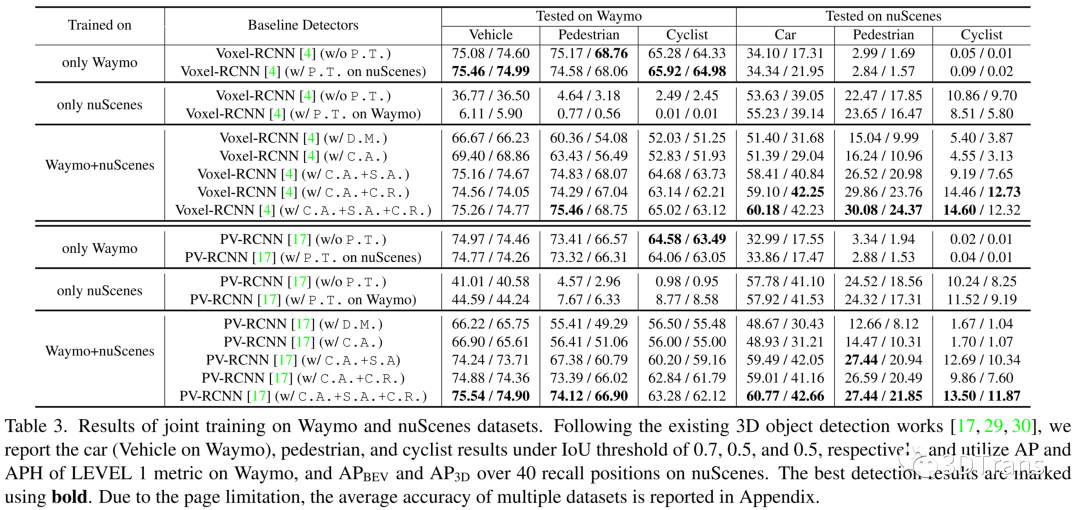
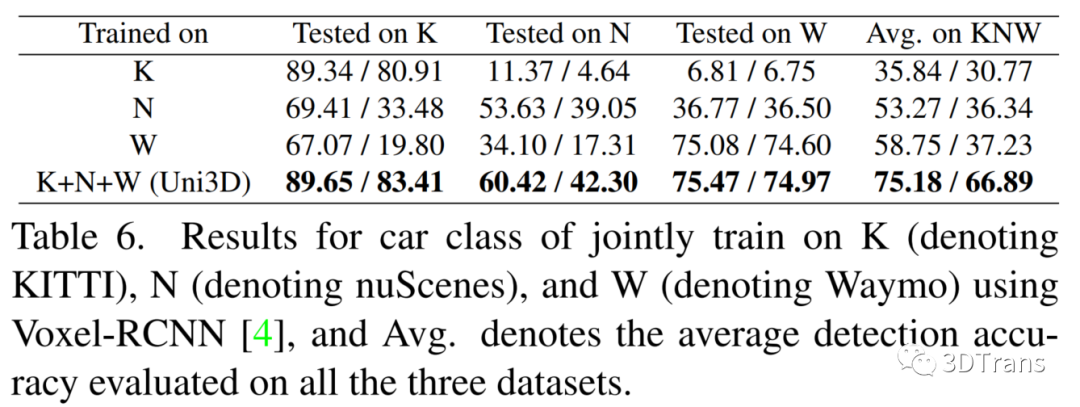
我们在Waymo,nuScenes,KITTI数据集上验证所有的基线模型,并进行了Waymo-nuScenes,nuScenes-KITTI,Waymo-KITTI,Waymo-nuScenes-KITTI多数据集联合训练的实验。这些实验都表明了3D场景下,进行多数据集联合训练的难度,以及使用我们提出的Uni3D,可以缓解模型的性能退化,学习到更加通用的表征。
Uni3D表现出对Few-shot Learning的巨大优势
在进行Uni3D的研究过程中,我们还发现了一个有意思的现象,就是Uni3D表现出对Few-shot Learning的巨大潜力。我们将在来自新场景的Few-shot Data和之前构建好的全量数据集进行合并,并使用Uni3D进行联合训练。我们发现Uni3D在nuScenes数据集上可以实现较高的Few-shot Learning性能。这进一步为3D场景下Few-shot Data的任务提供了另外的选择:选择Uni3D,并且与之前Old Domain全量数据合并到一起训练。

1.5
总结
在这项工作中,我们首次研究了如何使用多个公开3D室外数据集来训练统一的3D检测模型,并提出了一个由数据级校正操作和语义级特征耦合-重新耦合模块组成的统一3D检测框架(Uni3D),该框架可以很容易地与现有的3D检测器相结合。我们在许多公共基准上进行了广泛的实验,结果表明了Uni3D可以学习到更加通用的表达。
PART.2
3DTrans 代码库中多数据集检测算法基线的构建
3DTrans代码库,是面向自动驾驶场景迁移学习的代码库。在3DTrans代码库中,我们首次实现了基于室外3D多个感知数据集的联合3D目标检测框架。使用3DTrans框架,用户可以进一步开发更优秀的多数据集3D目标检测模型。此外3DTrans代码库还实现了对3D场景Unsupervised Domain Adaptation (UDA), Active Domain Adaptation (ADA), Semi-Supervised Domain Adaptation (SSDA)的支持,将多个迁移学习任务合并到了统一的代码框架中,为研发人员提供统一、友好的开发社区。
对于MDF部分,使用者可以根据具体的目标检测基线,结合train_multi_db_utils.py函数实现更多功能的多数据集目标检测基线。详细内容请参考:
https://github.com/PJLab-ADG/3DTrans/blob/master/docs/GETTING_STARTED_MDF.md
PART.3
讨论:我们能实现3D自动驾驶通用感知吗?
ChatGPT/GPT-4等大模型引发我们对自动驾驶大模型的思考
众所周知,全面、多样的语料库是构建强大、通用的NLP或者跨模态大模型的基石。一些研究表明,如果可以获取到代表力强、差异性强的预训练数据,基础模型的参数量的增加是可以带来预训练性能的提升。
然而在3D LiDAR自动驾驶场景下,由于不同厂商所提供的原始数据之间的差异很大,导致难以在自动驾驶领域获得一个unified dataset。因此,到目前阶段,我们认为在自动驾驶领域实现通用感知的一个必要路线是进行unified dataset的构建,或者是设计一个unified baseline model使得其可以在带有差异化的数据集中学习到一个unified representations。当然,Uni3D选择了后者。与此同时,我们也并没有放弃对前者的努力,近期团队的另一个研究工作Bi3D Bi3D: 首个主动领域适配3D目标检测算法(已开源) 就是在探索如何从海量无标注的自动驾驶数据集中挑选出最优价值的数据,这个研究工作的最终目的实际上是为了从目前已知的多个学术数据集中挑选有价值样本,以最小的存储代价构建一个unified dataset。
统一化vs差异化
单一的追求数据量的提升难以让模型学到通用表征,而差异化的数据在训练的时候难以收敛。在3D场景下,点云数据差异主要来源于很多方面,包括:传感器参数,LiDAR Beam,LiDAR所能感知的距离,天气条件的变化,地理位置等等。差异化的数据具有学习到generalizable representations的巨大潜力,但是差异化的数据同时也为模型训练带来了挑战。因此,Uni3D对于3D自动驾驶场景下的预训练研究提出了初步的解决方案——如何在差异化的数据中获取到通用表征。未来,我们也会继续通过Uni3D的技术路线,进一步探索实现更多厂商、分布差异数据集中联合训练的可能性。将联合众多带有差异但是具有价值的3D感知数据,从这些数据中获取通用表征。
参考文献:
[1] Xingyi Zhou, Vladlen Koltun, and Philipp Krahenb. Simple multi-dataset detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7571–7580, 2022.
[2] Xiyang Dai, Yinpeng Chen, Bin Xiao, Dongdong Chen, Mengchen Liu, Lu Yuan, and Lei Zhang. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7373–7382, 2021.
最新CVPP 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
3D目标检测交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-3D目标检测微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如3D目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看