为了跟进RL的最新进展和研究,并寻求高质量文章。本节笔者来介绍 ICLR2023 中得分在top前5%的文章《EXTREME Q-LEARNING: MAXENT RL WITHOUT ENTROPY》原理介绍,并进行了学习笔记的归纳总结。方便各位读者进行学习。原文各位读者可以从Openreview中找到,原文链接如下:
同CQL一样,笔者将会从理论与应用两个角度来描述EQL算法,对于想直接应用的读者可以直接跳过理论部分直接查看如何应用。本文的作者最后也给出了EQL和CQL两篇文章之间的联系,希望给各位读者予以启发。本文结构与作者原文结构类似地给出:本篇笔者介绍1,2,3三部分,感兴趣应用的读者请转手阅读第 4 部分。第4部分将会写在《Extreme Q-Learning(EQL)极值Q学习(ICLR 2023 top5%)(二)应用及代码》中,读者可查阅如何应EQL算法和代码。理论或应用根据读者需求进行自行取舍。
本篇内容仅代表读者个人的学习笔记和思路。如有读者产生异议,欢迎各位读者进行批评和指正,笔者希望能够在学习中与各位读者共同进步。
1.预备知识介绍:主要介绍关于带有KL约束的Q-Learning和Fisher-Tippett 极值定理,Gumbel回归简介。
2.极值Q学习方法介绍和基本原理概述,包括:Gumbel回归分析,Gumbel误差分析,Gumbel回归建模以及Gumbel极值Q学习(EQL)与保守Q学习(CQL)之间的联系。
3.极值Q学习算法,实现与动作选取。
4.极值Q学习应用+代码。
1.预备知识介绍
作为开始,首先介绍它的前置算法,这写笔者在另一篇文章中《Conservative Q-Learning(CQL)保守Q学习(二)-CQL2(下界V值估计)》已经进行过简要的介绍了。
1.1 、带有KL约束的 soft-Q-Learning
针对一个时间步长为 T T T的MDP过程。RL的目标是想要学习一个策略 π ( a ∣ s ) \pi(a|s) π(a∣s),使得下式尽可能的最大。
E a t ~ π ( a t ∣ s t ) [ ∑ t = 0 T γ t r ( s t , a t ) ] E_{a_t~\pi(a_t|s_t)}[\sum_{t=0}^T\gamma^tr(s_t,a_t)] Eat~π(at∣st)[t=0∑Tγtr(st,at)]为了增强这个奖励的影响大小,增添一个参考分布 μ ( a ∣ s ) \mu(a|s) μ(a∣s)和KL约束,这又称为最大熵RL,通过简单的化简和整理得到:
E a t ~ π ( a t ∣ s t ) [ ∑ t = 0 T γ t r ( s t , a t ) ] − β K L ( π ( a t ∣ s t ) ∣ ∣ μ ( a t ∣ s t ) ) E_{a_t~\pi(a_t|s_t)}[\sum_{t=0}^T\gamma^tr(s_t,a_t)]-\beta KL(\pi (a_t|s_t)||\mu(a_t|s_t)) Eat~π(at∣st)[t=0∑Tγtr(st,at)]−βKL(π(at∣st)∣∣μ(at∣st))
E a t ~ π ( a t ∣ s t ) [ ∑ t = 0 T γ t r ( s t , a t ) − β l o g π ( a t ∣ s t ) μ ( a t ∣ s t ) ] E_{a_t~\pi(a_t|s_t)}[\sum_{t=0}^T\gamma^tr(s_t,a_t)-\beta log\frac{\pi (a_t|s_t)}{\mu(a_t|s_t)}] Eat~π(at∣st)[t=0∑Tγtr(st,at)−βlogμ(at∣st)π(at∣st)]这体现在Bellman方程里面上分别对应着以下两种,其实我们已经在《Conservative Q-Learning(CQL)保守Q学习(一)-CQL1(下界Q值估计)》中介绍过了,抽样出一个数据对 ( s t , a t , s t + 1 ) (s_t,a_t,s_{t+1}) (st,at,st+1)
Q k + 1 ( s t , a t ) = r ( s t , a t ) + E s t + 1 ~ T , a t + 1 ~ π [ Q k ( s t + 1 , a t + 1 ) ] Q^{k+1}(s_t,a_t)=r(s_t,a_t)+E_{s_{t+1}~T,a_{t+1}~\pi}[Q^k(s_{t+1},a_{t+1})] Qk+1(st,at)=r(st,at)+Est+1~T,at+1~π[Qk(st+1,at+1)]在Q学习的时候,往往我们取可以使得 Q k ( s t , a t ) Q^k(s_t,a_t) Qk(st,at)最好的动作,即往往在Q更新时采用这样的 π \pi π:
Q k + 1 ( s t , a t ) = r ( s t , a t ) + E s t + 1 ~ T [ m a x a t + 1 Q k ( s t + 1 , a t + 1 ) ] Q^{k+1}(s_t,a_t)=r(s_t,a_t)+E_{s_{t+1}~T}[max_{a_{t+1}}Q^k(s_{t+1},a_{t+1})] Qk+1(st,at)=r(st,at)+Est+1~T[maxat+1Qk(st+1,at+1)]现在加入了KL约束后,我们发现它的更新变为了:
Q k + 1 ( s t , a t ) = r ( s t , a t ) + E s t + 1 ~ T , a t + 1 ~ π [ Q k ( s t + 1 , a t + 1 ) − β l o g π ( a t + 1 ∣ s t + 1 ) μ ( a t + 1 ∣ s t + 1 ) ] Q^{k+1}(s_t,a_t)=r(s_t,a_t)+E_{s_{t+1}~T,a_{t+1}~\pi}[Q^k(s_{t+1},a_{t+1})-\beta log\frac{\pi(a_{t+1}|s_{t+1})}{\mu(a_{t+1}|s_{t+1})}] Qk+1(st,at)=r(st,at)+Est+1~T,at+1~π[Qk(st+1,at+1)−βlogμ(at+1∣st+1)π(at+1∣st+1)]这样我们发现原来的目标是去max一个 E s t + 1 ~ T , a t + 1 ~ π [ Q k ( s t + 1 , a t + 1 ) ] E_{s_{t+1}~T,a_{t+1}~\pi}[Q^k(s_{t+1},a_{t+1})] Est+1~T,at+1~π[Qk(st+1,at+1)]。我们求解的时候其实就是寻求一个 π \pi π,使得下式最大:
a r g m a x π [ ∑ T ( s t + 1 ∣ s t , a t ) π ( a t + 1 ∣ s t + 1 ) Q ( s t + 1 , a t + 1 ) ] argmax_\pi[\sum T(s_{t+1}|s_t,a_{t})\pi(a_{t+1}|s_{t+1})Q(s_{t+1},a_{t+1})] argmaxπ[∑T(st+1∣st,at)π(at+1∣st+1)Q(st+1,at+1)]很明显这个最大的策略是使得每个状态转移分布下 Q ( s t + 1 , a t + 1 ) Q(s_{t+1},a_{t+1}) Q(st+1,at+1)是最大的。即选一个最大的策略 m a x a t + 1 Q ( s t + 1 , a t + 1 ) max_{a_{t+1}}Q(s_{t+1},a_{t+1}) maxat+1Q(st+1,at+1)。
那么同理,我们来推理加入了KL约束后的更新格式,这一部分笔者其实已经在《Conservative Q-Learning(CQL)保守Q学习(二)-CQL2(下界V值估计)》中进行过推导了,采用的是Langrange乘子法求解最大的 π \pi π。
a r g m a x π [ ∑ T ( s t + 1 ∣ s t , a t ) π ( a t + 1 ∣ s t + 1 ) [ Q ( s t + 1 , a t + 1 ) − β l o g π ( a t + 1 ∣ s t + 1 ) μ ( a t + 1 ∣ s t + 1 ) ] argmax_\pi[\sum T(s_{t+1}|s_t,a_{t})\pi(a_{t+1}|s_{t+1})[Q(s_{t+1},a_{t+1})-\beta log\frac{\pi(a_{t+1}|s_{t+1})}{\mu(a_{t+1}|s_{t+1})}] argmaxπ[∑T(st+1∣st,at)π(at+1∣st+1)[Q(st+1,at+1)−βlogμ(at+1∣st+1)π(at+1∣st+1)]这里笔者不赘述重新推导了。应用lagrange乘子对 π \pi π求导,进行汇总可以求得在每个固定 s t + 1 s_{t+1} st+1时取最大时候的 π \pi π有如下等式成立:
μ ( a ∣ s ) e Q ( s , a ) + L − 1 β = π ( a ∣ s ) \mu(a|s)e^{\frac{Q(s,a)+L-1}{\beta}}=\pi(a|s) μ(a∣s)eβQ(s,a)+L−1=π(a∣s)
l o g ( e L − 1 β ∑ μ ( a ∣ s ) e Q ( s , a ) β ) = l o g ( 1 ) = 0 → L = 1 − β l o g ∑ μ ( a ∣ s ) e Q ( s , a ) β log(e^{\frac{L-1}{\beta}}\sum \mu(a|s)e^{\frac{Q(s,a)}{\beta}})=log(1)=0 \rightarrow L=1-\beta log\sum \mu(a|s)e^{\frac{Q(s,a)}{\beta}} log(eβL−1∑μ(a∣s)eβQ(s,a))=log(1)=0→L=1−βlog∑μ(a∣s)eβQ(s,a)代入回 L L L得到:
π ( a ∣ s ) = μ ( a ∣ s ) e Q ( s , a ) β ∑ a μ ( a ∣ s ) e Q ( s , a ) β \pi(a|s)=\frac{\mu(a|s)e^{\frac{Q(s,a)}{\beta}}}{\sum_a\mu(a|s)e^{\frac{Q(s,a)}{\beta}}} π(a∣s)=∑aμ(a∣s)eβQ(s,a)μ(a∣s)eβQ(s,a)再次代入回原式中有:
∑ T ( s t + 1 ∣ s t , a t ) π ( a t + 1 ∣ s t + 1 ) β l o g ∑ a μ ( a ∣ s t + 1 ) e Q ( s t + 1 , a ) β \sum T(s_{t+1}|s_t,a_{t})\pi(a_{t+1}|s_{t+1})\beta log\sum_a\mu(a|s_{t+1})e^{\frac{Q(s_{t+1},a)}{\beta}} ∑T(st+1∣st,at)π(at+1∣st+1)βloga∑μ(a∣st+1)eβQ(st+1,a)这也即等同于下式,文中把这个式子称为 V ∗ V^{*} V∗即:
V ∗ ( s t + 1 ) = β l o g ∑ a μ ( a ∣ s t + 1 ) e Q ( s t + 1 , a ) β V^{*}(s_{t+1})=\beta log\sum_a\mu(a|s_{t+1})e^{\frac{Q(s_{t+1},a)}{\beta}} V∗(st+1)=βloga∑μ(a∣st+1)eβQ(st+1,a)此时加入了KL约束的Q更新规则为:
Q k + 1 ( s t , a t ) = r ( s t , a t ) + E s t + 1 ~ T [ β l o g ∑ a μ ( a ∣ s t + 1 ) e Q ( s t + 1 , a ) β ] Q^{k+1}(s_t,a_t)=r(s_t,a_t)+E_{s_{t+1}~T}[\beta log\sum_a\mu(a|s_{t+1})e^{\frac{Q(s_{t+1},a)}{\beta}}] Qk+1(st,at)=r(st,at)+Est+1~T[βloga∑μ(a∣st+1)eβQ(st+1,a)]这个式子称为带有KL约束的soft-Q-Learning更新公式。
若把它写成Bellman算子格式,对应的算子称为软Bellman算子(soft-Bellman operator) B ∗ B^* B∗,公式为:
B ∗ Q ( s , a ) = r ( s , a ) + E s ′ ~ T [ β l o g ∑ a μ ( a ∣ s ′ ) e Q ( s ′ , a ) β ] B^*Q(s,a)=r(s,a)+E_{s'~T}[\beta log\sum_a\mu(a|s^{'})e^{\frac{Q(s^{'},a)}{\beta}}] B∗Q(s,a)=r(s,a)+Es′~T[βloga∑μ(a∣s′)eβQ(s′,a)]其中,称
V ∗ ( s ) = β l o g ∑ a μ ( a ∣ s ) e Q ( s , a ) β = L μ β [ Q ( s , a ) ] V^{*}(s)=\beta log\sum_a\mu(a|s)e^{\frac{Q(s,a)}{\beta}}=L_{\mu}^\beta[Q(s,a)] V∗(s)=βloga∑μ(a∣s)eβQ(s,a)=Lμβ[Q(s,a)]并且注意到我们之前得到了最优的策略其实等价于下式:
π ( a ∣ s ) = μ ( a ∣ s ) e Q ( s , a ) − V ∗ ( s ) β = μ ( a ∣ s ) e Q ( s , a ) β ∑ a μ ( a ∣ s ) e Q ( s , a ) β \pi(a|s)=\mu(a|s)e^{\frac{Q(s,a)-V^*(s)}{\beta}}=\frac{\mu(a|s)e^{\frac{Q(s,a)}{\beta}}}{\sum_a\mu(a|s)e^{\frac{Q(s,a)}{\beta}}} π(a∣s)=μ(a∣s)eβQ(s,a)−V∗(s)=∑aμ(a∣s)eβQ(s,a)μ(a∣s)eβQ(s,a)这即为加入了KL限制的Q-Learning,又称为soft更新Q-learning,笔者这一部分与原文是一致的,不影响读者进行理解,如果不理解原文内容希望笔者这一部分有助于各位去理解,下面是原文中的公式(1)(2):分别对应笔者上述的推导:

1.2 、 Fisher-Tippett 极值定理与Gumbel-Max Trick
定义:(第一类极值分布)Gumbel distribution(Gumbel分布) g ( μ , β ) g(\mu, \beta) g(μ,β),其概率密度函数满足
p ( x ) = e x p [ − ( x − μ β + e x p [ − x − μ β ] ) ] p(x)=exp[-(\frac{x-\mu}{\beta}+exp[-\frac{x-\mu}{\beta}])] p(x)=exp[−(βx−μ+exp[−βx−μ])](Fisher-Tippett 极值定理):
对于独立同分布的随机变量 X 1 , X 2 ⋅ ⋅ ⋅ ⋅ X n ~ f X X_1,X_2····X_n~f_X X1,X2⋅⋅⋅⋅Xn~fX而言:
1、若 f X f_X fX具有指数尾概率分布,则最大值极限分布服从Gumbel分布
l i m i → ∞ m a x i ( X i ) ~ g ( μ , β ) lim_{i\rightarrow \infty}max_i(X_i)~g(\mu, \beta) limi→∞maxi(Xi)~g(μ,β)2、特别地,若 X 1 , X 2 ⋅ ⋅ ⋅ ⋅ X n ~ g ( μ , β ) X_1,X_2····X_n~g(\mu, \beta) X1,X2⋅⋅⋅⋅Xn~g(μ,β),那么最大值分布服从Gumbel分布
m a x i ( X i ) ~ g ( μ , β ) max_i(X_i)~g(\mu, \beta) maxi(Xi)~g(μ,β)(Gumbel-Max Trick):
设 ϵ 1 , ϵ 2 . . . ϵ n \epsilon_1,\epsilon_2...\epsilon_n ϵ1,ϵ2...ϵn服从分布 g ( 0 , β ) g(0,\beta) g(0,β),且它们之间相互独立。现存在一固定集合{
x 1 , x 2 , . . . x n x_1,x_2,...x_n x1,x2,...xn},设集合{
y 1 , y 2 . . . . y n y_1,y_2....y_n y1,y2....yn}满足 y i = x i + ϵ i y_i=x_i+\epsilon_i yi=xi+ϵi,那么拥有如下结论:
m a x i ( x i + ϵ i ) ~ g ( β l o g ∑ i e x p ( x i β ) , β ) , a r g m a x ( x i + ϵ i ) ~ s o f t m a x ( x i β ) max_i(x_i+\epsilon_i)~g(\beta log \sum_i exp(\frac{x_i}{\beta}),\beta), argmax(x_i+\epsilon_i)~softmax(\frac{x_i}{\beta}) maxi(xi+ϵi)~g(βlogi∑exp(βxi),β),argmax(xi+ϵi)~softmax(βxi)
2、极值Q学习原理概述
2.1、Extreme-Gumbel 误差分析
作为开始,首先作者记录了在传统更新下的Bellman误差 e r r o r error error,定义如下,作者迭代了RL算法100000次(SAC)为例,每5000次记录一下Bellman误差,记录时选取一个Batch的样本进行计算:
B e l l m a n − e r r o r = [ r ( s , a ) + Q ( s ′ , π ( s ′ ) ) − Q ( s , a ) ] Bellman-error=[r(s,a)+Q(s',\pi(s')) -Q(s,a)] Bellman−error=[r(s,a)+Q(s′,π(s′))−Q(s,a)] π ( s ′ ) \pi(s') π(s′)代表着状态 s ′ s' s′在某个已有策略 π \pi π下的确定性策略或是一个采样的平均策略。通过误差采样作者发现,Bellman-error更倾向于Gumbel分布,而不是服从正态分布,结果如下图所示。
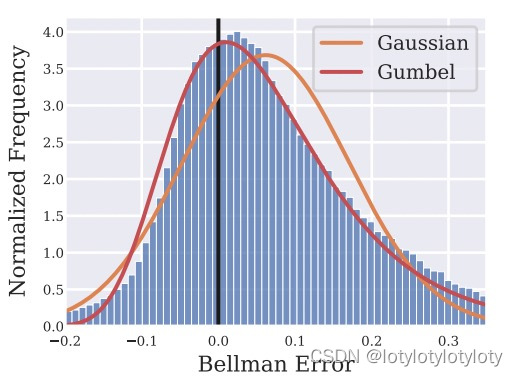
针对此现象的出现,作者给出了简略的描述,但是笔者认为条件和推导是缺乏一定的严谨性的,笔者进行了重新的分析,假设待估计的Q与真实Q函数分别称为: Q ^ \hat{Q} Q^与 Q ˉ \bar{Q} Qˉ,并且设 Q ^ \hat{Q} Q^是 Q ˉ \bar{Q} Qˉ的无偏估计,那么在任意迭代时刻 t t t下,都会有:
Q ^ t ( s , a ) = Q ˉ t ( s , a ) + ϵ t ( s , a ) \hat{Q}_t(s,a)=\bar{Q}_t(s,a)+\epsilon_t(s,a) Q^t(s,a)=Qˉt(s,a)+ϵt(s,a)根据讨论,在迭代的时候会根据bellman方程计算 Q ^ t + 1 \hat{Q}_{t+1} Q^t+1,(作者使用了M个估计器中其中一个进行计算)即计算细节为:
Q ^ t + 1 ( s , a ) = r ( s , a ) + [ m a x a ′ Q ^ t ( s ′ , a ′ ) ] = r ( s , a ) + [ m a x a ′ [ Q ˉ t ( s ′ , a ′ ) + ϵ t ( s ′ , a ′ ) ] ] \hat{Q}_{t+1}(s,a)=r(s,a)+[max_{a'}\hat{Q}_{t}(s',a')]=r(s,a)+[max_{a'}[\bar{Q}_t(s',a')+\epsilon_t(s',a')]] Q^t+1(s,a)=r(s,a)+[maxa′Q^t(s′,a′)]=r(s,a)+[maxa′[Qˉt(s′,a′)+ϵt(s′,a′)]]
Q ˉ t + 1 ( s , a ) = E [ Q ^ t + 1 ( s , a ) ] = r ( s , a ) + E ϵ t E s ′ [ m a x a ′ [ Q ˉ t ( s ′ , a ′ ) + ϵ t ( s ′ , a ′ ) ] ] ] \bar{Q}_{t+1}(s,a)=E[\hat{Q}_{t+1}(s,a)]=r(s,a)+E_{\epsilon_t}E_{s'}[max_{a'}[\bar{Q}_t(s',a')+\epsilon_t(s',a')]]] Qˉt+1(s,a)=E[Q^t+1(s,a)]=r(s,a)+EϵtEs′[maxa′[Qˉt(s′,a′)+ϵt(s′,a′)]]]两式相减会得到:
ϵ t + 1 ( s , a ) = [ m a x a ′ [ Q ˉ t ( s ′ , a ′ ) + ϵ t ( s ′ , a ′ ) ] ] − E ϵ t E s ′ [ m a x a ′ [ Q ˉ t ( s ′ , a ′ ) + ϵ t ( s ′ , a ′ ) ] ] ] \epsilon_{t+1}(s,a)=[max_{a'}[\bar{Q}_t(s',a')+\epsilon_t(s',a')]]-E_{\epsilon_t}E_{s'}[max_{a'}[\bar{Q}_t(s',a')+\epsilon_t(s',a')]]] ϵt+1(s,a)=[maxa′[Qˉt(s′,a′)+ϵt(s′,a′)]]−EϵtEs′[maxa′[Qˉt(s′,a′)+ϵt(s′,a′)]]]整理出非随机项,令 t → ∞ t\rightarrow \infty t→∞发现:
ϵ ( s , a ) = [ m a x a ′ [ Q ( s ′ , a ′ ) + ϵ ( s ′ , a ′ ) ] ] − E ϵ E s ′ [ m a x a ′ [ Q ( s ′ , a ′ ) + ϵ ( s ′ , a ′ ) ] ] ] \epsilon(s,a)=[max_{a'}[Q(s',a')+\epsilon(s',a')]]-E_{\epsilon}E_{s'}[max_{a'}[Q(s',a')+\epsilon(s',a')]]] ϵ(s,a)=[maxa′[Q(s′,a′)+ϵ(s′,a′)]]−EϵEs′[maxa′[Q(s′,a′)+ϵ(s′,a′)]]]注意到决定 ϵ ( s , a ) \epsilon(s,a) ϵ(s,a)分布的只有这一随机项 m a x a ′ [ ϵ ( s ′ , a ′ ) ] max_{a'}[\epsilon(s',a')] maxa′[ϵ(s′,a′)],并在动作连续的条件下(作者并未提及到这一点,我认为是不对的,不连续没有理由认为下式成立),根据Fisher-Tippett 极值定理得到误差分布其实近似的服从了Gumbel分布。
ϵ ( s , a ) ∝ m a x a ′ [ ϵ ( s ′ , a ′ ) ] ~ G u m b e l ( μ , β ) \epsilon(s,a)\propto max_{a'}[\epsilon(s',a')]~Gumbel(\mu,\beta) ϵ(s,a)∝maxa′[ϵ(s′,a′)]~Gumbel(μ,β)这启发了我们一个问题,我们在使用神经网络更新网络误差时,在每一个Batch下采用了如下的方案:
L o s s = 1 ∣ B a t c h ∣ ( r ( s , a ) + Q θ ( s ′ , π δ ( s ′ ) ) − Q θ ( s , a ) ) 2 Loss=\frac{1}{|Batch|}(r(s,a)+Q_\theta(s',\pi_\delta(s'))-Q_\theta(s,a))^2 Loss=∣Batch∣1(r(s,a)+Qθ(s′,πδ(s′))−Qθ(s,a))2这默认的是真实分布和预测分布之间的差异为Gauss分布,也对应着极大似然估计,但是现在我们却通过Fisher-Tippett 极值定理说明了误差分布其实是趋近于Gumbel分布而不是Gauss分布,那么该公式就不是很合适了。
2.2、Gumbel 回归分析
现在考虑一组具有Gumbel分布噪声的数据 x i x_i xi,它由下列公式构成,其中 ϵ i ~ − g ( 0 , β ) \epsilon_i~-g(0,\beta) ϵi~−g(0,β):
x i = ( h + ϵ i ) , ϵ i ~ − g ( 0 , β ) x_i=(h+\epsilon_i) ,\epsilon_i~-g(0,\beta) xi=(h+ϵi),ϵi~−g(0,β)我们的目标是想去估计出 h h h,事实上, ( h − x i ) ~ g ( 0 , β ) (h-x_i)~g(0,\beta) (h−xi)~g(0,β):
e x p [ − ( ( h − x i ) β + e x p [ − ( h − x i ) β ] ) ] = e x p [ ( ( x i − h ) β − e x p [ ( x i − h ) β ] ) ] exp[-(\frac{(h-x_i)}{\beta}+exp[-\frac{(h-x_i)}{\beta}])]=exp[(\frac{(x_i-h)}{\beta}-exp[\frac{(x_i-h)}{\beta}])] exp[−(β(h−xi)+exp[−β(h−xi)])]=exp[(β(xi−h)−exp[β(xi−h)])]最大化 E x i l o g ( p ( x i ) ) E_{x_i}log(p(x_i)) Exilog(p(xi))即最大化下式:
E x i [ [ ( ( x i − h ) β − e x p [ ( x i − h ) β ] ) ] ] E_{x_i}[[(\frac{(x_i-h)}{\beta}-exp[\frac{(x_i-h)}{\beta}])]] Exi[[(β(xi−h)−exp[β(xi−h)])]]在给定参数 β \beta β的条件下,下式可被等价为最小化(-1不影响取最大或最小)
m i n h L ( h ) = E x i [ [ − ( ( x i − h ) β + e x p [ ( x i − h ) β ] ) ] − 1 ] min_hL(h)=E_{x_i}[[-(\frac{(x_i-h)}{\beta}+exp[\frac{(x_i-h)}{\beta}])]-1] minhL(h)=Exi[[−(β(xi−h)+exp[β(xi−h)])]−1]这是凸优化问题,存在最小值,对 h h h求偏导令为0,可以得到最优的 h h h求解为:
∇ h L ( h ) = 0 → − 1 β [ e x p [ − h β ] E x i [ e x p [ x i β ] ] ] = − 1 β \nabla_hL(h)=0\rightarrow -\frac{1}{\beta}[exp[-\frac{h}{\beta}]E_{x_i}[exp[\frac{x_i}{\beta}]]]=-\frac{1}{\beta} ∇hL(h)=0→−β1[exp[−βh]Exi[exp[βxi]]]=−β1两边约去后取log
h β = l o g ( E x i [ e x p [ x i β ] ] ) → h = β l o g ( E x i [ e x p [ x i β ] ] ) \frac{h}{\beta}=log(E_{x_i}[exp[\frac{x_i}{\beta}]])\rightarrow h=\beta log(E_{x_i}[exp[\frac{x_i}{\beta}]]) βh=log(Exi[exp[βxi]])→h=βlog(Exi[exp[βxi]])这居然神奇的发现一件事情!这个 h h h的求解结果和我们在带有KL约束中求解的 V ∗ V^{*} V∗是一致的,我们来详细观察这两项:
V ∗ ( s ) = β l o g ∑ a μ ( a ∣ s ) e Q ( s , a ) β V^{*}(s)=\beta log\sum_a\mu(a|s)e^{\frac{Q(s,a)}{\beta}} V∗(s)=βloga∑μ(a∣s)eβQ(s,a)
h = β l o g ( E x i [ e x p [ x i β ] ] ) = β l o g ∑ x i p ( x i ) e x i β h=\beta log(E_{x_i}[exp[\frac{x_i}{\beta}]])=\beta log\sum_{x_i}p(x_i)e^{\frac{x_i}{\beta}} h=βlog(Exi[exp[βxi]])=βlogxi∑p(xi)eβxi这不相当于是,如果我们把x_i视为是Q(s,a)即真实的数据样本,而他又恰好满足Gumbel分布噪声条件(第二部分已经说明了这一点)。而 h h h即为我们想要预测的 V ∗ V^* V∗, p ( x i ) p(x_i) p(xi)为抽取到该样本的概率大小,若设置为 μ ( a ∣ s ) \mu(a|s) μ(a∣s),这等同于要估计的 V ∗ V^* V∗其实等价于一个Gumbel回归中的系数估计问题!,笔者认为这个思想极为巧妙,不愧是今年top5%的文章。
2.3、Gumbel 回归分析与CQL和SAC的关系
EQL思想看似与CQL毫无关联,其实不然,他们之间有了及其密切的联系,根据2.1节所讨论的。我们已经知道了下面式子中的 ϵ ( s , a ) \epsilon(s,a) ϵ(s,a)应该服从Gumbel分布,而不是Guass正态分布:
Q ^ ( s , a ) = Q ˉ ( s , a ) + ϵ ( s , a ) → r ( s , a ) + γ E s ′ [ m a x a ′ Q ^ ( s ′ , a ′ ) ] = Q ˉ ( s , a ) + ϵ ( s , a ) \hat{Q}(s,a)=\bar{Q}(s,a)+\epsilon(s,a)\rightarrow r(s,a)+\gamma E_{s'}[max_{a'}\hat{Q}(s',a')]=\bar{Q}(s,a)+\epsilon(s,a) Q^(s,a)=Qˉ(s,a)+ϵ(s,a)→r(s,a)+γEs′[maxa′Q^(s′,a′)]=Qˉ(s,a)+ϵ(s,a)若将其看作为:
r ( s , a ) + γ E s ′ , a ′ [ Q ^ ( s ′ , a ′ ) ] = Q ˉ ( s , a ) + ϵ ( s , a ) r(s,a)+\gamma E_{s',a'}[\hat{Q}(s',a')]=\bar{Q}(s,a)+\epsilon(s,a) r(s,a)+γEs′,a′[Q^(s′,a′)]=Qˉ(s,a)+ϵ(s,a)根据2.2所讨论的,我们可以通过Gumbel回归来建模估计 Q ( s , a ) Q(s,a) Q(s,a),(这里原文作者公式又写错了…):
m i n Q L ( Q ) = E s , a ~ π [ − ( ( r ( s , a ) + γ E s ′ , a ′ [ Q ^ ( s ′ , a ′ ) ] − Q ( s , a ) ) β ] + E s , a ~ μ [ e x p [ ( r ( s , a ) + γ E s ′ , a ′ [ Q ^ ( s ′ , a ′ ) ] − Q ( s , a ) ) β ] ) ] − 1 ] min_{Q}L(Q)=E_{s,a~\pi}[-(\frac{(r(s,a)+\gamma E_{s',a'}[\hat{Q}(s',a')]-Q(s,a))}{\beta}]+E_{s,a~\mu}[exp[\frac{(r(s,a)+\gamma E_{s',a'}[\hat{Q}(s',a')]-Q(s,a))}{\beta}])]-1] minQL(Q)=Es,a~π[−(β(r(s,a)+γEs′,a′[Q^(s′,a′)]−Q(s,a))]+Es,a~μ[exp[β(r(s,a)+γEs′,a′[Q^(s′,a′)]−Q(s,a))])]−1]待估计的 Q Q Q值应该满足:
∇ Q L ( Q ) = 0 → π ( a ∣ s ) β = μ ( a ∣ s ) β e x p [ ( r ( s , a ) + γ E s ′ , a ′ [ Q ^ ( s ′ , a ′ ) ] − Q ( s , a ) ) β ] ) ] \nabla_QL(Q)=0\rightarrow \frac{\pi(a|s)}{\beta}=\frac{\mu(a|s)}{\beta}exp[\frac{(r(s,a)+\gamma E_{s',a'}[\hat{Q}(s',a')]-Q(s,a))}{\beta}])] ∇QL(Q)=0→βπ(a∣s)=βμ(a∣s)exp[β(r(s,a)+γEs′,a′[Q^(s′,a′)]−Q(s,a))])]
Q ( s , a ) = r ( s , a ) + γ E s ′ , a ′ [ Q ^ ( s ′ , a ′ ) ] − β l o g π ( a ∣ s ) μ ( a ∣ s ) Q(s,a)=r(s,a)+\gamma E_{s',a'}[\hat{Q}(s',a')]-\beta log\frac{\pi(a|s)}{\mu(a|s)} Q(s,a)=r(s,a)+γEs′,a′[Q^(s′,a′)]−βlogμ(a∣s)π(a∣s)这即从回归中自然地得到了带有KL损失的Q值更新方式!
若使用软Bellman算子(soft-Bellman operator) B ∗ B^* B∗,依然的可以得到在下损失函数:
m i n Q L ( Q ) = E s , a ~ μ [ − ( ( r ( s , a ) + γ E s ′ , a ′ [ Q ^ ( s ′ , a ′ ) ] − Q ( s , a ) ) β ] + E s , a ~ μ [ e x p [ ( r ( s , a ) + γ E s ′ , a ′ [ Q ^ ( s ′ , a ′ ) ] − Q ( s , a ) ) β ] ) ] − 1 ] min_{Q}L(Q)=E_{s,a~\mu }[-(\frac{(r(s,a)+\gamma E_{s',a'}[\hat{Q}(s',a')]-Q(s,a))}{\beta}]+E_{s,a~\mu}[exp[\frac{(r(s,a)+\gamma E_{s',a'}[\hat{Q}(s',a')]-Q(s,a))}{\beta}])]-1] minQL(Q)=Es,a~μ[−(β(r(s,a)+γEs′,a′[Q^(s′,a′)]−Q(s,a))]+Es,a~μ[exp[β(r(s,a)+γEs′,a′[Q^(s′,a′)]−Q(s,a))])]−1]进而同理的可以得到这样的Q更新方法:
Q k + 1 ( s , a ) = B ∗ Q k ( s , a ) Q^{k+1}(s,a)=B^*Q^k(s,a) Qk+1(s,a)=B∗Qk(s,a)但是这仍旧需要通过采样的办法来估计 V ∗ V^* V∗,根据我们上面的讨论可以知道
B ∗ Q ( s , a ) = r ( s , a ) + E s ′ ~ T [ β l o g ∑ a μ ( a ∣ s ′ ) e Q ( s ′ , a ) β ] = r ( s , a ) + E [ V ∗ ( s ′ ) ] B^*Q(s,a)=r(s,a)+E_{s'~T}[\beta log\sum_a\mu(a|s^{'})e^{\frac{Q(s^{'},a)}{\beta}}]=r(s,a)+E[V^*(s')] B∗Q(s,a)=r(s,a)+Es′~T[βloga∑μ(a∣s′)eβQ(s′,a)]=r(s,a)+E[V∗(s′)]我们其实一直知道了,如果使用Gumbel回归直接建立 V ∗ V^* V∗和 Q ^ k \hat{Q}^k Q^k的联系,便是我们想要的最优值。那么其实 V ∗ V^* V∗可以通过 Q ^ k \hat{Q}^k Q^k来直接进行Gumbel回归建立。
m i n V ∗ L ( V ∗ ) = E s , a ~ μ [ − ( ( r ( s , a ) + γ E s ′ , a ′ [ Q ^ ( s ′ , a ′ ) ] − Q ( s , a ) ) β ] + E s , a ~ μ [ e x p [ ( r ( s , a ) + γ E s ′ , a ′ [ Q ^ ( s ′ , a ′ ) ] − Q ( s , a ) ) β ] ) ] − 1 ] min_{V^*}L(V^*)=E_{s,a~\mu }[-(\frac{(r(s,a)+\gamma E_{s',a'}[\hat{Q}(s',a')]-Q(s,a))}{\beta}]+E_{s,a~\mu}[exp[\frac{(r(s,a)+\gamma E_{s',a'}[\hat{Q}(s',a')]-Q(s,a))}{\beta}])]-1] minV∗L(V∗)=Es,a~μ[−(β(r(s,a)+γEs′,a′[Q^(s′,a′)]−Q(s,a))]+Es,a~μ[exp[β(r(s,a)+γEs′,a′[Q^(s′,a′)]−Q(s,a))])]−1]
m i n V ∗ L ( V ∗ ) = E s , a ~ μ [ [ − ( ( Q k ( s , a ) − V ( s ) ) β + e x p [ ( Q k ( s , a ) − V ( s ) ) β ] ) ] − 1 ] min_{V^{*}}L(V^*)=E_{s,a~\mu}[[-(\frac{(Q^k(s,a)-V(s))}{\beta}+exp[\frac{(Q^k(s,a)-V(s))}{\beta}])]-1] minV∗L(V∗)=Es,a~μ[[−(β(Qk(s,a)−V(s))+exp[β(Qk(s,a)−V(s))])]−1]求解得到的最优 V ∗ ( s ) = β l o g ∑ a μ ( a ∣ s ) e Q k ( s , a ) β V^{*}(s)=\beta log\sum_a\mu(a|s)e^{\frac{Q^k(s,a)}{\beta}} V∗(s)=βlog∑aμ(a∣s)eβQk(s,a),这样回避了熵的问题而避免进行采样。
3、极值Q学习算法原理与实现
3.1、策略选择
上述笔者只讲到了如何做 Q Q Q的更新,但是一直没有提出如何做关于策略 π \pi π的更新,在这里注意到在1中已经提到过的式子:
π ∗ ( a ∣ s ) = μ ( a ∣ s ) e Q ( s , a ) − V ∗ ( s ) β \pi^*(a|s)=\mu(a|s)e^{\frac{Q(s,a)-V^*(s)}{\beta}} π∗(a∣s)=μ(a∣s)eβQ(s,a)−V∗(s)那么
π ∗ ( a ∣ s ) = a r g m a x π E μ ( a ∣ s ) [ e Q ( s , a ) − V ∗ ( s ) β l o g π ] \pi^*(a|s)=argmax_\pi E_{\mu(a|s)}[e^{\frac{Q(s,a)-V^*(s)}{\beta}}log\pi] π∗(a∣s)=argmaxπEμ(a∣s)[eβQ(s,a)−V∗(s)logπ]即 π \pi π取到能够使得概率最大的,即若有某个 μ ( a ∣ s ) e Q ( s , a ) − V ∗ ( s ) β \mu(a|s)e^{\frac{Q(s,a)-V^*(s)}{\beta}} μ(a∣s)eβQ(s,a)−V∗(s)最大,那么对应的就为那个策略,至于作者为什么采用 l o g π log\pi logπ而不采用 π \pi π,我想是为了对齐后续公式,若将 μ \mu μ取成原始的数据分布采样的分布,那么这即为
π ∗ ( a ∣ s ) = a r g m a x π E π β [ e Q ( s , a ) − V ∗ ( s ) β l o g π ] \pi^*(a|s)=argmax_\pi E_{\pi_\beta}[e^{\frac{Q(s,a)-V^*(s)}{\beta}}log\pi] π∗(a∣s)=argmaxπEπβ[eβQ(s,a)−V∗(s)logπ]这将避免在分布外的动作进行选择从而超出分布限制。
如果我们想去抽样分布外的操作(网络的实时分布)而不是从已有动作 π ^ \hat{\pi} π^中进行采样,那么可以参考和SAC一样的办法来采样动作:( μ \mu μ可以取成当前最新的动作或者上一个动作如 π k \pi_k πk)
π ∗ ( a ∣ s ) = a r g m a x π E π ^ [ Q ( s , a ) − β l o g ( π ( a ∣ s ) μ ( a ∣ s ) ) ] \pi^*(a|s)=argmax_\pi E_{\hat{\pi}}[Q(s,a)-\beta log(\frac{\pi(a|s)}{\mu(a|s)})] π∗(a∣s)=argmaxπEπ^[Q(s,a)−βlog(μ(a∣s)π(a∣s))]
3.2、算法实现
1.初始化网络参数 Q θ , V δ , π α Q_\theta,V_\delta,\pi_\alpha Qθ,Vδ,πα和数据集 D D D.
2.从数据集 D D D中抽取一个Batch出来进行Training(OffLine情况下)或者从Online条件下进行实时收集一个进入到Reply-Buffer中。 ( s , a , r , s ′ ) (s,a,r,s') (s,a,r,s′)
3.执行计算 L ( Q ) L(Q) L(Q)并更新 Q θ Q_\theta Qθ
L ( Q ) = E s , a , s ′ [ ( Q θ ( s , a ) − r ( s , a ) − γ V δ ( s ′ ) ) 2 ] L(Q)=E_{s,a,s'}[(Q_\theta(s,a)-r(s,a)-\gamma V_\delta(s'))^2] L(Q)=Es,a,s′[(Qθ(s,a)−r(s,a)−γVδ(s′))2]4.执行计算 L ( V ) L(V) L(V)并更新 V δ V_\delta Vδ
L ( V ) = E s , a ~ D [ [ − ( ( Q θ ( s , a ) − V δ ( s ) ) β + e x p [ ( Q θ ( s , a ) − V δ ( s ) ) β ] ) ] − 1 ] ( O f f l i n e ) L(V)=E_{s,a~D}[[-(\frac{(Q_\theta(s,a)-V_\delta(s))}{\beta}+exp[\frac{(Q_\theta(s,a)-V_\delta(s))}{\beta}])]-1](Offline) L(V)=Es,a~D[[−(β(Qθ(s,a)−Vδ(s))+exp[β(Qθ(s,a)−Vδ(s))])]−1](Offline)
L ( V ) = E s , a ~ π α [ [ − ( ( Q θ ( s , a ) − V δ ( s ) ) β + e x p [ ( Q θ ( s , a ) − V δ ( s ) ) β ] ) ] − 1 ] ( O n l i n e ) L(V)=E_{s,a~\pi_\alpha}[[-(\frac{(Q_\theta(s,a)-V_\delta(s))}{\beta}+exp[\frac{(Q_\theta(s,a)-V_\delta(s))}{\beta}])]-1](Online) L(V)=Es,a~πα[[−(β(Qθ(s,a)−Vδ(s))+exp[β(Qθ(s,a)−Vδ(s))])]−1](Online)5.执行计算 L ( π ) L(\pi) L(π)并更新 π α k \pi_\alpha^{k} παk(代表第k次更新)
L ( π ) = − E s , a ~ D [ e Q θ ( s , a ) − V δ ( s ) β l o g π α ] ( O f f l i n e ) L(\pi)=-E_{s,a~D}[e^{\frac{Q_\theta(s,a)-V_\delta(s)}{\beta}}log\pi_\alpha](Offline) L(π)=−Es,a~D[eβQθ(s,a)−Vδ(s)logπα](Offline)
L ( π ) = − E s , a ~ π α k [ Q ( s , a ) − β l o g ( π α k ( a ∣ s ) π α k − 1 ( a ∣ s ) ) ] L(\pi)=-E_{s,a~\pi_\alpha^k}[Q(s,a)-\beta log(\frac{\pi_\alpha^k(a|s)}{\pi_\alpha^{k-1}(a|s)})] L(π)=−Es,a~παk[Q(s,a)−βlog(παk−1(a∣s)παk(a∣s))]6.重复2~5直到网络收敛为止