导读
论文:《Focusing on Hard Instance for 3D Object Detection》
今天介绍的FocalFormer3D方法核心是围绕False Negatives, FN即假阴性进行展开的。众所周知,假阴性在 3D 物体检测中是一个严重问题,特别是在自动驾驶环境中,例如对行人、车辆或其他障碍物的检测失误可能导致潜在的危险情况(想象下把一个人识别成路面会是怎样一种情况?)。
为此,文章作者们提出了一种名为困难实例探测(Hard Instance Probing, HIP)的方法,专注于挖掘难以检测的实例(名字有点绕口,与“困难样本挖掘”有何区别?后面揭晓)。这一方法逐渐探测假阴性样本,显著提高了召回率。HIP 在每个阶段都压制真正的阳性候选项,并关注前一阶段的假阴性候选项。通过迭代 HIP 阶段,该方法能够挽救那些难以识别的假阴性样本。
基于 HIP,本文引入了一种 3D 物体检测器FocalFormer3D。特别是,通过多阶段热图预测来挖掘困难的实例,并通过类别感知的积累正面掩码(class-aware Accumulated Positive Mask)来集中关注困难实例。最后,解码器从所有阶段收集正面预测以产生物体候选项。
此外,论文还引入了一个 box-level 的细化步骤,用于消除冗余物体候选项。通过使用 RoIAlign 将候选项表示为目标框级别的查询,允许 box-level 查询交互和迭代目标框细化,从而在俯视图上执行相对边界框细化。
因此,FocalFormer3D可以理解为就是一种专门用于挖掘困难样本并提高预测召回率的 3D 目标检测器。最终,实验结果也表明了该方法在nuScenes和Waymo两个主流的自动驾驶场景数据集上取得了不错的表现,模型在LiDAR和多模态设置上实现了最先进的检测性能,尤其在nuScenes 3D LiDAR检测和追踪排行榜上排名第一。
动机
先贴出原文首页的一张图,我们一起看下:
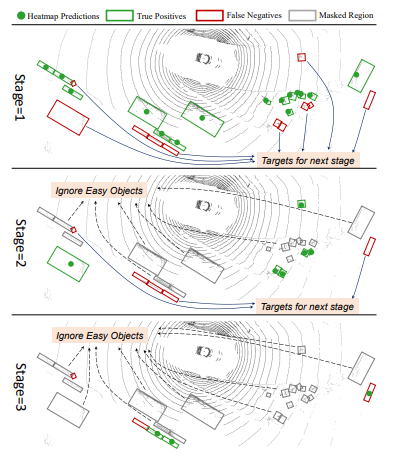
上图大致描绘了FocalFormer3D的多阶段预测方法是如何工作的。首先是多阶段预测方法,这使得模型可以逐渐集中精力关注那些难以检测的实例,并促进其检测率的提升。接着,我们可以了解下每个阶段的操作:
- 产生正面物体候选项:在每个阶段,模型会生成一些正例物体候选项(图中用绿色圆圈表示)。
- 分类为真阳性或假阴性:在训练期间,分配给基准事实对象的物体候选项可以被分类为真阳性(TP,用绿色框表示)和假阴性(FN,用红色框表示)。
- 处理困难实例:未匹配的基准事实对象被明确建模为困难实例,并成为下一阶段的主要目标。
- 处理容易样本:相反地,阳性样本被认为是容易样本(图中用灰色框表示),并且在后续阶段的训练和推理时间内都将被忽略。
最终,所有的热图预测会被收集起来作为初始的物体候选项,而假阳性则被忽略,以便更好地进行可视化。这种方法强调了对困难实例的处理,从而改善了模型对难以检测物体的性能。
方法

如上图所示,FocalFormer3D的整体架构结合了两个主要部分:多阶段热图编码器和可变形Transformer解码器,它们共同工作来检测和精确地识别场景中的物体。编码器部分集中精力关注困难实例并生成高召回率的候选项,而解码器部分则进一步精确筛选候选项,消除假阳性。这个结构专注于找到困难的案例,特别是在复杂的情况下,这些情况下可能会有大量的遮挡和背景混乱,从而实现更准确和可靠的3D对象检测。
困难实例探测
上面我们提到过,在实际应用中,例如自动驾驶,通常都需要高度的场景理解以确保安全和可靠的操作。特别是,在目标检测中的假阴性可能带来严重的风险,强调了高召回率的需求。然而,在复杂场景或遮挡发生时准确识别物体在3D对象检测中具有挑战性,导致许多假阴性预测。以往很少有研究专门关注在检测头的设计中解决假阴性问题。
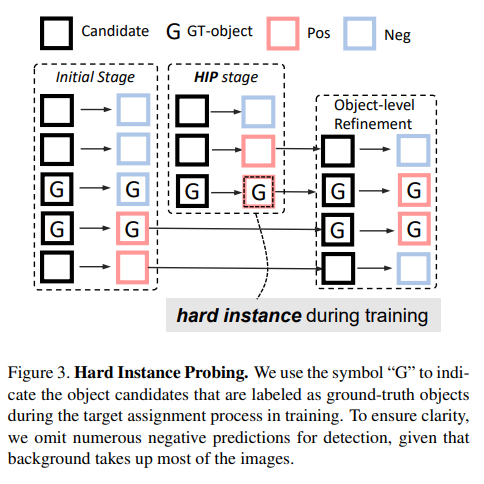
从上图的整体框架图不难看出,HIP 是一种分阶段操作的策略,用于识别困难的实例。通过一系列“过滤”,将GT 标注为初始阶段的主要目标,并将其与初始的对象候选集进行比较。与 HIP 方法最相关的必定是困难样本挖掘,即在训练期间采样困难样本。不过,HIP 与困难样本挖掘不同,HIP 是采用阶段性的操作,特别是使用先前阶段的假阴性预测来引导模型的后续阶段学习这些具有挑战性的对象,可以简单认为是一个coarse-to-fine的操作。
Multi-stage Heatmap Encoder
在常见的实践中,BEV heatmap的目的是在检测对象的中心位置产生热图峰值。BEV 热图表示为一个张量 S ∈ R X × Y × C S \in R^{X \times Y \times C} S∈RX×Y×C,其中 X × Y X \times Y X×Y 表示 BEV 特征图的大小, C C C则是目标类别的数量。最后,通过在 BEV 对象点附近生成2D高斯,达到目标,这些点通过将3D框中心投影到地图视图上获得。此外,由于目标在 BEV 视图上没有同类重叠,因此可以直接通过从 BEV heatmap 预测中排除先前的简单正样本候选来轻松实现基于非重叠假设的掩码。
为了跟踪先前阶段的所有简单正对象候选,每个阶段在BEV空间上生成一个正向掩码(PM),并将它们累积到 APM 中,初始化为全零。通过在阶段之间使用轻量级的反向残差块,以级联方式完成多阶段BEV特征的生成。同时,在每个阶段,根据正预测生成正掩码。最后,再将 S k = S k ⋅ ( 1 − M k ) S^{k} = S_{k} \cdot (1 - M^{k}) Sk=Sk⋅(1−Mk),以便在当前阶段省略先前的简单正区域,从而使模型专注于先前阶段的假阴性样本即困难实例。

下面我们简单分析下不同的 mask 方法:
Point Masking: 即只填充正候选的中心点。Pooling-based Masking:即较小的对象填充中心点,较大的对象使用3×3的内核大小填充。Box Masking:要额外的框预测分支,并填充预测的BEV框的内部区域。
虽然HIP策略很简单,但掩码方式需要满足两个关键标准,以确保HIP的有效实施:
- 排除当前阶段的先前正例目标候选。
- 避免移除潜在的真实对象(假阴性)。

点掩码满足这两个要求,但与使用 GT 框指导的理想掩码相比,它效率较低,因为每个正预测仅排除一个BEV对象候选。因此,在掩码区域和排除操作的有效性之间存在权衡。最后,通过消融实验综合比较三种策略,Pooling-based Masking表现最好。
Box-level Deformable Decoder
解码器部分详细描述了如何处理和细化目标候选。其中一个关键技术是使用可变形注意力,与计算密集的交叉注意力或框注意力相比,效率明显是提升了。box-pooling模块通过在常规网格方式中提取BEV特征的框上下文信息,增强了目标和局部区域之间的关系建模。此外,解码器实现还包括多个头部和尺度的可变形注意力,以及特殊的下采样和扩展操作,以适应不同的特征和对象大小。通过这些技术,解码器提供了精确和高效的3D对象检测和细化。
实验

上述实验结果从侧面验证了FocalFormer3D的优越性。特别在 LiDAR 基础的 3D 目标检测和多模态 3D 目标检测方面,该模型均取得了显著的性能提升,并在一些罕见类别上也取得了很高的结果。可以看出,即使与使用分割级别标签训练的SOTA方法相比,该方法在没有额外监督的情况下仍然优于LiDARMultiNet,mAP提高了+1.7,NDS提高了+1.0。
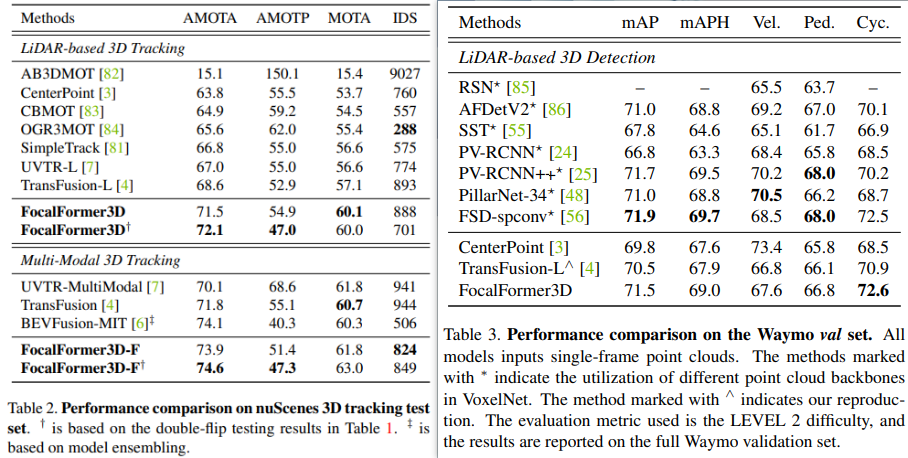
上图简单展示了 FocalFormer3D 在 3D 多目标跟踪(MOT)和 Waymo LiDAR 3D 目标检测方面的应用。这些实验进一步展示了 FocalFormer3D 的多功能性,不仅在 3D 目标检测方面性能优异,还可以扩展到3D多目标跟踪,并在不同的数据集上展示竞争力。这一结果突显了 FocalFormer3D 在深度学习和3D感知任务中的广泛应用潜力。
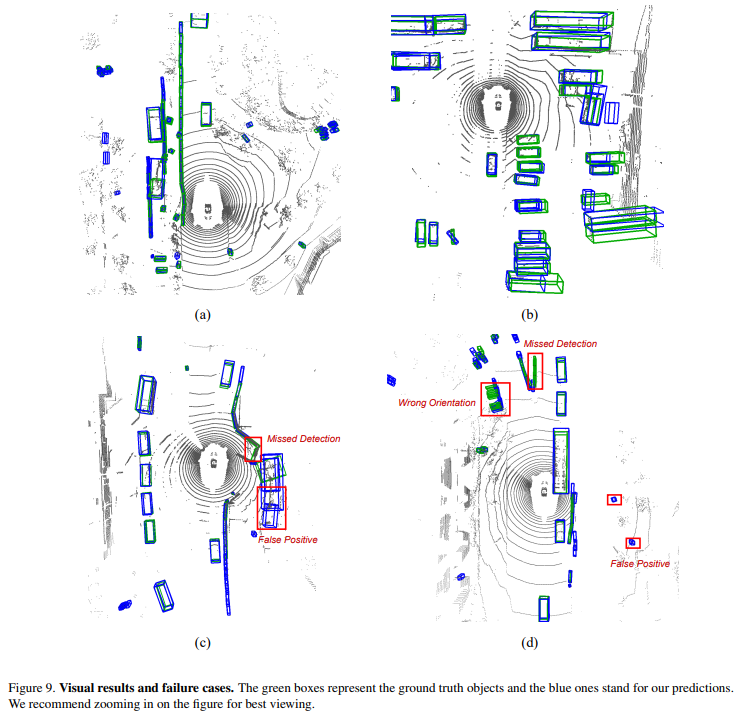
总结
本工作明确关注自动驾驶中的一个致命问题,即假阴性检测。为此,作者提出了FocalFormer3D作为解决方案。通过引入困难实例探测(HIP),逐渐探测困难实例并提高预测召回率。在基于Transformer的3D检测器上以有限的额外开销获得了显著提升。