作者:HT | 来源:3D视觉工坊
在公众号「3D视觉工坊」后台,回复「原论文」即可获取论文pdf。
添加微信:dddvisiona,备注:3D点云,拉你入群。文末附行业细分群。
一、笔者个人体会
文章的主要动机是解决点云数据处理中的挑战性问题。点云数据具有复杂的非欧几里德结构,包含了全局和局部的几何信息,而现有的方法在提取点云的复杂几何结构以进行分类任务时存在局限。因此,作者的动机是提出一种新的方法,可以更有效地捕捉点云数据的多尺度几何信息,从而提高点云分类的性能。
核心创新点是引入了多尺度几何感知Transformer(MGT)模型。MGT模型通过以下方式创新:
多尺度贴片分割:将点云数据分成不同尺寸的多尺度小块,以便探索点云的多尺度结构。
几何感知的补丁内表示:引入了一个局部特征提取器(
SLFE)模块,利用球面映射来提取每个补丁的几何信息。几何感知的补丁间表示:使用基于测地线距离的自注意机制来捕捉补丁之间的全局特征。
该算法方法的好处:
提高了点云分类任务的性能,使其在主流基准测试中具有竞争力。
可以更好地捕捉点云的多尺度几何结构,从而提高了点云数据的表示能力。
具有较强的鲁棒性,对于点云数据的缺失也能保持较好的性能。
引入了更合理的几何感知方法,以适应点云数据的非欧几里德结构。
为点云数据处理领域带来了一种新的方法,可能有助于解决其他点云相关任务的挑战。
二、摘要
自注意模块在捕获远程关系和提高点云任务性能方面表现出了卓越的能力。然而,点云对象通常具有复杂、无序和多尺度的非欧几里得空间结构,其行为往往是动态的和不可预测的。目前的自注意模块大多依赖于查询键值特征之间的点积乘法和维度对齐,无法充分捕捉点云对象的多尺度非欧几里德结构。这里也推荐「3D视觉工坊」新课程《彻底搞懂基于Open3D的点云处理教程!》。
为了解决这些问题,本文提出了一种自注意插件模块及其变体——多尺度几何感知Transformer (Multi-scale geometric -aware Transformer, MGT)。MGT从以下三个方面处理具有多尺度局部和全局几何信息的点云数据。
首先,
MGT将点云数据分成多个尺度的小块。其次,提出了一种基于球面映射的局部特征提取器,对每个斑块内部的几何形状进行挖掘,并生成每个斑块的定长表示;
第三,将固定长度表示输入到一种新的基于测地线的自注意中,以捕获斑块之间的全局非欧几里得几何。
最后,通过端到端的训练方案,将所有模块集成到
MGT框架中。
实验结果表明,MGT极大地提高了利用自注意机制捕获多尺度几何的能力,并在主流点云基准测试中取得了较强的竞争力。
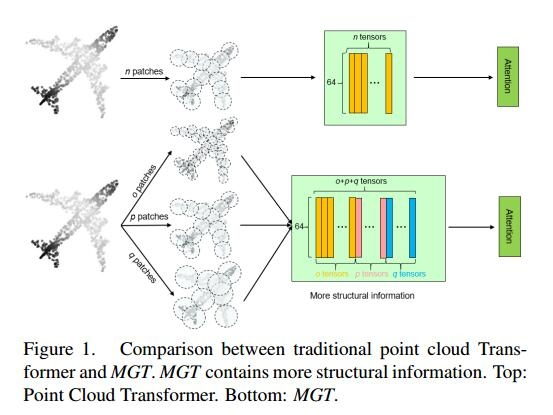
三、前言
点云数据是自动驾驶、增强现实和机器人等领域广泛使用的 3D 数据形式。然而,与传统图像不同,点云数据具有复杂的全局和局部结构,本质上是非欧几里德结构,这使得在实际应用中提取特征具有挑战性。为了应对这一挑战,研究人员提出了各种基于深度学习的 3D 点云分类方法,可分为基于体素的方法、多视图方法和点集方法。
基于体素的方法通常会破坏测量空间中的重要空间关系。
多视图方法将3D云数据投影到2D图像中,导致模型无法完全捕获几何信息和空间关系。
PointNet是点集方法的先驱,它对每个点使用空间编码,例如多层感知器(MLP)和具有共享权重的池化层,来收集点集特征。
尽管在之前的工作中尝试增强这些技术,但它们捕获局部特征变化的能力仍然有限。因此,所有这些算法都无法完全提取点云的复杂几何结构进行分类。
传统的数据处理方法已经不足以处理点云对象复杂的非欧几里得结构。目前,需要一种功能强大的特征提取器Transformer来增强点云的几何形状,提高局部特征提取能力,同时利用Transformer强大的全局特征获取能力。
为此,本文提出了一种新的Transformer,称为多尺度几何感知变压器(Multi-Scale geometric -aware Transformer, MGT),用于提取点云中的复杂几何结构进行分类。MGT将点云数据划分为多个不同数量和大小的patch,从而获得多个尺度的点云特征。图1显示了传统单尺度点云Transformer与MGT的对比。
此外,该自注意方法在自注意模块中使用测地线距离代替点积乘法,更合理地处理点云数据。图4提供了点积注意和测地线注意之间的简单比较。
此外,本文提出了一种基于球面映射算法的共享局部特征提取器(
SLFE)模块,采用更适合点云数据的特征提取算法提取点云特征。
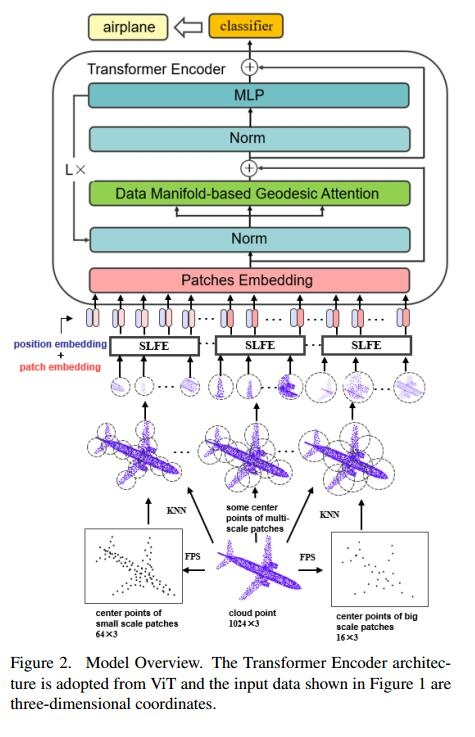
四、贡献
• 多尺度贴片分割Transformer。MGT将点云数据分成不同尺寸的多尺度小块,即从小块到大块,并将其送入Transformer中,探索点云结构的多尺度。
• 几何感知的补丁内表示。本文提出了一个SLFE模块,该模块增强了补丁内的局部特征,并为每个补丁输出固定长度的向量。在SLFE模块中,提出了一种新的算子,称为球体映射,用于捕获斑块邻居的局部几何结构,即斑块中点之间的夹角。
• 几何感知的补丁间表示。采用了一种新的基于计算测地线距离的自注意机制来更好地捕捉斑块之间的全局特征。
五、MGT框架
通过划分的多尺度补丁,图 2 描述了 MGT 模型的流程,该模型组装了两个基本模块。
首先,用于每个补丁的几何感知特征提取的补丁内表示模块。
其次,用于学习多尺度补丁的基于流形的自注意力的补丁间表示模块。
前者提取局部几何特征并为每个斑块生成固定长度的不变表示向量,后者探索多尺度斑块之间的非欧几里得关系。前者是通过与球体映射模块关联的开发的本地共享特征提取器来实现的,而基于流形的自注意力模块则实现了后者。
多尺度补丁划分
在MGT模型的第一层中,执行多尺度补丁划分。如图2所示。
对于应用多尺度patch划分,确定每个patch的中心至关重要。使用最远点采样(FPS),选择 η 个点作为中心点,,其中η表示patch的多个尺度。给定一个中心点,使用K−近邻算法(KNN)选择最近的η个点,形成大小为的点云补丁。因此, 表示具有从小到大的多个尺度/大小的所有斑块的集合。
补丁大小 η 根据基于所使用的数据集的不同实现设置而变化。例如,在数值实验中,我们为每个补丁设置4种尺度/大小,例如,补丁大小η , 同种尺度 η , 对应的补丁数量 η 。
最后,对于第 η 尺度的点云patch,patch中心和patch可以表示为:
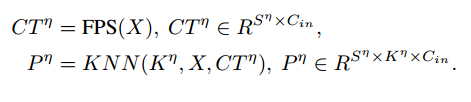
六、算法解析
几何感知的片内表示
在处理不同尺度的补丁时,一项关键任务是设计一个特征提取器,为每个补丁生成固定长度的表示。为了解决这个问题,作者开发了一个统一的共享局部特征提取器(SLFE)来提取所有尺度的补丁的固定长度的几何感知特征。
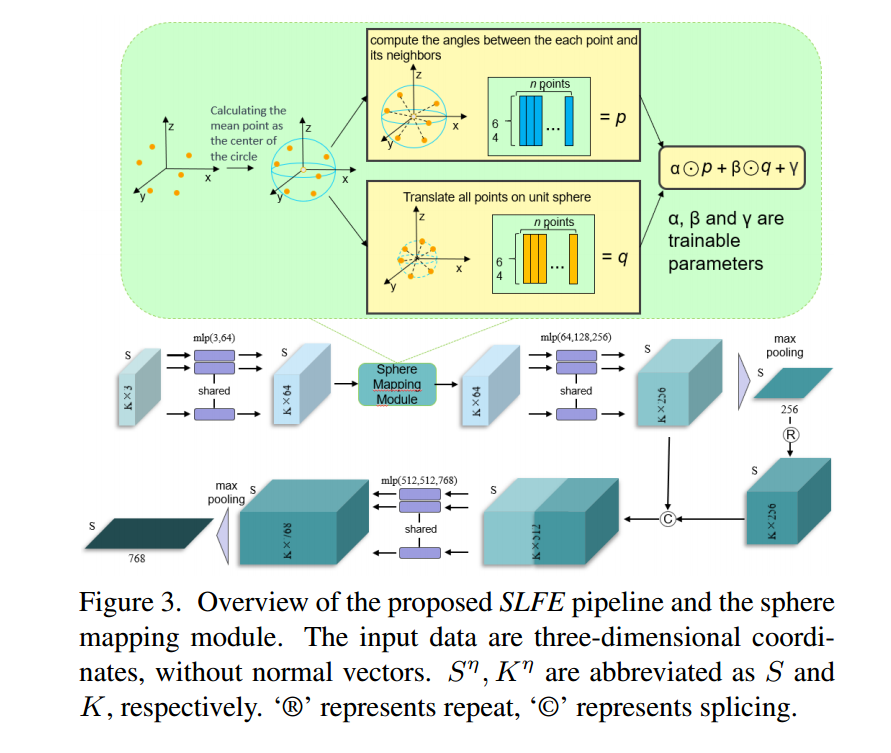
受PointNet及其变体的启发,作者开发了SLFE模块。
如图3所示,可以从两个方面得出结论:
(1)提出了一种新颖的局部几何提取器——球体映射,来提取补丁的几何感知结构。
(2)提出了一种称为SLFE的pipeline。
直观上,如图3所示,中期的S个补丁的特征聚合,即补丁中每个点的K个邻居的MaxPooling,使得补丁的特征更加突出,并且其语义信息更容易被识别。
球体映射
由于点云具有很强的非欧几何特性,因此在欧几里德空间中正确捕获其几何特征具有挑战性。在 SLFE 模块中,作者提出了一种新颖的球体映射,如图 3 所示,将点云特征映射到球体空间,以便更好的几何分析。
然后使用以下公式将邻居点转换为球体:
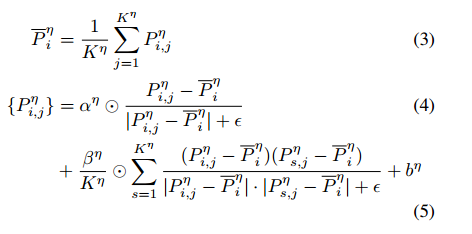
通过球体映射模块,将补丁的邻居的局部几何结构映射到球体。因此,可以以更有效的方式提取点之间的几何关系(角度)。因此,有效地提取了斑块的几何特征。
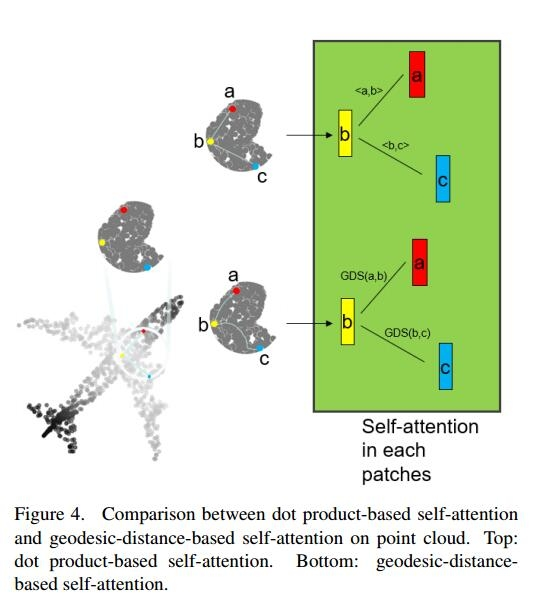
几何感知的面片间表示
在自注意力计算之前,连接类标签并对嵌入特征进行位置编码,以实现更好的收敛。与BERT和ViT中类似,随机初始化一个可学习的类标记,然后将其与点云嵌入Ep拼接以获得总序列:
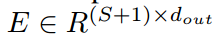
在原始的Transformer中,应用了位置编码模块来表示自然语言中的顺序,可以反映单词之间的位置关系。在本文中,为了反映点云块之间的位置关系,作者还在嵌入的点云中添加位置编码以保留位置信息。
考虑到点云数据本身具有位置信息,使用每个点云面片的中心点坐标来表示每个点云面片的位置信息。具体来说,将类标签随机初始化,然后与每个点云补丁的中心点坐标进行拼接,然后使用学习到的MLP层将中心点坐标映射到嵌入维度,然后得到位置编码:

Transforme编码器
为了提取非欧几里得补丁间关系,实现基于流形的自注意力来修改自注意力模块。假设,对于点云这种典型的非欧数据,应该利用其特征点之间的测地距离而不是欧几里德空间中的内积来捕获其相对关系。对于输入序列z,将欧几里得空间中的原始特征投影到斜流形上,即用OM表示的单位长度球体,并计算嵌入在斜流形上的补丁特征的测地自注意力。投影函数Proj(·)可描述为:
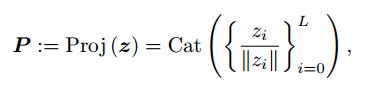
投影后,输入点对的测地距离可以计算为:
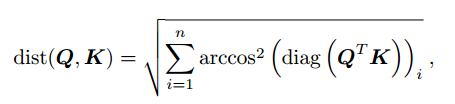
因此,MGT模块的输出可以计算为:
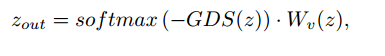
然后,将第获得的位置编码的序列 z0 输入到前面提到的 L 层(LN 表示 LayerNorm)的 Transformer Encoder 中。具体流程如下:
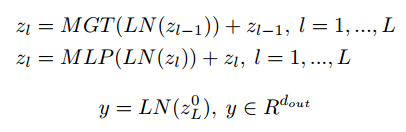
七、实验
作者在几个基准上评估了提出的 MGT 框架的多类分类性能。在消融研究中,对 MGT 框架的有效性进行定性和定量评估。
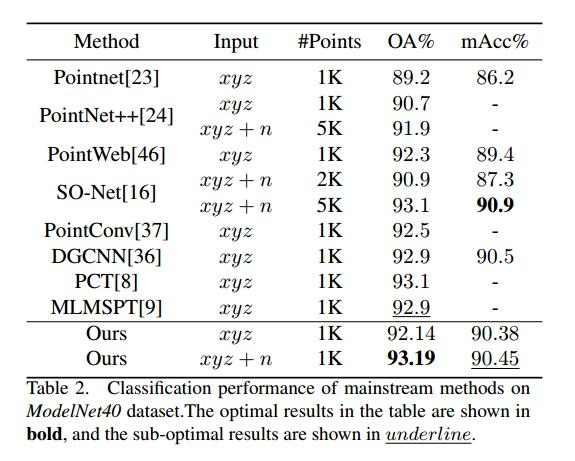
作者使用标签平滑交叉熵损失函数。batch-size和epoch数分别设置为 32 和 250。使用SGD优化器和CosineAnnealingLR来调整学习率,初始学习率为0:02。机器配置如表1所示。此外,总体准确率(OA)和类平均准确率(mAcc)被用作分类的性能评估标准。除非实验研究中明确说明,否则输入1024(1K)个点,并且不采用法向量作为原始点特征。

为了验证所提出方法的有效性,将其与一些主流方法进行比较。Modelnet40和ScanobjectNN数据集上的结果分别如表2和表3所示(xyz为坐标,n为法向量)。表2和表3的实验结果表明,与一些主流方法相比,所提出的方法表现出了非常有竞争力的结果。在Modelnet40数据集上,算法在OA和mAcc指标上分别达到了93.19%和90.45%。两个基准数据集上的强有力的竞争结果表明了所提出的方法与上述基线相比的有效性.

使用原始PointNet和SLFE对比实验结果。表4的实验结果表明,单个SLFE只有0.31M参数,但在OA和mAcc上使用SLFE的结果分别比使用PointNet的结果高2.51%和2.71%。这里也推荐「3D视觉工坊」新课程《彻底搞懂基于Open3D的点云处理教程!》。
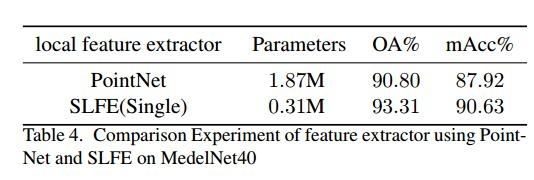
这表明所开发的 SLFE 作为局部特征提取器是有效的。消融实验,在 Modelnet40 数据集上的测试结果,表 5 讨论了模块中 SLFE 的必要性。根据表中消融实验结果分析,A在不添加Sphere Mapping模块和最大池化模块的情况下,结果最差。直观上来说,中期是对每个点云进行特征聚合。

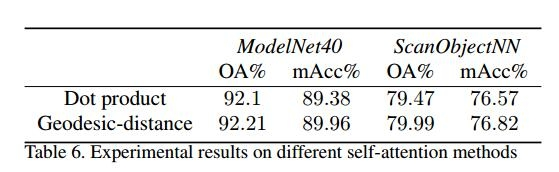
此外,详细讨论了基于测地距离的自注意力机制对实验结果的影响。在表6中,比较了使用点积的传统自注意力机制和基于测地距离的自注意力机制的实验结果。表中的实验结果表明,使用基于测地距离的自注意力机制改善了 Modelnet40 和 ScanobjectNN 数据集上的结果。
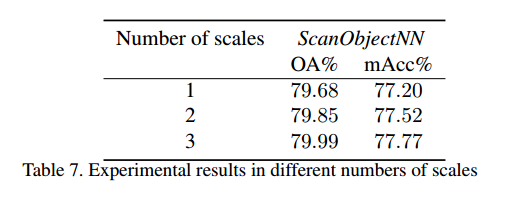
此外,还探讨了尺度数量对分类精度的影响。表7展示了多尺度划分中点云数据划分为不同尺度对实验结果的不同影响。实验中使用的是ScanobjectNN数据集。
本文选择PointNet和Pointnet++作为对比来测试点云丢失(缺失点的数据)的鲁棒性。如图5所示,当使用最远点采样使测试集的点云数据损失50%(即保留512个点)时,准确率仅下降0.6%,低于1 Pointnet++和Pointnet的下降分别为:8%和2.4%。
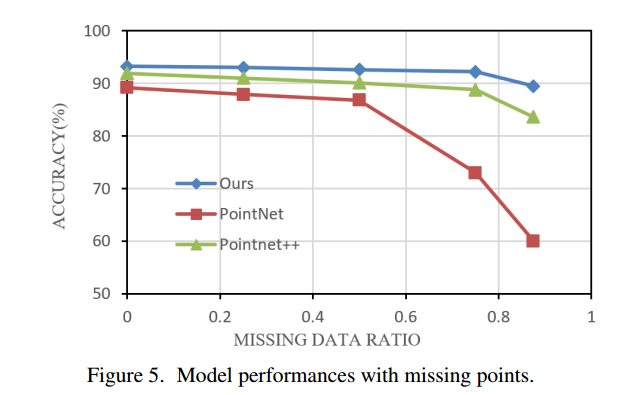
当丢失点的比例为87.5%(即保留128个点)时,本文算法仍然可以达到89.5%的优异精度,而Pointnet++为83.6%,而PointNet只能准确率达到60%,但准确率明显下降。这表明该方法对缺失点的点云数据具有较强的鲁棒性。实验表明,当识别模型能够利用点云的局部信息时,对于点云数据的丢失(缺失点)具有更强的鲁棒性。
八、总结
为了探索隐藏在点云中的复杂几何结构,本文提出了一种新颖的 Transformer 框架 MGT,用于点云对象的分类。
首先,将数据划分为不同尺寸的多尺度斑块,即从小尺寸到大尺寸的斑块,以探索点云结构的多个尺度。然后,构建了一个几何感知Transformer模型,该模型利用两级几何结构,即每个块内的欧几里得几何结构和点云块间的非欧几里得几何结构。前者是通过与新颖的球体映射模块关联的本地共享特征提取器来实现的,而后者是使用基于流形的自注意力模块来实现的。
与主流方法相比,该方法在点云识别上的准确率表现出较强的竞争力,并且面对数据点丢失具有良好的鲁棒性。
—END—高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向,细分群包括:[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。[三维重建方向]NeRF、colmap、OpenMVS等。除了这些,还有求职、硬件选型、视觉产品落地等交流群。大家可以添加小助理微信: dddvisiona,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 加入知识星球,问题及时得到解答
针对3D视觉领域的视频课程(三维重建、三维点云、结构光、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业、项目对接为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:「3D视觉从入门到精通」
学习3D视觉核心技术,扫描查看,3天内无条件退款
第三步 系统学习3D视觉,对模块知识体系,深刻理解并运行
如果大家对3D视觉某一个细分方向想系统学习[从理论、代码到实战],推荐3D视觉精品课程学习网址:www.3dcver.com
科研论文写作:
基础课程:
[1]面向三维视觉算法的C++重要模块精讲:从零基础入门到进阶
[2]面向三维视觉的Linux嵌入式系统教程[理论+代码+实战]
工业3D视觉方向课程:
[1](第二期)从零搭建一套结构光3D重建系统[理论+源码+实践]
SLAM方向课程:
[1]深度剖析面向机器人领域的3D激光SLAM技术原理、代码与实战
[1]彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战
[2](第二期)彻底搞懂基于LOAM框架的3D激光SLAM:源码剖析到算法优化
[3]彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析
[4]彻底剖析室内、室外激光SLAM关键算法和实战(cartographer+LOAM+LIO-SAM)
视觉三维重建
[1]彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进)
自动驾驶方向课程:
[1] 深度剖析面向自动驾驶领域的车载传感器空间同步(标定)
[2] 国内首个面向自动驾驶目标检测领域的Transformer原理与实战课程
[4]面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
[5]如何将深度学习模型部署到实际工程中?(分类+检测+分割)