点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
从单目序列图像进行场景三维重建是一个很具有挑战性的任务,最近有很多volume-based方法学习直接预测TSDF volume来实现三维重建,展现了非常不错的结果,相比于之前的depth-based方法可以重建出更加完整、一致、连贯的场景几何。然而,大多数这类方法都是在研究如何提取2D特征、如何融合2D特征形成3D特征体(feature volume),但它们的3D特征的聚合方式还是一直沿用了3D CNN,没有任何改变。
在这项工作中,我们认为对于三维重建这个任务来说,三维特征的聚合是很重要的事情,所以我们提出了一个新的三维特征聚合方式——3D Transformer。就像2D CNN到3D CNN的转变一样,我们将2D Transformer升格到3D,用来处理3D特征。这个事情之所以之前没有人做,是因为3D Attention巨大的计算量,为了减少计算复杂度,我们提出了一个稀疏窗口注意力模块,从而只在局部窗口内的非空体素之间计算注意力。然后我们构建了一个自上而下-自下而上的3D Transformer网络用于3D特征聚合,其中的膨胀-注意力结构用来防止几何退化,两个全局模块用来增加全局感受野。在多个数据集上的实验表明,这个3D Transformer网络生成了更准确、更完整的三维几何重建,相比之前的方法有明显的提升。尤其是,在ScanNet数据集上,重建精度提高了41.8%,重建完整度提高了25.3%。
3D-Former: Monocular Scene Reconstruction with SDF 3D Transformers
Weihao Yuan, Xiaodong Gu, Heng Li, Zilong Dong, Siyu Zhu
主页:https://weihaosky.github.io/former3d/
论文:https://arxiv.org/abs/2301.13510
代码链接:
https://github.com/alibaba-damo-academy/former3d
一、Introduction
单目三维重建是计算机视觉中的经典任务,对于自主导航、机器人和增强/虚拟现实等众多应用至关重要。这个视觉任务旨在仅利用一系列单目RGB图像,从一个不规则场景中重建一个精确和完整的三维几何形状。目前,摄像机姿态可以通过SLAM或SfM系统比较准确地估计得到,然而从这些已有位姿的图像中恢复场景三维几何仍然是一个具有挑战性的问题,因为一个大场景环境是很复杂的,如各种物体、多样的光照、反光表面,还有不同焦距、畸变和传感器噪声的多样摄像机。许多先前的方法采用多视角深度估计(MVS)来重建场景,他们预测每一帧图像的稠密深度图,这种depth-based方法可以估计准确的局部几何形状,但需要额外的步骤来融合这些深度图,例如解决不同视角之间的不一致性,这是比较困难的。
最近,一些方法尝试直接从截断有符号距离函数(TSDF)表示中回归完整场景的完整3D表面。他们首先使用2D卷积神经网络(CNN)提取2D特征,然后将这些特征反投影到3D空间。之后,3D feature volume由3D CNN网络处理,输出一个TSDF volume预测,该预测经过marching cubes就可以提取到mesh。这种重建方式是端到端可训练的,已经证明了能够输出准确、连贯和完整的网格。在本文中,我们沿着这种volume-based三维重建路径,直接回归TSDF volume。
然而,之前的volume-based方法都是在研究如何提取2D特征、如何融合2D特征形成3D feature volume,但它们的3D特征的聚合方式还是一直沿用了3D CNN,没有任何改变。有些方法使用了2D Transformer在进行2D特征的处理,但是都没有人使用3D Transformer来做3D特征的处理,这是因为3D multi-head attention的计算量是爆炸的,每个voxel直接都需要计算attention,在现有硬件下这几乎是不可实现。
在本文中,为了解决这个问题,使3D Transformer在三维重建中成为可能,我们提出了一个sparse window multi-head attention的模块,并在此之上构建了第一个top-down-bottom-up的3D Transformer网络。
二、Methodology
1. 整体结构
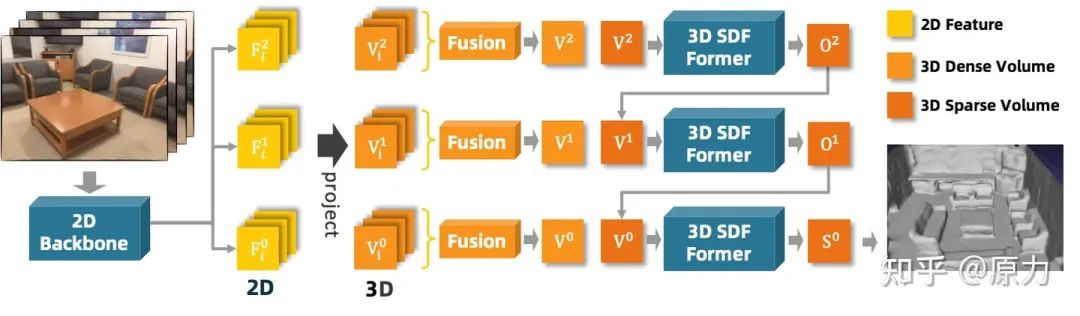
我们进行三维重建的整体框架如图1所示。给定一个场景的图像序列和相应的相机内参和外参,我们首先在三个尺度上,提取2D空间中的图像特征,然后将这些2D特征反投影到3D空间中,并分别融合到粗、中、细三个特征体中。然后,这三个特征体按照粗到细的顺序被我们的SDF 3D Transformer聚合。在粗和中尺度上,3D Transforme的输出是两个占用体(occupancy volume)预测O1、O2,用于将更精细层的volume稀疏化,而在细尺度上,输出是预测的TSDF volume。这样以来,特征体可以被稀疏地处理以减少计算复杂度。最后,从TSDF volume中可以使用Marching Cubes来提取预测的网格mesh。
2. 三维特征构建
与之前的方法类似, 我们使用了加权平均的方式融合不同视角投影得到的3D特征。与之前不同的是,我们在计算加权权重时加入了每个视角的variance,并且在最终融合的feature volume中加入了total variance,因为我们认为每个视角的variance反映了对最终融合的应有贡献度,比方说与整体平均差很多的值很可能是outlier。具体细节和计算公式可以查看论文。
3. 稀疏窗口多头注意力

多头注意力结构已被证明在许多视觉任务中很有效。然而,大多数任务仅限于2D特征处理,而非3D特征处理。这是因为多头注意力的计算复杂度通常比卷积网络高,而这个问题在3D特征中被进一步扩大。要计算一个3D feature volume的注意力,需要计算每一个体素和任何其他体素之间的注意力,即一个体素需要计算N_X×N_Y×N_Z个注意力,而所有体素需要计算N_X×N_Y×N_Z×N_X×N_Y×N_Z个注意力,这是非常大的,很难在常规GPU中实现。
为了解决这个问题,使得3D特征的多头注意力成为可能,我们提出使用稀疏窗口结构来计算注意力。如图1所示,在中等和精细级别上,我们使用占用预测O2、O1来稀疏化体积,并仅计算非空体素的注意力。此外,考虑到附近的体素对当前体素的形状贡献更大,而远处的体素贡献较少,我们仅计算每个体素局部窗口内的注意力,如图2所示。因此,我们只计算小窗口内非空体素的多头注意力,从而显著减少了计算复杂度。

4. SDF 3D Transformer
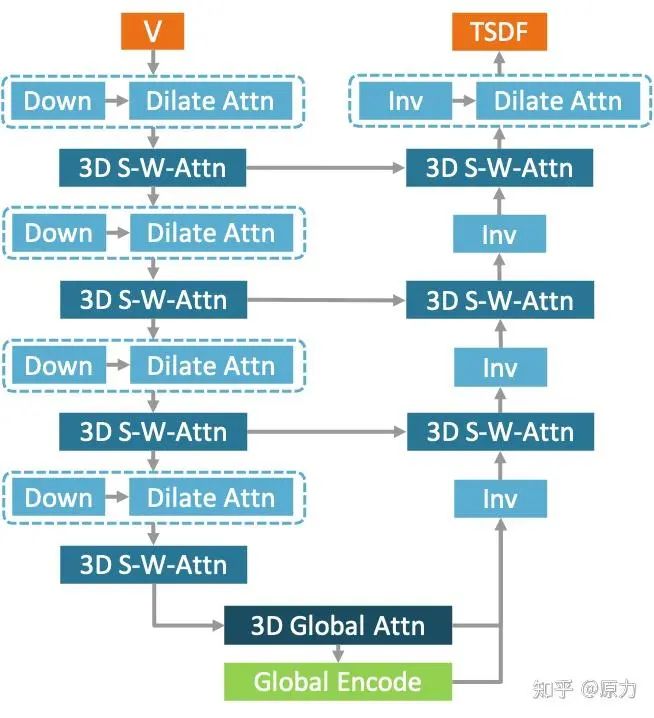
由于多头注意力的高资源消耗限制,大多数之前与3D Transformer相关的工作仅小心翼翼地进行了省资源的特征处理,基本没有下采样和上采样。然而,在3D重建中,自上而下自下而上的结构对于特征提取和预测生成更为合理,就像大多数基于3D CNN的结构一样。因此,在本文中,我们设计了第一个基于3D Transformer的自上而下自下而上结构,如图3所示。
以图1中的fine volume(V0)为例,总共有四个特征尺度层级,即1/2、1/4、1/8、1/16,如图3所示。在编码器部分,每个层级采用下采样和膨胀注意力的组合来下采样特征体积。然后使用两个稀疏窗口多头注意力模块来聚合特feature volume。在底层,采用全局注意力模块来补偿窗口注意力的局部感受野,并使用全局上下文编码模块提取全局信息。在解码器部分,使用逆稀疏3D CNN来上采样特征体积。因此,上采样后的最终形状应与输入相同。与FPN类似,下采样中的特征也添加到相应级别的上采样特征中。为了给网络增加变形能力,在上采样完成之后设置了一个后膨胀注意力块。最后,附加了一个带有Tanh激活的子流形3D CNN头来输出TSDF预测。
对于膨胀-注意力模块、全局注意力模块、全局上下文编码模块的详细介绍可以查看论文。
三、Experiments
1. 在ScanNet上的结果
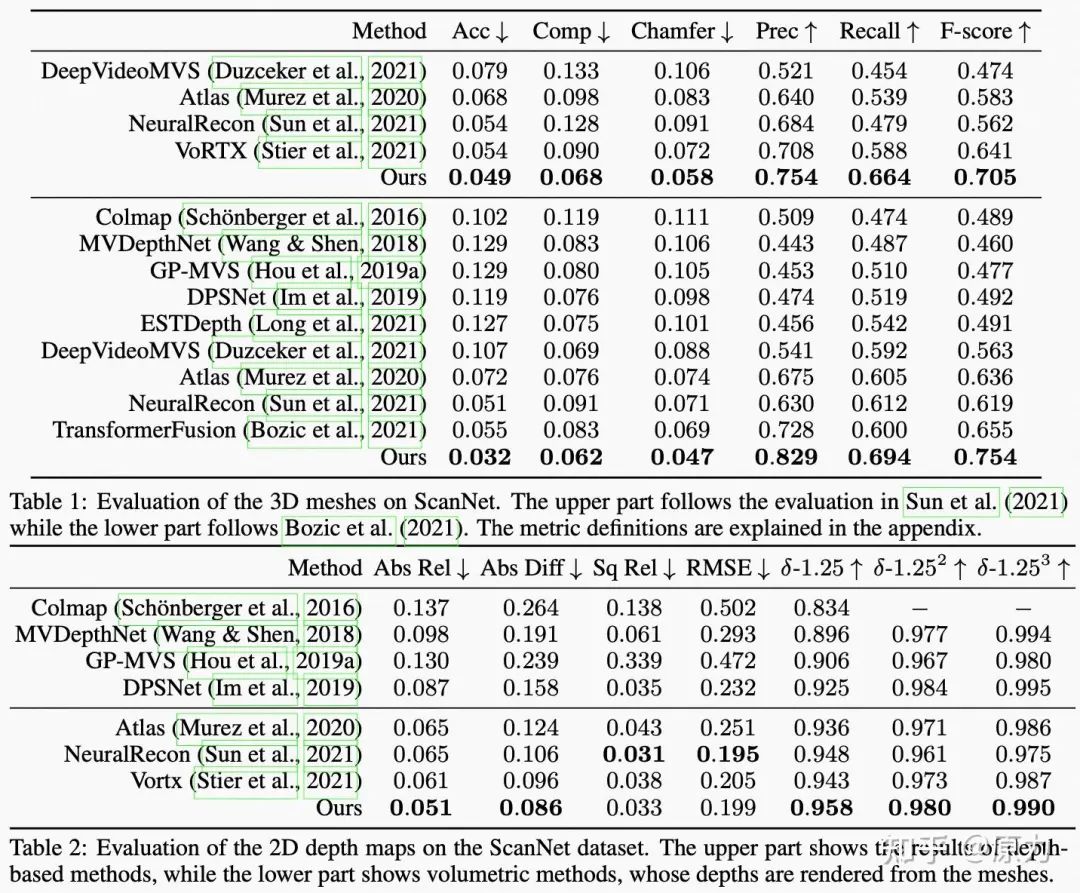
我们在ScanNet上取得了不错的结果,比之前方法有比较明显的提升,其中,相比之前最好的方法重建精度提高了41.8%、重建完整度提高了25.3%。
2. 可视化结果


最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
3D重建交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-3D重建 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如3D重建+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()