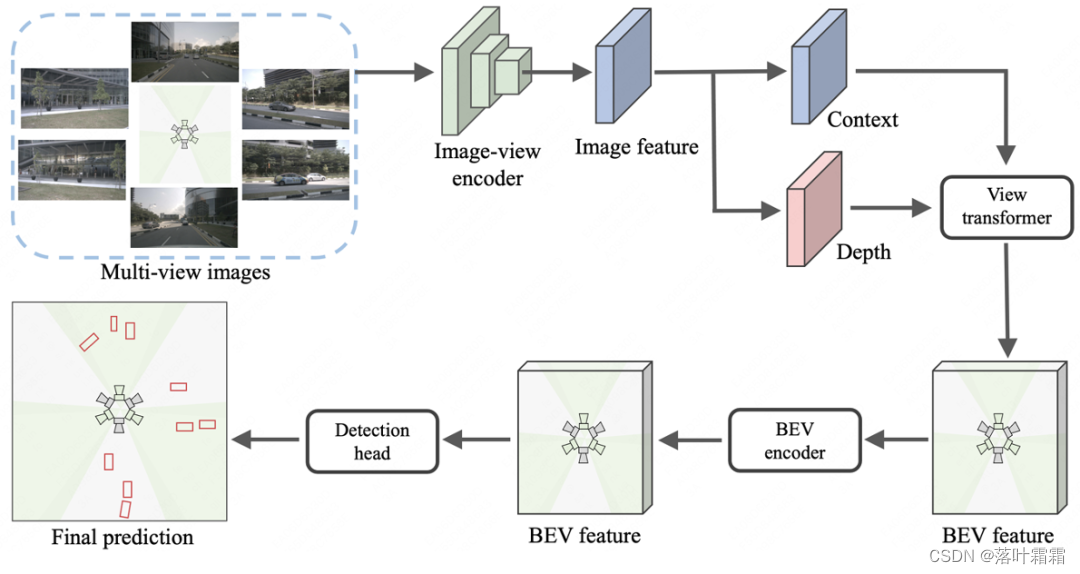
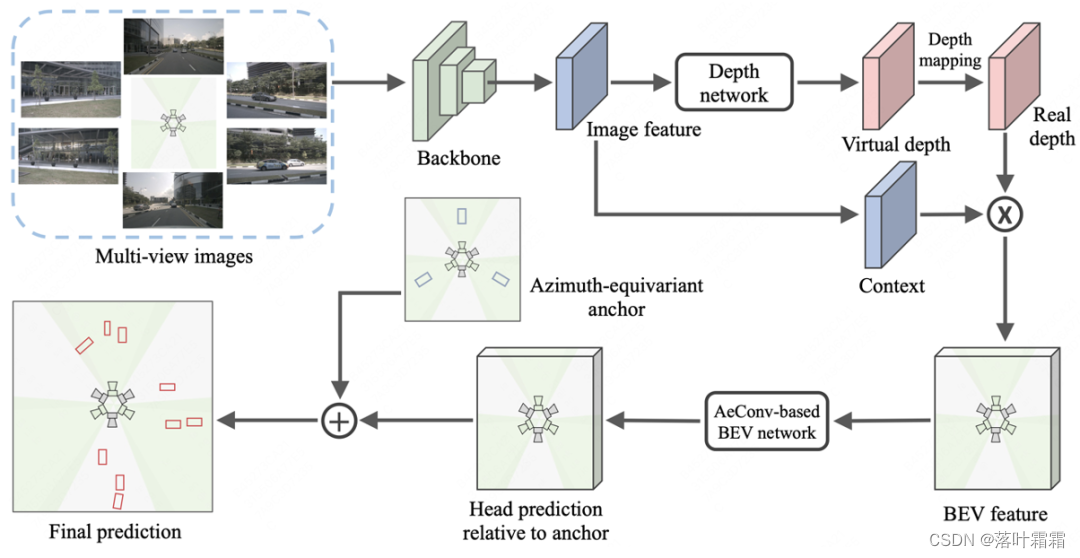
整体架构流程
论文地址:https://openaccess.thecvf.com/content/CVPR2023/papers/Feng_AeDet_Azimuth-Invariant_Multi-View_3D_Object_Detection_CVPR_2023_paper.pdf
主页:https://fcjian.github.io/aedet
代码:https://github.com/fcjian/AeDet
本文介绍了一种名为AeDet的方位角等变检测器,它能够实现多视图3D目标检测的方位不变性。如下图所示,假设不同方位的摄像机在不同时刻捕获到相同的场景,现有方法(以BEVDepth为例)在不同方位下对相同的公交车产生不同的BEV特征和预测结果,而AeDet则在不同方位下对相同的公交车产生几乎相同的BEV特征和预测结果。

问题
目前基于Lift-Splat-Shoot(LSS)的多视图3D目标检测器(例如BEVDepth)通常由图像编码器(Image-view encoder)、视角转换器(View transformer)、BEV编码器(BEV encoder)和检测头(Detection head)组成。
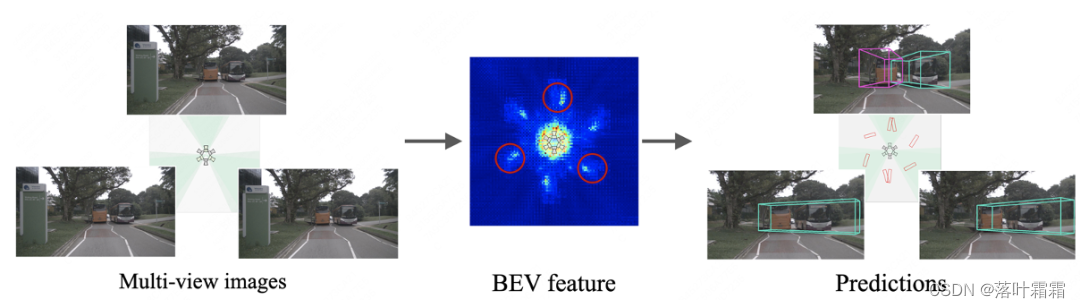
我们进行了一项基于BEVDepth的简单实验。我们假设不同方位的摄像机在不同时刻捕获到相同的场景,并将相同的图像作为6个视图的输入(为了简明起见,本文仅展示了3个视图)。令人惊讶的是,BEVDepth在不同方位下对相同物体(即下图中的公交车)生成了不同的BEV特征和检测结果。
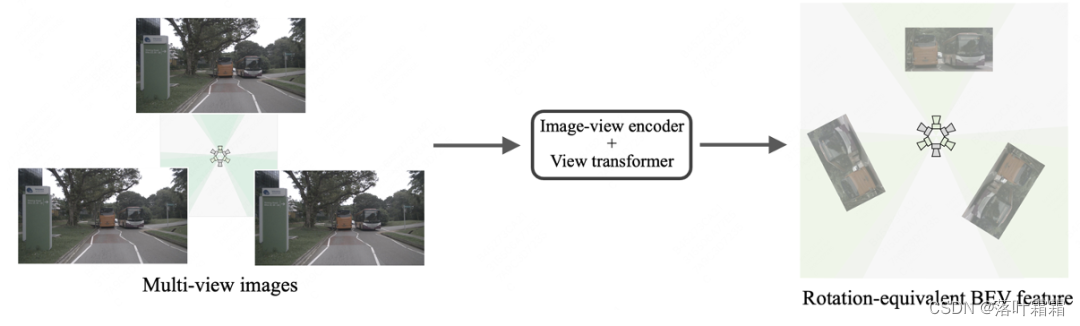
我们将逐个模块分析导致上述结果的原因。图像编码器和视角转换器会分别处理不同方位的图像,因此可以将图像转换为具有旋转等变性的BEV特征(即径向对称性),如下图所示:
然而,BEV编码器和检测头使用传统的卷积和无锚检测头来进行BEV感知。这种设计忽略了BEV特征的径向对称性,导致在不同方位下对相同的物体产生不同的特征和预测。
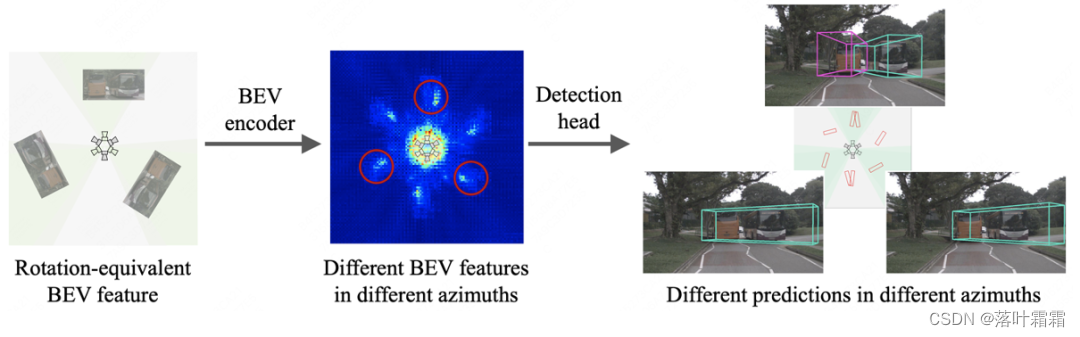
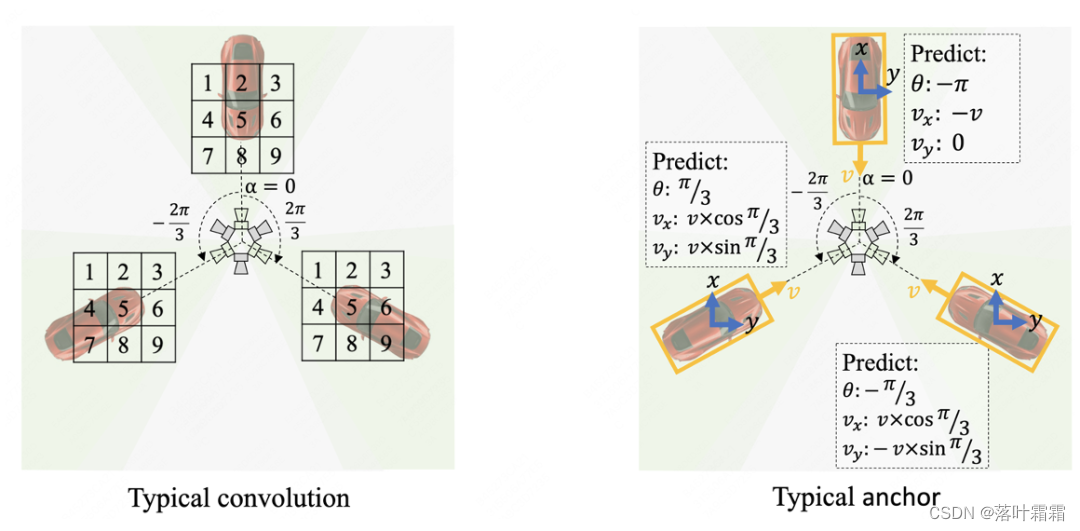
更具体地说,传统的卷积编码器和无锚检测头在BEV感知中存在以下两个问题:
1)如下方左图所示,传统的卷积编码器在特征的每个位置使用相同的采样网格,因此对于旋转等变的BEV特征,它在不同的方位下会采样和生成不同的BEV特征。
2)如下方右图所示,传统的检测头沿着笛卡尔坐标系的方向(蓝色箭头)预测物体的方向和速度,这导致检测头需要针对不同方位的相同物体预测不同的目标。
方法
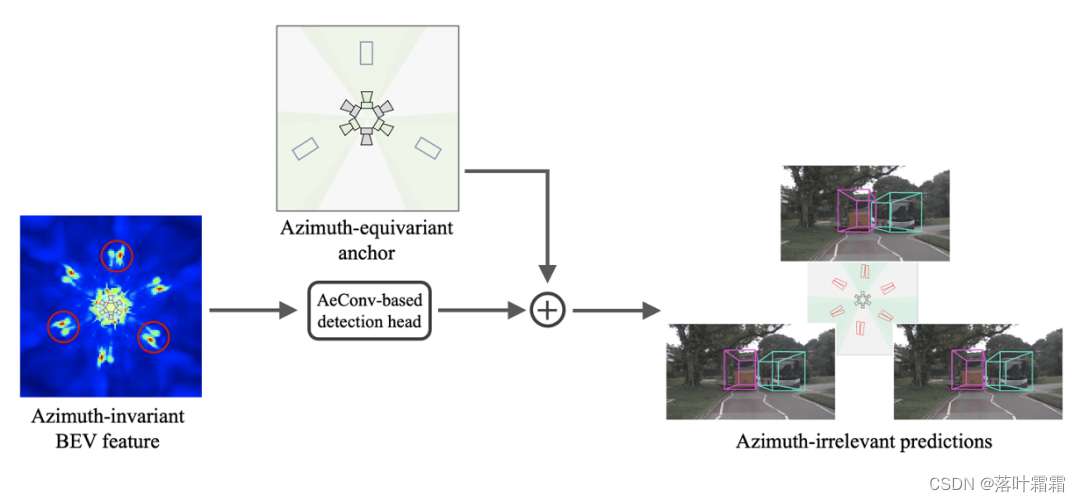
本文提出了一个名为AeDet的方位等变的多视图3D目标检测器,旨在统一不同方位下的BEV感知(即表示学习和预测),从而提高检测性能。该方法通过图像编码器和视角转换器处理多视角图像,生成具有径向对称性的BEV特征。随后,利用基于方位角等变卷积(AeConv)的BEV网络进一步编码方位不变的BEV特征,并基于方位角等变锚来预测方位不变的检测结果,具体结构如下方所示:
2.1 学习方位不变的BEV特征
在学习方位不变的BEV特征方面,本文提出了一种名为方位角等变卷积(AeConv)的方法。AeConv旨在统一对不同方位的BEV特征学习,提取沿相机径向的BEV表示。具体而言,根据每个位置的方位角,我们将传统卷积的规则采样网格相应地旋转,并基于旋转后的采样网格进行卷积运算,如下方所示:
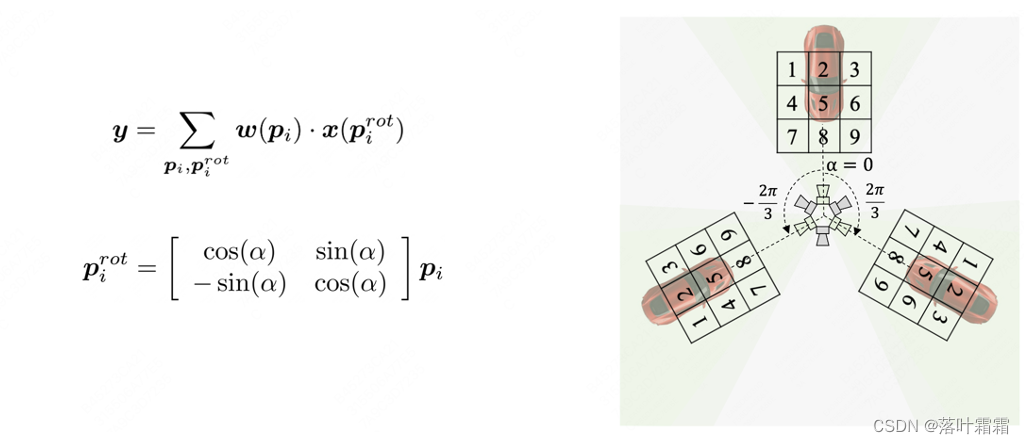
需要注意的是,AeConv方法中旋转的采样网格始终是沿着相机径向的(如上图所示)。因此,无论在不同的方位下,AeConv都能够采样和学习相同的BEV特征,即具有方位角不变性的表示。我们使用AeConv代替传统的卷积操作,并构建了基于AeConv的BEV网络,以进一步编码方位不变的BEV特征。这种方法可以提高多视角3D目标检测的准确性和鲁棒性。
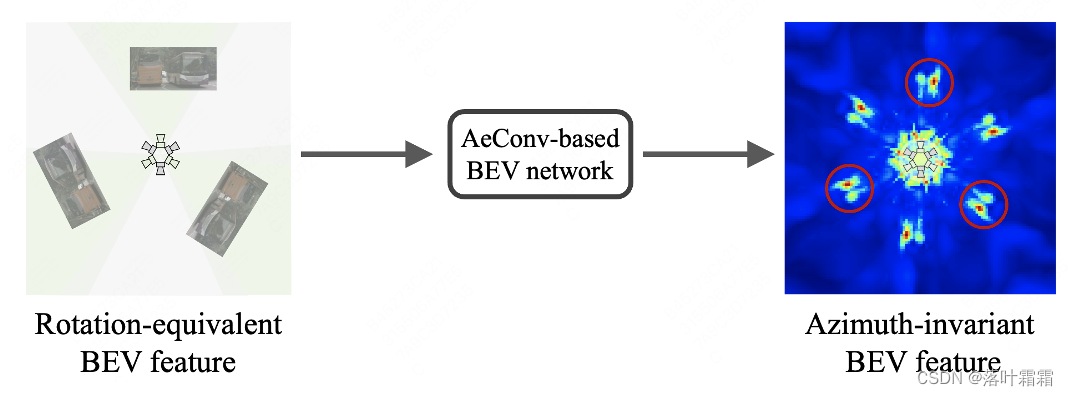
2.2 预测方位不变的目标
方位角等变锚:我们根据每个位置的方位角重新定义了方位角等变锚;然后根据方位角等变锚的方向(蓝色箭头)计算检测框和速度的残差,得到与方位无关的预测目标:
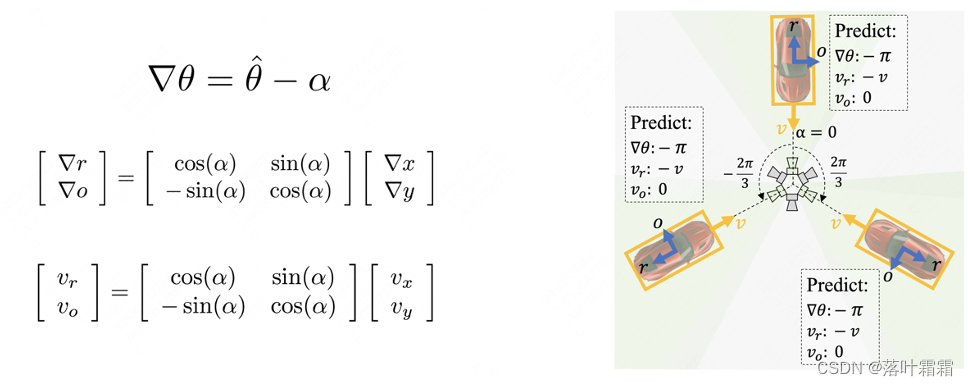
值得注意的是,方位角等变锚的方向总是在相机的径向上。因此,检测头可以根据方位等变的方向来预测目标的朝向、中心偏移量和速度,从而得到与方位无关的预测目标和结果:
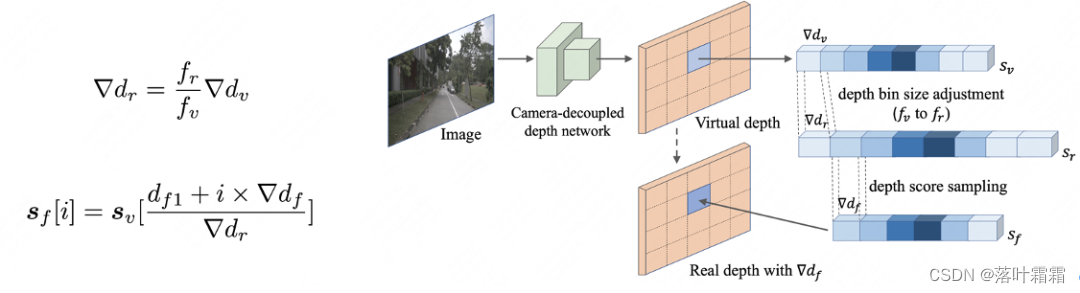
2.3 相机解耦的虚拟深度是一种新的深度预测方法,它具有相机内参无关性,可以对具有不同相机内参的图像进行统一的深度预测。具体实现方法是,首先使用相机解耦的深度网络来预测以虚拟焦距为基准的虚拟深度。然后,根据经典的摄像机模型,将虚拟深度转换为真实深度,使得预测的深度能够适配到不同的相机内参和视角下。这种方法可以有效地提高深度预测的鲁棒性和泛化能力。
实验
3.1 与SOTA比较
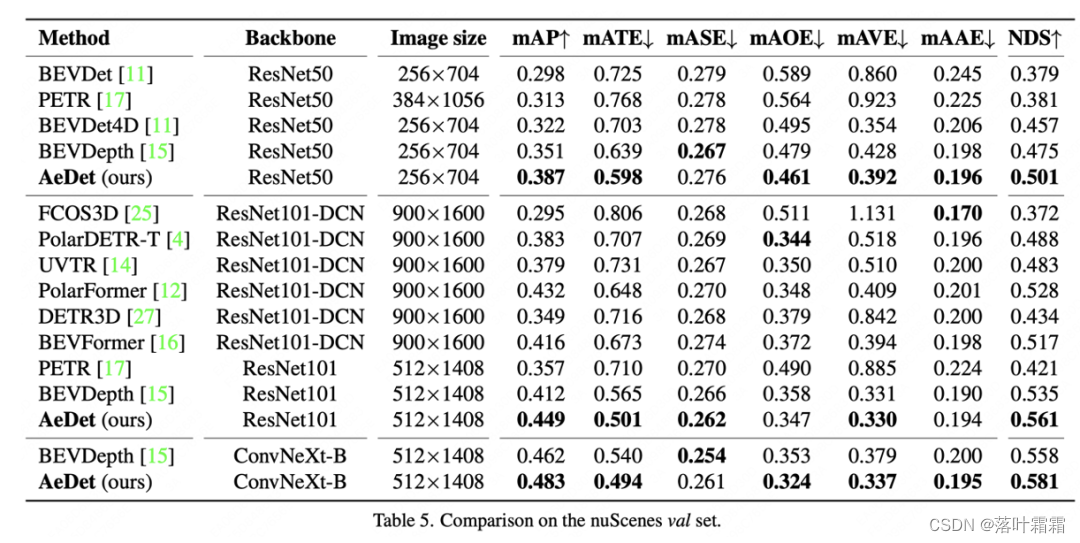
在nuScenes验证集上的比较中,AeDet使用ResNet-50和ResNet-101分别实现了50.1%的NDS和56.1%的NDS,在性能上超过了当前的多视图3D目标检测器,如BEVFormer(超过4.4%)和BEVDepth(超过2.6%)。
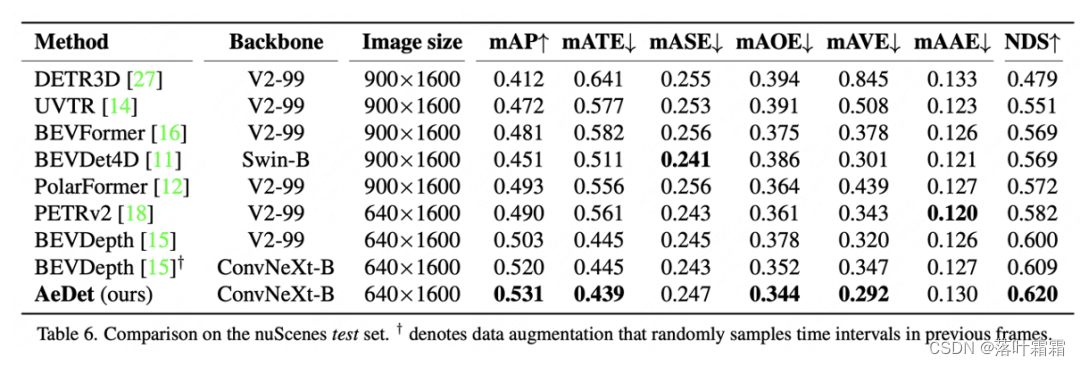
在nuScenes测试集上的比较中,AeDet将mAOE和mAVE分别提高了3.4%和2.8%,并以53.1%的mAP和62.0%的NDS在多视图3D目标检测方面取得了最新的先进结果。
3.2 消融实验
与基准BEVDepth相比,AeNet(方位角等变卷积和方位角等变锚)在参数数量相同的情况下,仅增加了1.7%的FLOPs,将NDS提高了2个百分点(从44.2%增加到46.2%)。此外,相机解耦的深度网络(CDN)可提高1.5%的mAP和1.2%的NDS。

3.3 旋转测试
不同方位的检测鲁棒性对于自动驾驶系统非常重要,因为车辆有时可能会进行大角度转弯。例如,在小型环形交叉路口或拐角处,车辆的转向角度变大,导致摄像头方向发生巨大变化。自动驾驶车辆在不同的朝向下都应当保持准确的检测性能。为验证检测器的鲁棒性,我们提出了旋转测试来模拟这种情形:我们将车辆顺时针旋转60度,获取旋转视图,并在该视图中评估检测器。如下表/图所示,在旋转视图下,BEVDepth产生了与原始视图不同的预测结果,其性能下降了4.6% NDS,而AeDet在原始视图和旋转视图中产生几乎相同的预测结果。


小结
总结起来,本文提出了一种名为AeDet的检测器,旨在实现方位不变的多视图3D目标检测。它采用了方位角等变卷积(AeConv)和方位角等变锚等多种创新技术,以实现方位不变的BEV感知,并通过相机解耦的虚拟深度来统一不同相机的深度预测。在nuScenes数据集上,AeDet取得了显著的性能提升,达到了62.0% NDS,超越了现有方法,在物体的方向和速度预测方面表现出卓越的改进。这项工作强调了方位角等变卷积和方位角等变锚在提高3D目标检测性能上的有效性,尤其是在多相机视图下。